 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS2 2025 Challenge on Multimodal Reasoning: Datasets, Methods, Results, Discussion, and Outlook
Sep 17, 2025



This paper reviews the MARS2 2025 Challenge on Multimodal Reasoning. We aim to bring together different approaches in multimodal machine learning and LLMs via a large benchmark. We hope it better allows researchers to follow the state-of-the-art in this very dynamic area. Meanwhile, a growing number of testbeds have boosted the evolution of general-purpose large language models. Thus, this year's MARS2 focuses on real-world and specialized scenarios to broaden the multimodal reasoning applications of MLLMs. Our organizing team released two tailored datasets Lens and AdsQA as test sets, which support general reasoning in 12 daily scenarios and domain-specific reasoning in advertisement videos, respectively. We evaluated 40+ baselines that include both generalist MLLMs and task-specific models, and opened up three competition tracks, i.e., Visual Grounding in Real-world Scenarios (VG-RS), Visual Question Answering with Spatial Awareness (VQA-SA), and Visual Reasoning in Creative Advertisement Videos (VR-Ads). Finally, 76 teams from the renowned academic and industrial institutions have registered and 40+ valid submissions (out of 1200+) have been included in our ranking lists. Our datasets, code sets (40+ baselines and 15+ participants' methods), and rankings are publicly available on the MARS2 workshop website and our GitHub organization page https://github.com/mars2workshop/, where our updates and announcements of upcoming events will be continuously provided.
Ultra-High-Definition Dynamic Multi-Exposure Image Fusion via Infinite Pixel Learning
Dec 16, 2024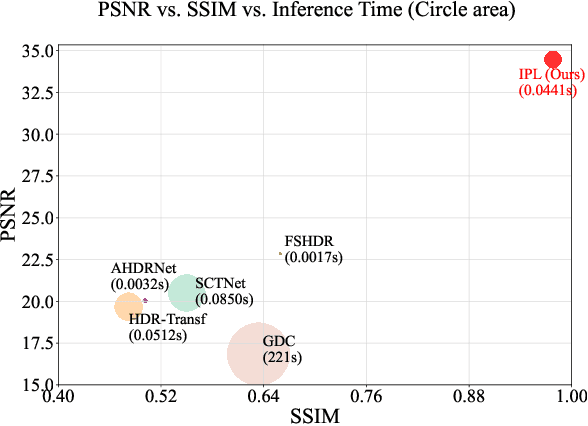
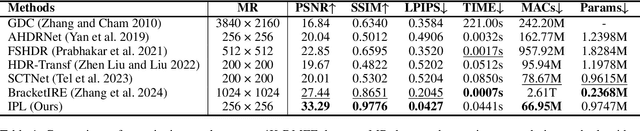
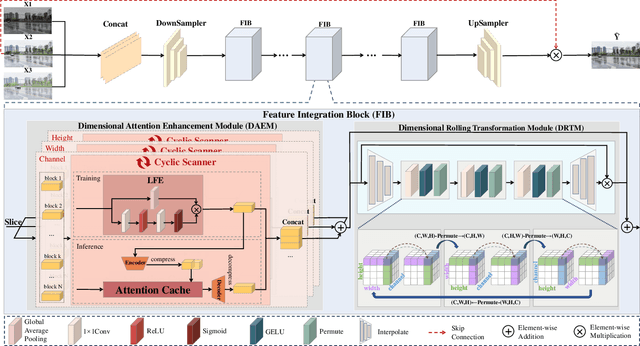
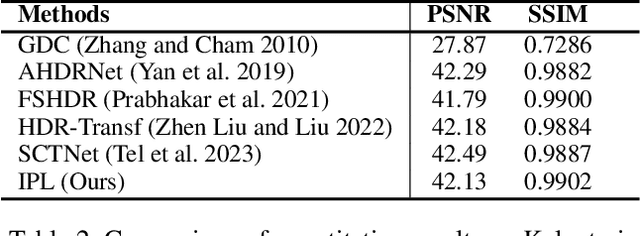
With the continuous improvement of device imaging resolution, the popularity of Ultra-High-Definition (UHD) images is increasing. Unfortunately, existing methods for fusing multi-exposure images in dynamic scenes are designed for low-resolution images, which makes them inefficient for generating high-quality UHD images on a resource-constrained device. To alleviate the limitations of extremely long-sequence inputs, inspired by the Large Language Model (LLM) for processing infinitely long texts, we propose a novel learning paradigm to achieve UHD multi-exposure dynamic scene image fusion on a single consumer-grade GPU, named Infinite Pixel Learning (IPL). The design of our approach comes from three key components: The first step is to slice the input sequences to relieve the pressure generated by the model processing the data stream; Second, we develop an attention cache technique, which is similar to KV cache for infinite data stream processing; Finally, we design a method for attention cache compression to alleviate the storage burden of the cache on the device. In addition, we provide a new UHD benchmark to evaluate the effectiveness of our method. Extensive experimental results show that our method maintains high-quality visual performance while fusing UHD dynamic multi-exposure images in real-time (>40fps) on a single consumer-grade GPU.
