Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Pre-training Models in Named Entity Recognition
Paper and Code
Feb 09, 2020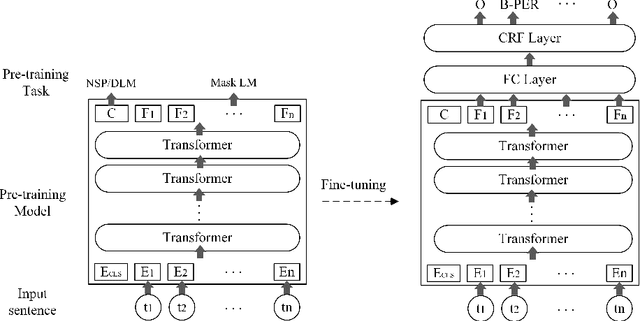
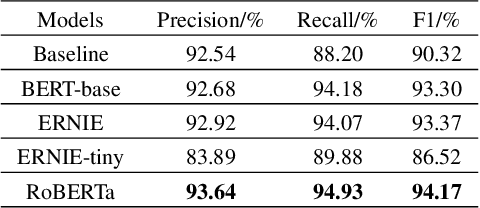
Named Entity Recognition (NER) is a fundamental Natural Language Processing (NLP) task to extract entities from unstructured data. The previous methods for NER were based on machine learning or deep learning. Recently, pre-training models have significantly improved performance on multiple NLP tasks. In this paper, firstly, we introduce the architecture and pre-training tasks of four common pre-training models: BERT, ERNIE, ERNIE2.0-tiny, and RoBERTa. Then, we apply these pre-training models to a NER task by fine-tuning, and compare the effects of the different model architecture and pre-training tasks on the NER task. The experiment results showed that RoBERTa achieved state-of-the-art results on the MSRA-2006 dataset.
View paper on