 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLOD: Awareness of Extrinsic Perturbation in Multi-LiDAR 3D Object Detection for Autonomous Driving
Sep 29, 2020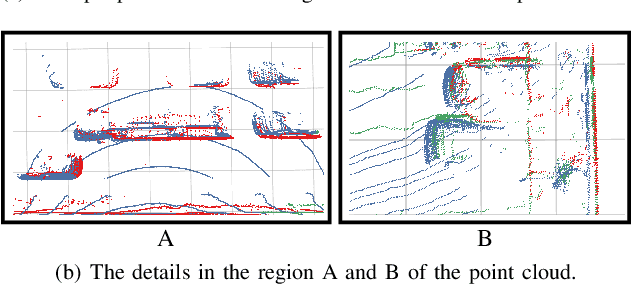
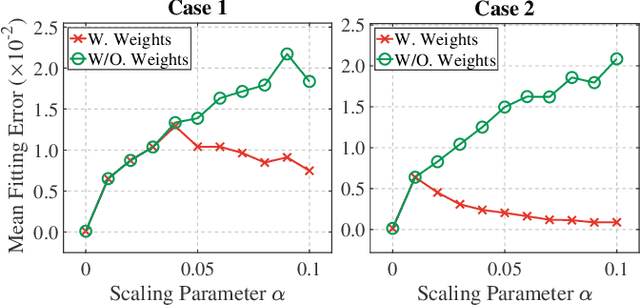
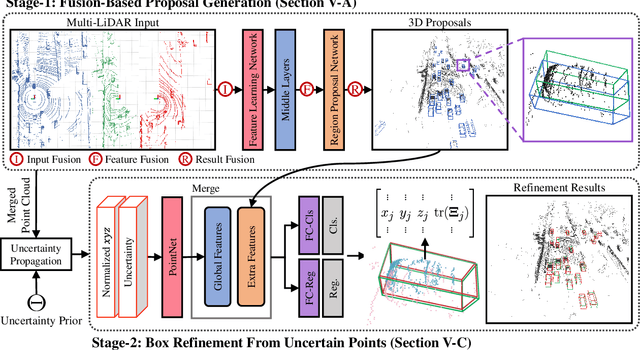
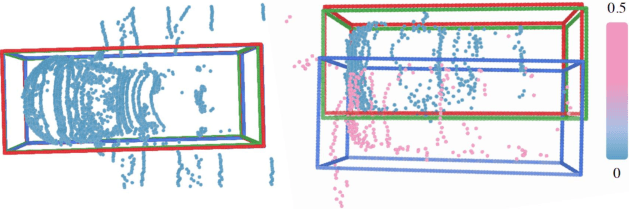
Extrinsic perturbation always exists in multiple sensors. In this paper, we focus on the extrinsic uncertainty in multi-LiDAR systems for 3D object detection. We first analyze the influence of extrinsic perturbation on geometric tasks with two basic examples. To minimize the detrimental effect of extrinsic perturbation, we propagate an uncertainty prior on each point of input point clouds, and use this information to boost an approach for 3D geometric tasks. Then we extend our findings to propose a multi-LiDAR 3D object detector called MLOD. MLOD is a two-stage network where the multi-LiDAR information is fused through various schemes in stage one, and the extrinsic perturbation is handled in stage two. We conduct extensive experiments on a real-world dataset, and demonstrate both the accuracy and robustness improvement of MLOD. The code, data and supplementary materials are available at: https://ram-lab.com/file/site/mlod
* 8 pages, 6 figures
MonoPair: Monocular 3D Object Detection Using Pairwise Spatial Relationships
Mar 01, 2020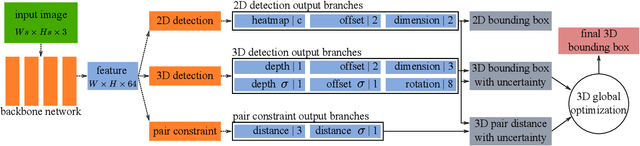
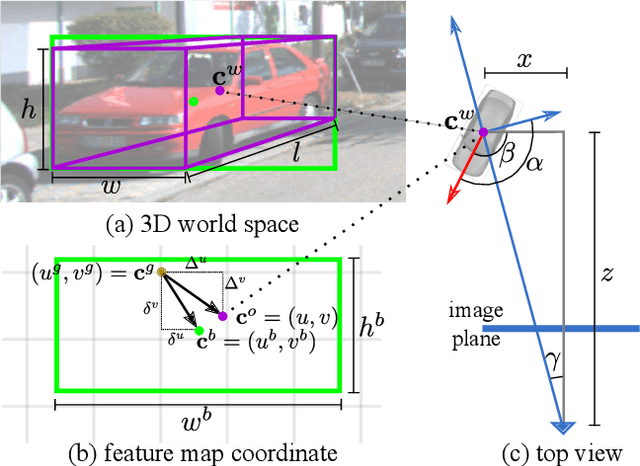
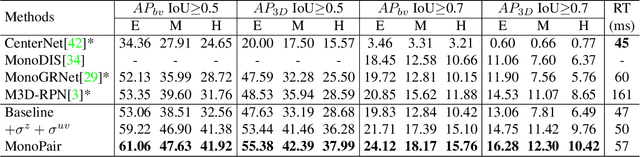
Monocular 3D object detection is an essential component in autonomous driving while challenging to solve, especially for those occluded samples which are only partially visible. Most detectors consider each 3D object as an independent training target, inevitably resulting in a lack of useful information for occluded samples. To this end, we propose a novel method to improve the monocular 3D object detection by considering the relationship of paired samples. This allows us to encode spatial constraints for partially-occluded objects from their adjacent neighbors. Specifically, the proposed detector computes uncertainty-aware predictions for object locations and 3D distances for the adjacent object pairs, which are subsequently jointly