Motion Dreamer: Realizing Physically Coherent Video Generation through Scene-Aware Motion Reasoning
Nov 30, 2024



Recent numerous video generation models, also known as world models, have demonstrated the ability to generate plausible real-world videos. However, many studies have shown that these models often produce motion results lacking logical or physical coherence. In this paper, we revisit video generation models and find that single-stage approaches struggle to produce high-quality results while maintaining coherent motion reasoning. To address this issue, we propose \textbf{Motion Dreamer}, a two-stage video generation framework. In Stage I, the model generates an intermediate motion representation-such as a segmentation map or depth map-based on the input image and motion conditions, focusing solely on the motion itself. In Stage II, the model uses this intermediate motion representation as a condition to generate a high-detail video. By decoupling motion reasoning from high-fidelity video synthesis, our approach allows for more accurate and physically plausible motion generation. We validate the effectiveness of our approach on the Physion dataset and in autonomous driving scenarios. For example, given a single push, our model can synthesize the sequential toppling of a set of dominoes. Similarly, by varying the movements of ego-cars, our model can produce different effects on other vehicles. Our work opens new avenues in creating models that can reason about physical interactions in a more coherent and realistic manner.
Autonomous Navigation through intersections with Graph ConvolutionalNetworks and Conditional Imitation Learning for Self-driving Cars
Feb 01, 2021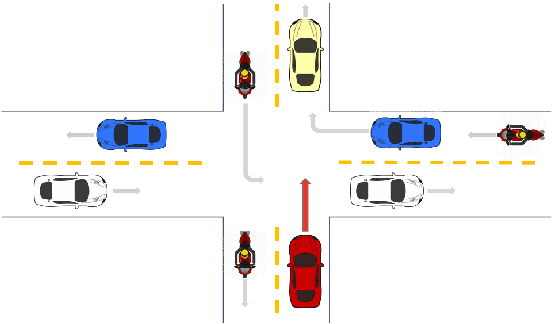
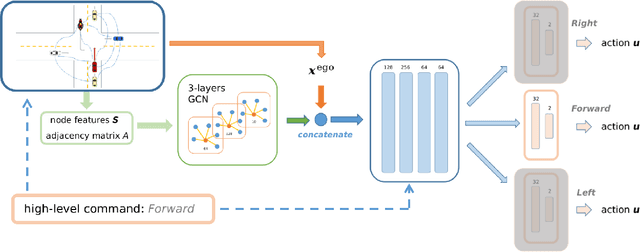
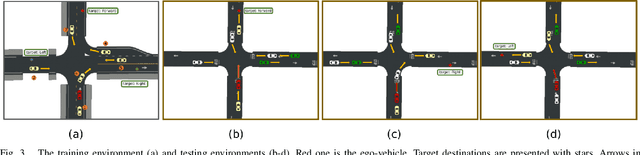
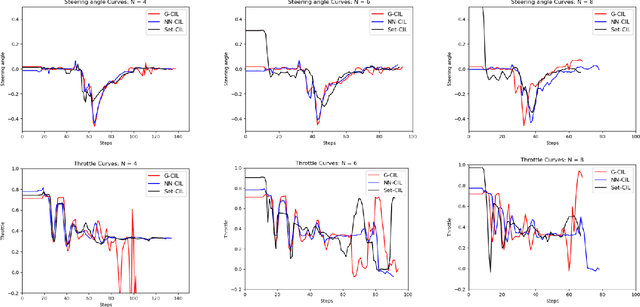
In autonomous driving, navigation through unsignaled intersections with many traffic participants moving around is a challenging task. To provide a solution to this problem, we propose a novel branched network G-CIL for the navigation policy learning. Specifically, we firstly represent such dynamic environments as graph-structured data and propose an effective strategy for edge definition to aggregate surrounding information for the ego-vehicle. Then graph convolutional neural networks are used as the perception module to capture global and geometric features from the environment. To generate safe and efficient navigation policy, we further incorporate it with conditional imitation learning algorithm, to learn driving behaviors directly from expert demonstrations. Our proposed network is capable of handling a varying number of surrounding vehicles and generating optimal control actions (e.g., steering angle and throttle) according to the given high-level commands (e.g., turn left towards the global goal). Evaluations on unsignaled intersections with various traffic densities demonstrate that our end-to-end trainable neural network outperforms the baselines with higher success rate and shorter navigation time.
AVGCN: Trajectory Prediction using Graph Convolutional Networks Guided by Human Attention
Jan 14, 2021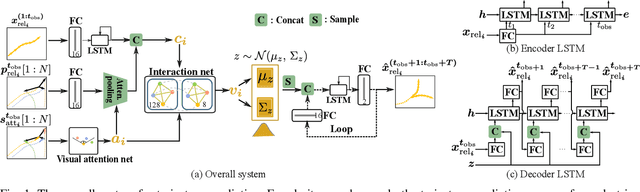
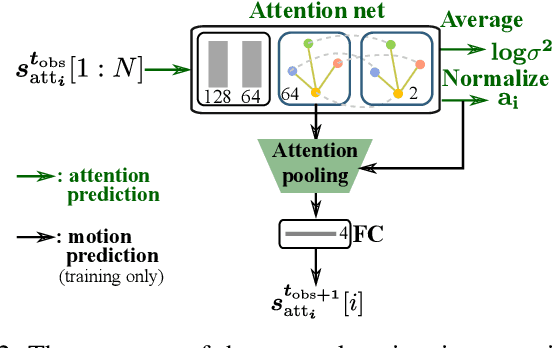
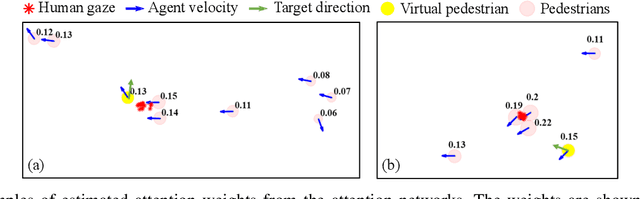
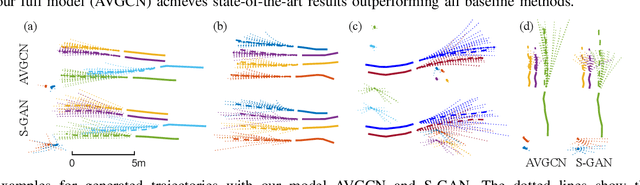
Pedestrian trajectory prediction is a critical yet challenging task, especially for crowded scenes. We suggest that introducing an attention mechanism to infer the importance of different neighbors is critical for accurate trajectory prediction in scenes with varying crowd size. In this work, we propose a novel method, AVGCN, for trajectory prediction utilizing graph convolutional networks (GCN) based on human attention (A denotes attention, V denotes visual field constraints). First, we train an attention network that estimates the importance of neighboring pedestrians, using gaze data collected as subjects perform a bird's eye view crowd navigation task. Then, we incorporate the learned attention weights modulated by constraints on the pedestrian's visual field into a trajectory prediction network that uses a GCN to aggregate information from neighbors efficiently. AVGCN also considers the stochastic nature of pedestrian trajectories by taking advantage of variational trajectory prediction. Our approach achieves state-of-the-art performance on several trajectory prediction benchmarks, and the lowest average prediction error over all considered benchmarks.