optimized by nonlinear least squares. Finally, the one-stage uncertainty-aware prediction structure and the post-optimization module are dedicatedly integrated for ensuring the run-time efficiency. Experiments demonstrate that our method yields the best performance on KITTI 3D detection benchmark, by outperforming state-of-the-art competitors by wide margins, especially for the hard samples.
High-speed Autonomous Drifting with Deep Reinforcement Learning
Jan 06, 2020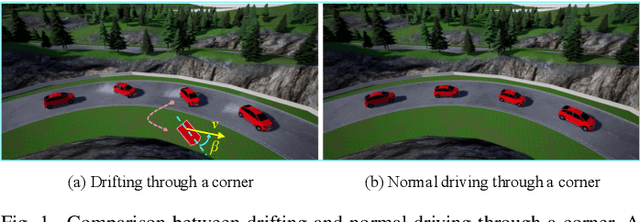



Drifting is a complicated task for autonomous vehicle control. Most traditional methods in this area are based on motion equations derived by the understanding of vehicle dynamics, which is difficult to be modeled precisely. We propose a robust drift controller without explicit motion equations, which is based on the latest model-free deep reinforcement learning algorithm soft actor-critic. The drift control problem is formulated as a trajectory following task, where the errorbased state and reward are designed. After being trained on tracks with different levels of difficulty, our controller is capable of making the vehicle drift through various sharp corners quickly and stably in the unseen map. The proposed controller is further shown to have excellent generalization ability, which can directly handle unseen vehicle types with different physical properties, such as mass, tire friction, etc.
Utilizing Eye Gaze to Enhance the Generalization of Imitation Networks to Unseen Environments
Aug 27, 2019
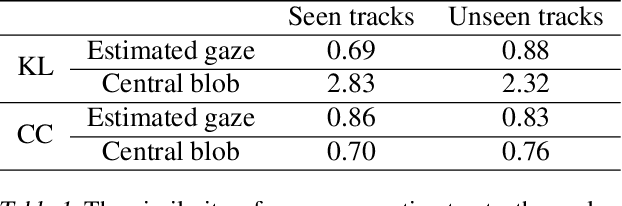
Vision-based autonomous driving through imitation learning mimics the behaviors of human drivers by training on pairs of data of raw driver-view images and actions. However, there are other cues, e.g. gaze behavior, available from human drivers that have yet to be exploited. Previous research has shown that novice human learners can benefit from observing experts' gaze patterns. We show here that deep neural networks can also benefit from this. We demonstrate different approaches to integrating gaze information into imitation networks. Our results show that the integration of gaze information improves the generalization performance of networks to unseen environments.