HGCN-GJS: Hierarchical Graph Convolutional Network with Groupwise Joint Sampling for Trajectory Prediction
Sep 15, 2020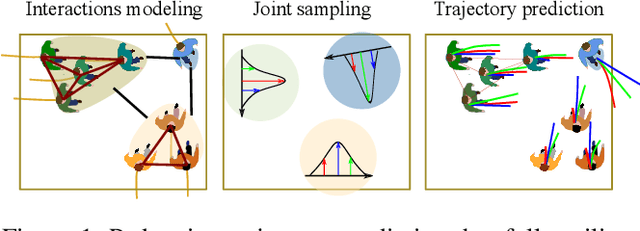
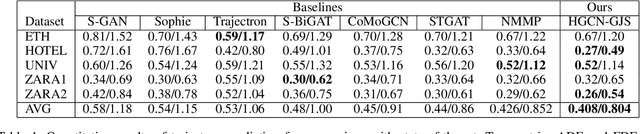
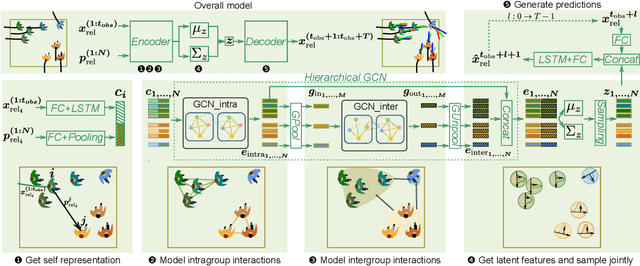
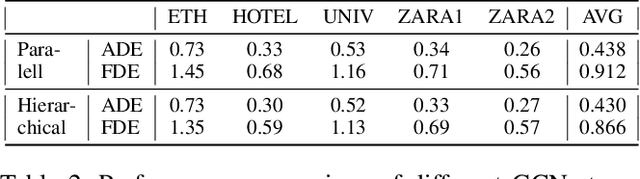
Accurate pedestrian trajectory prediction is of great importance for downstream tasks such as autonomous driving and mobile robot navigation. Fully investigating the social interactions within the crowd is crucial for accurate pedestrian trajectory prediction. However, most existing methods do not capture group level interactions well, focusing only on pairwise interactions and neglecting group-wise interactions. In this work, we propose a hierarchical graph convolutional network, HGCN-GJS, for trajectory prediction which well leverages group level interactions within the crowd. Furthermore, we introduce a novel joint sampling scheme for modeling the joint distribution of multiple pedestrians in the future trajectories. Based on the group information, this scheme associates the trajectory of one person with the trajectory of other people in the group, but maintains the independence of the trajectories of outsiders. We demonstrate the performance of our network on several trajectory prediction datasets, achieving state-of-the-art results on all datasets considered.
CoMoGCN: Coherent Motion Aware Trajectory Prediction with Graph Representation
May 05, 2020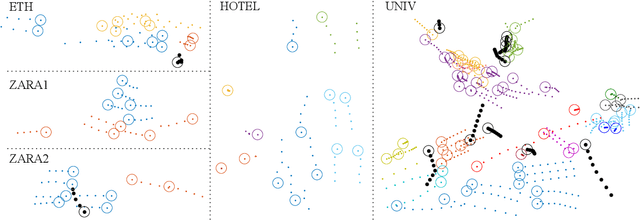
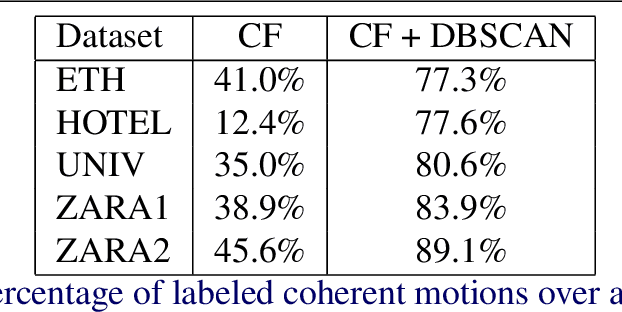
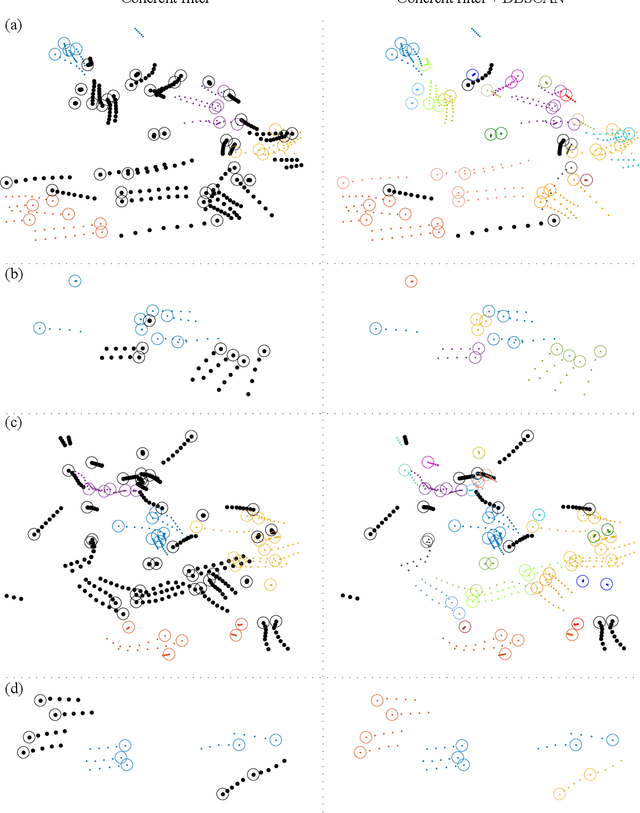