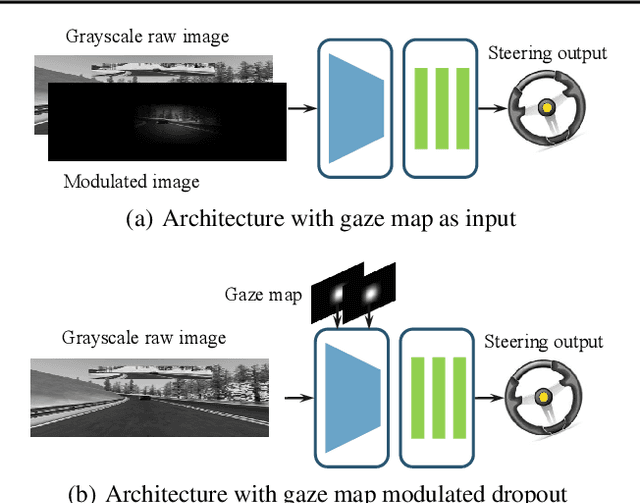
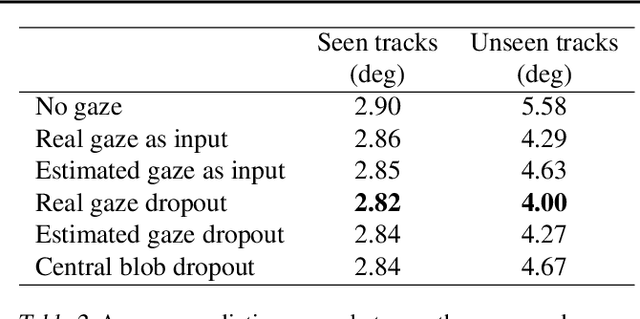
Gaze Training by Modulated Dropout Improves Imitation Learning
Apr 17, 2019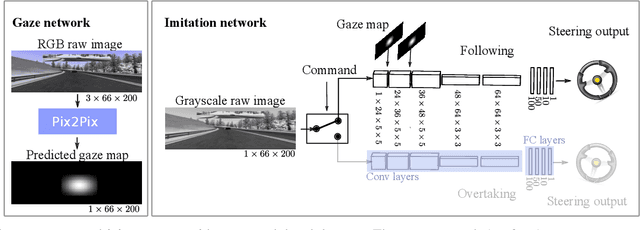
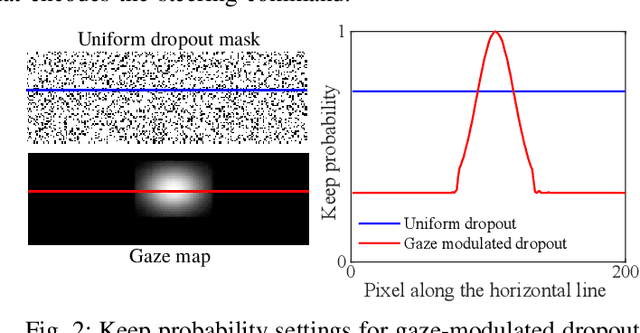
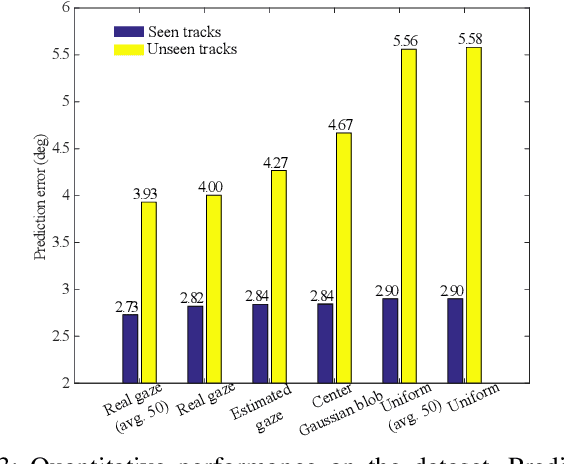
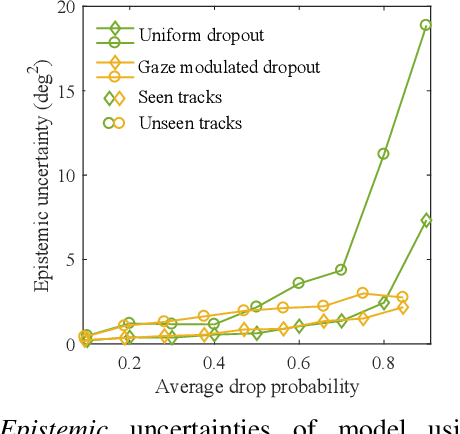
Imitation learning by behavioral cloning is a prevalent method which has achieved some success in vision-based autonomous driving. The basic idea behind behavioral cloning is to have the neural network learn from observing a human expert's behavior. Typically, a convolutional neural network learns to predict the steering commands from raw driver-view images by mimicking the behaviors of human drivers. However, there are other cues, e.g. gaze behavior, available from human drivers that have yet to be exploited. Previous researches have shown that novice human learners can benefit from observing experts' gaze patterns. We present here that deep neural networks can also profit from this. We propose a method, gaze-modulated dropout, for integrating this gaze information into a deep driving network implicitly rather than as an additional input. Our experimental results demonstrate that gaze-modulated dropout enhances the generalization capability of the network to unseen scenes. Prediction error in steering commands is reduced by 23.5% compared to uniform dropout. Running closed loop in the simulator, the gaze-modulated dropout net increased the average distance travelled between infractions by 58.5%. Consistent with these results, we also found the gaze-modulated dropout net to have lower model uncertainty.