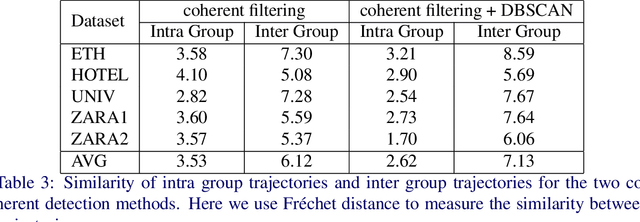
Forecasting human trajectories is critical for tasks such as robot crowd navigation and autonomous driving. Modeling social interactions is of great importance for accurate group-wise motion prediction. However, most existing methods do not consider information about coherence within the crowd, but rather only pairwise interactions. In this work, we propose a novel framework, coherent motion aware graph convolutional network (CoMoGCN), for trajectory prediction in crowded scenes with group constraints. First, we cluster pedestrian trajectories into groups according to motion coherence. Then, we use graph convolutional networks to aggregate crowd information efficiently. The CoMoGCN also takes advantage of variational autoencoders to capture the multimodal nature of the human trajectories by modeling the distribution. Our method achieves state-of-the-art performance on several different trajectory prediction benchmarks, and the best average performance among all benchmarks considered.
Hercules: An Autonomous Logistic Vehicle for Contact-less Goods Transportation During the COVID-19 Outbreak
Apr 16, 2020
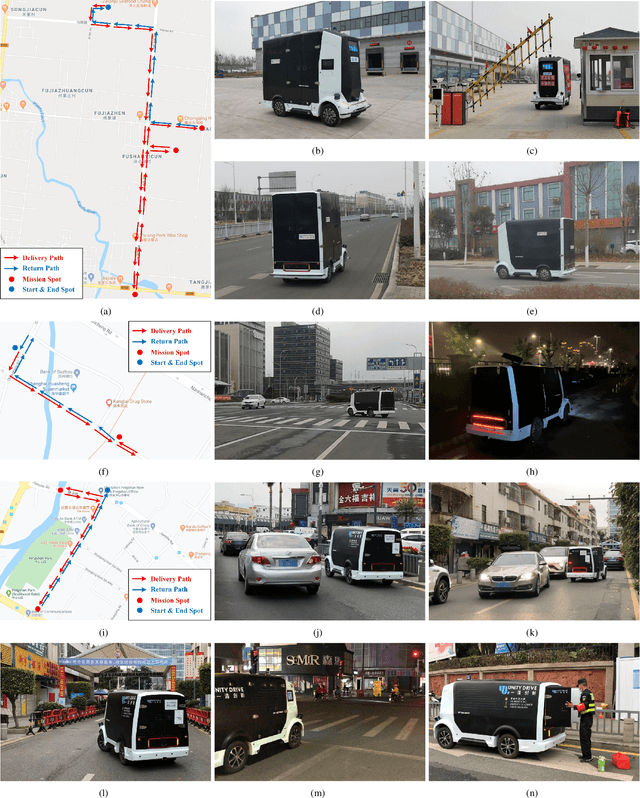
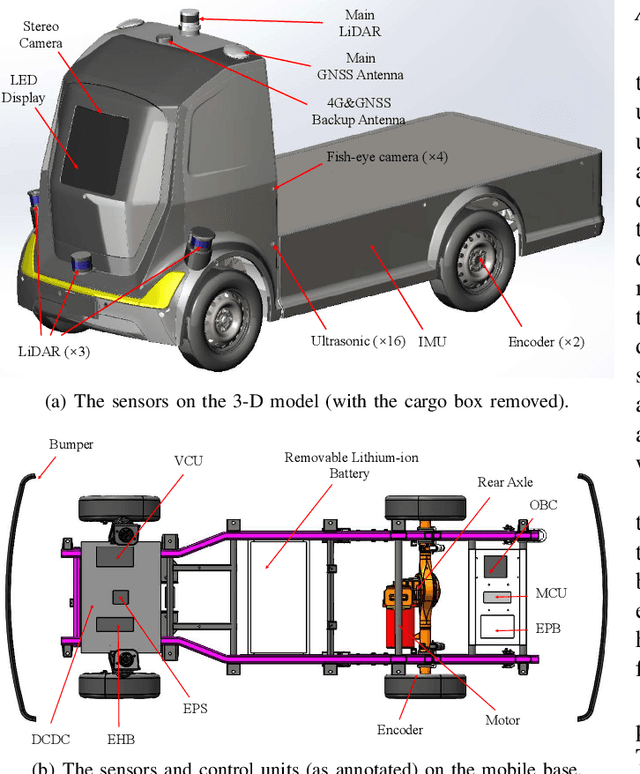
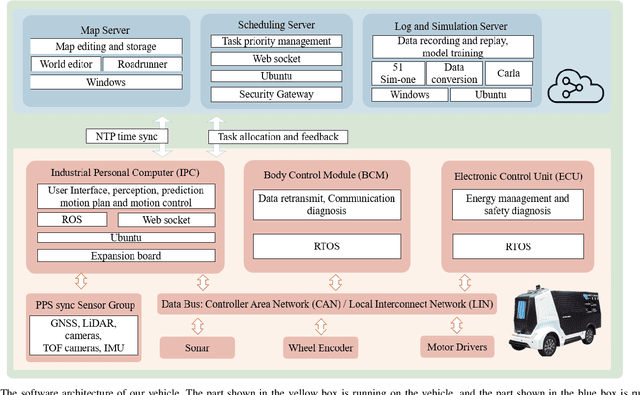
Since December 2019, the coronavirus disease 2019 (COVID-19) has spread rapidly across China. As at the date of writing this article, the disease has been globally reported in 100 countries, infected over 100,000 people and caused over 3,000 deaths. Avoiding