Fully Using Classifiers for Weakly Supervised Semantic Segmentation with Modified Cues
Apr 03, 2019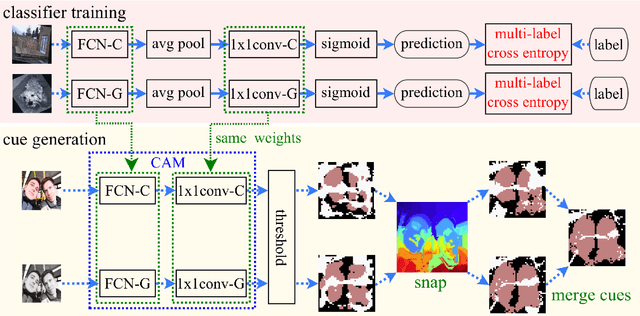
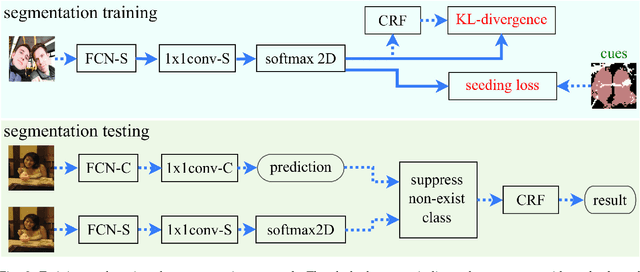
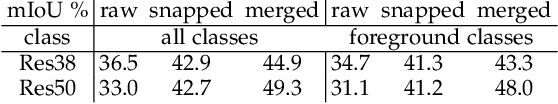
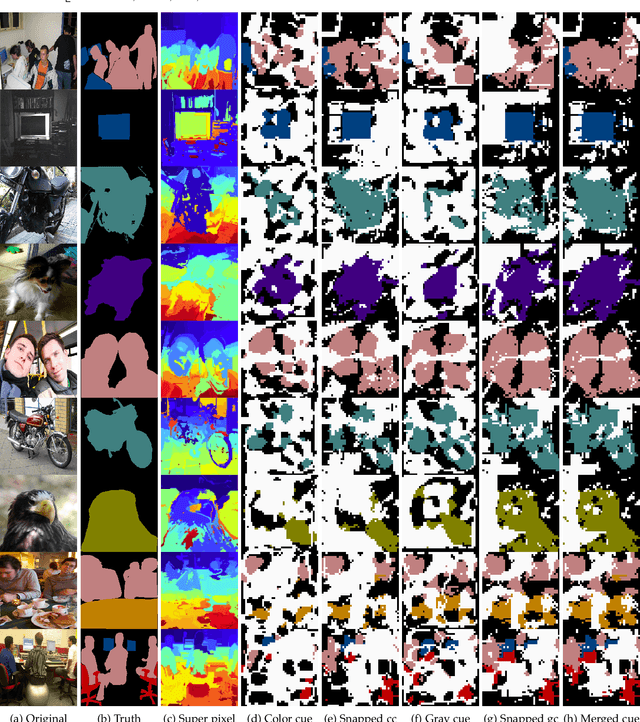
This paper proposes a novel weakly-supervised semantic segmentation method using image-level label only. The class-specific activation maps from the well-trained classifiers are used as cues to train a segmentation network. The well-known defects of these cues are coarseness and incompleteness. We use super-pixel to refine them, and fuse the cues extracted from both a color image trained classifier and a gray image trained classifier to compensate for their incompleteness. The conditional random field is adapted to regulate the training process and to refine the outputs further. Besides initializing the segmentation network, the previously trained classifier is also used in the testing phase to suppress the non-existing classes. Experimental results on the PASCAL VOC 2012 dataset illustrate the effectiveness of our method.
End-to-end Driving Deploying through Uncertainty-Aware Imitation Learning and Stochastic Visual Domain Adaptation
Mar 03, 2019

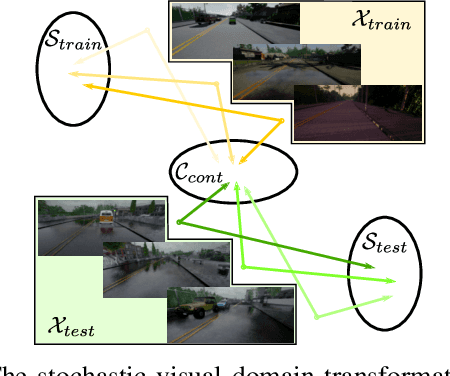

End-to-end visual-based imitation learning has been widely applied in autonomous driving. When deploying the trained visual-based driving policy, a deterministic command is usually directly applied without considering the uncertainty of the input data. Such kind of policies may bring dramatical damage when applied in the real world. In this paper, we follow the recent real-to-sim pipeline by translating the testing world image back to the training domain when using the trained policy. In the translating process, a stochastic generator is used to generate various images stylized under the training domain randomly or directionally. Based on those translated images, the trained uncertainty-aware imitation learning policy would output both the predicted action and the data uncertainty motivated by the aleatoric loss function. Through the uncertainty-aware imitation learning policy, we can easily choose the safest one with the lowest uncertainty among the generated images. Experiments in the Carla navigation benchmark show that our strategy outperforms previous methods, especially in dynamic environments.
VR-Goggles for Robots: Real-to-sim Domain Adaptation for Visual Control
Jan 16, 2019



In this paper, we deal with the reality gap from a novel perspective, targeting transferring Deep Reinforcement Learning (DRL) policies learned in simulated environments to the real-world domain for visual control tasks. Instead of adopting the common solutions to the problem by increasing the visual fidelity of synthetic images output from simulators during the training phase, we seek to tackle the problem by translating the real-world image streams back to the synthetic domain during the deployment phase, to make the robot feel at home. We propose this as a lightweight, flexible, and efficient solution for visual control, as 1) no extra transfer steps are required during the expensive training of DRL agents in simulation; 2) the trained DRL agents will not be constrained to being deployable in only one specific real-world environment; 3) the policy training and the transfer operations are decoupled, and can be conducted in parallel. Besides this, we propose a simple yet effective shift loss that is agnostic to the downstream task, to constrain the consistency between subsequent frames which is important for consistent policy outputs. We validate the shift loss for artistic style transfer for videos and domain adaptation, and validate our visual control approach in indoor and outdoor robotics experiments.