person-to-person transmission is an effective approach to control and prevent the epidemic. However, many daily activities, such as logistics transporting goods in our daily life, inevitably involve person-to-person contact. To achieve contact-less goods transportation, using an autonomous logistic vehicle has become the preferred choice. This article presents Hercules, an autonomous logistic vehicle used for contact-less goods transportation during the outbreak of COVID-19. The vehicle is designed with autonomous navigation capability. We provide details on the hardware and software, as well as the algorithms to achieve autonomous navigation including perception, planning and control. This paper is accompanied by a demonstration video and a dataset, which are available here: https://sites.google.com/view/contact-less-transportation.
Robot Navigation in Crowds by Graph Convolutional Networks with Attention Learned from Human Gaze
Sep 23, 2019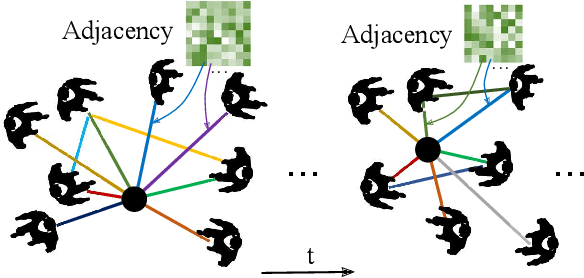
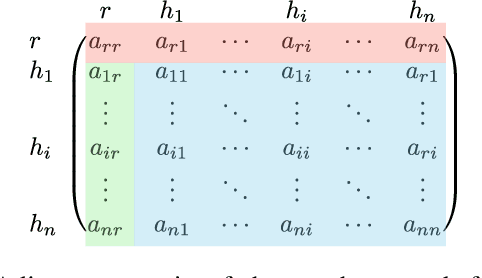
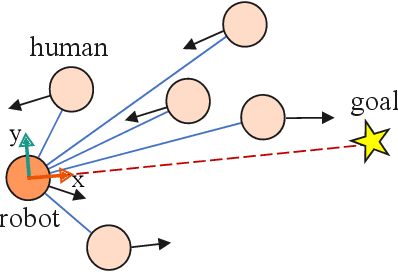
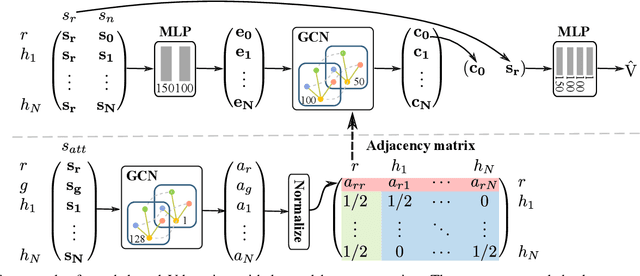
Safe and efficient crowd navigation for mobile robot is a crucial yet challenging task. Previous work has shown the power of deep reinforcement learning frameworks to train efficient policies. However, their performance deteriorates when the crowd size grows. We suggest that this can be addressed by enabling the network to identify and pay attention to the humans in the crowd that are most critical to navigation. We propose a novel network