PointSeg: Real-Time Semantic Segmentation Based on 3D LiDAR Point Cloud
Sep 25, 2018
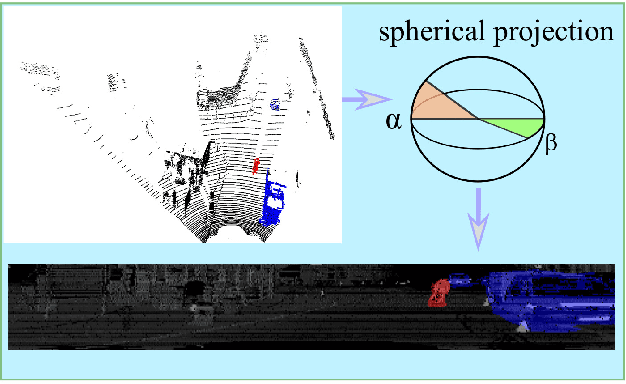
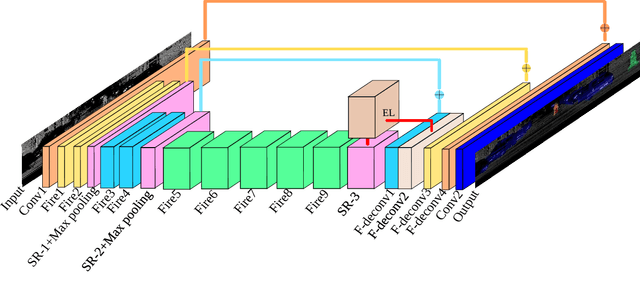
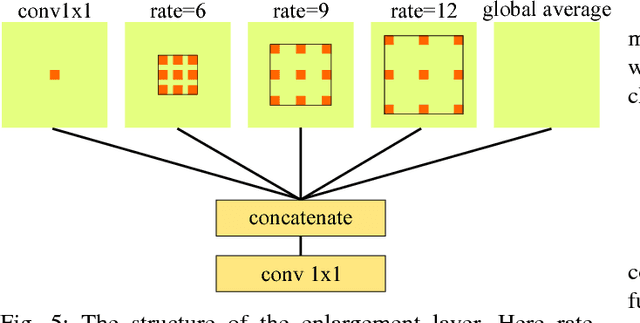
In this paper, we propose PointSeg, a real-time end-to-end semantic segmentation method for road-objects based on spherical images. We take the spherical image, which is transformed from the 3D LiDAR point clouds, as input of the convolutional neural networks (CNNs) to predict the point-wise semantic map. To make PointSeg applicable on a mobile system, we build the model based on the light-weight network, SqueezeNet, with several improvements. It maintains a good balance between memory cost and prediction performance. Our model is trained on spherical images and label masks projected from the KITTI 3D object detection dataset. Experiments show that PointSeg can achieve competitive accuracy with 90fps on a single GPU 1080ti. which makes it quite compatible for autonomous driving applications.
Focal Loss in 3D Object Detection
Sep 18, 2018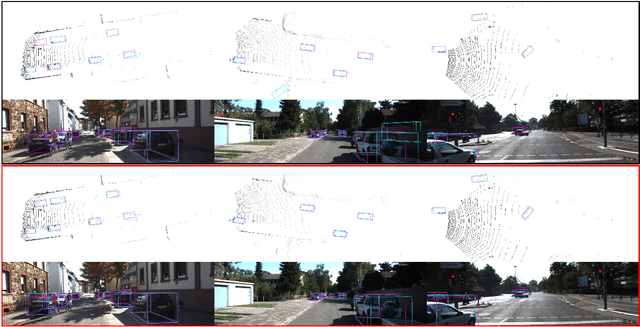


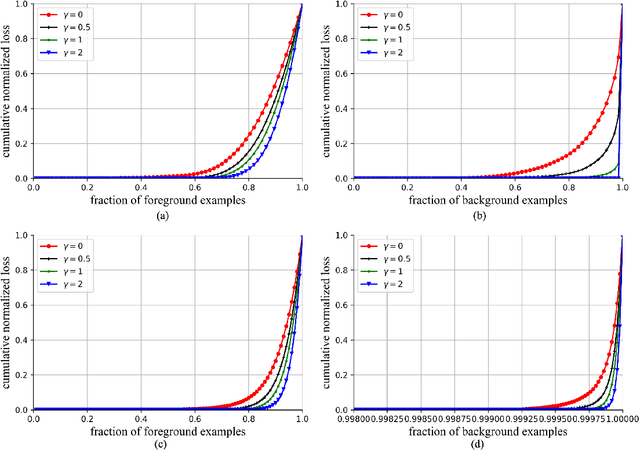
3D object detection is still an open problem in autonomous driving scenes. Robots recognize and localize key objects from sparse inputs, and suffer from a larger continuous searching space as well as serious fore-background imbalance compared to the image-based detection. In this paper, we try to solve the fore-background imbalance in the 3D object detection task. Inspired by the recent improvement of focal loss on image-based detection which is seen as a hard-mining improvement of binary cross entropy, we extend it to point-cloud-based object detection and conduct experiments to show its performance based on two different type of 3D detectors: 3D-FCN and VoxelNet. The results show up to 11.2 AP gains from focal loss in a wide range of hyperparameters in 3D object detection. Our code is available at https://github.com/pyun-ram/FL3D.