utilizing a graph representation to learn the policy. We first train a graph convolutional network based on human gaze data that accurately predicts human attention to different agents in the crowd. Then we incorporate the learned attention into a graph-based reinforcement learning architecture. The proposed attention mechanism enables the assignment of meaningful weightings to the neighbors of the robot, and has the additional benefit of interpretability. Experiments on real-world dense pedestrian datasets with various crowd sizes demonstrate that our model outperforms state-of-art methods by 18.4% in task accomplishment and by 16.4% in time efficiency.
Utilizing Eye Gaze to Enhance the Generalization of Imitation Networks to Unseen Environments
Aug 27, 2019
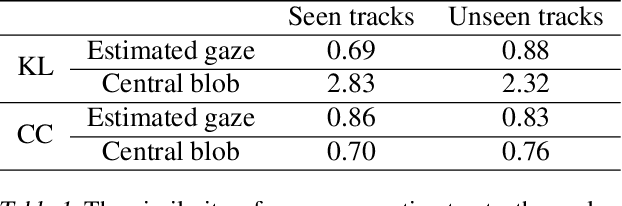
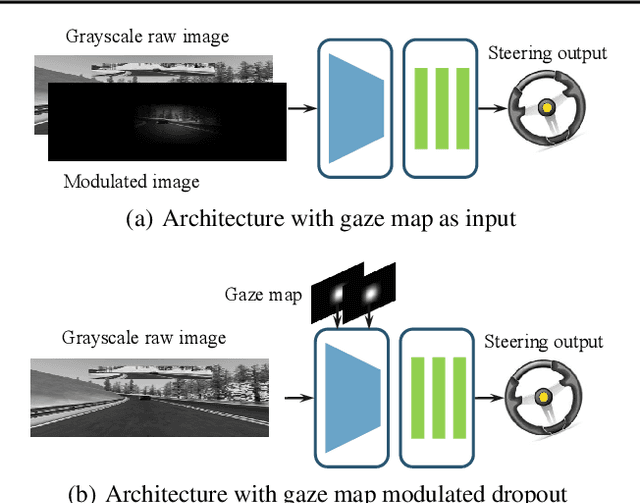
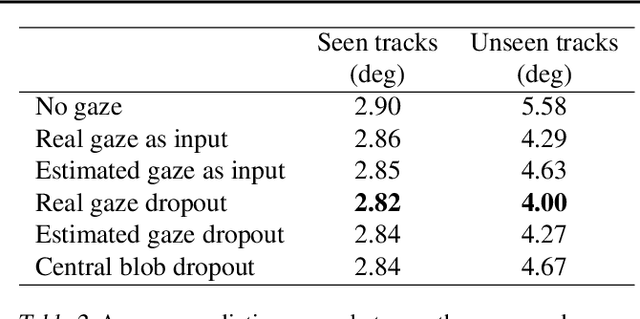
Vision-based autonomous driving through imitation learning mimics the behaviors of human drivers by training on pairs of data of raw driver-view images and actions. However, there are other cues, e.g. gaze behavior, available from human drivers that have yet to be exploited. Previous research has shown that novice human learners can benefit from observing experts' gaze patterns. We show here that deep neural networks can also benefit from this. We demonstrate different approaches to integrating gaze information into imitation networks. Our results show that the integration of gaze information improves the generalization performance of networks to unseen environments.