 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFRAME: Feedback-Refined Agent Methodology for Enhancing Medical Research Insights
May 06, 2025



The automation of scientific research through large language models (LLMs) presents significant opportunities but faces critical challenges in knowledge synthesis and quality assurance. We introduce Feedback-Refined Agent Methodology (FRAME), a novel framework that enhances medical paper generation through iterative refinement and structured feedback. Our approach comprises three key innovations: (1) A structured dataset construction method that decomposes 4,287 medical papers into essential research components through iterative refinement; (2) A tripartite architecture integrating Generator, Evaluator, and Reflector agents that progressively improve content quality through metric-driven feedback; and (3) A comprehensive evaluation framework that combines statistical metrics with human-grounded benchmarks. Experimental results demonstrate FRAME's effectiveness, achieving significant improvements over conventional approaches across multiple models (9.91% average gain with DeepSeek V3, comparable improvements with GPT-4o Mini) and evaluation dimensions. Human evaluation confirms that FRAME-generated papers achieve quality comparable to human-authored works, with particular strength in synthesizing future research directions. The results demonstrated our work could efficiently assist medical research by building a robust foundation for automated medical research paper generation while maintaining rigorous academic standards.
ConcealGS: Concealing Invisible Copyright Information in 3D Gaussian Splatting
Jan 07, 2025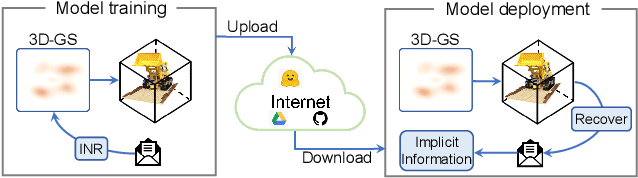
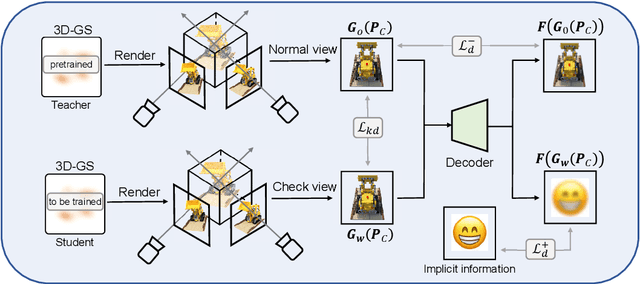


With the rapid development of 3D reconstruction technology, the widespread distribution of 3D data has become a future trend. While traditional visual data (such as images and videos) and NeRF-based formats already have mature techniques for copyright protection, steganographic techniques for the emerging 3D Gaussian Splatting (3D-GS) format have yet to be fully explored. To address this, we propose ConcealGS, an innovative method for embedding implicit information into 3D-GS. By introducing the knowledge distillation and gradient optimization strategy based on 3D-GS, ConcealGS overcomes the limitations of NeRF-based models and enhances the robustness of implicit information and the quality of 3D reconstruction. We evaluate ConcealGS in various potential application scenarios, and experimental results have demonstrated that ConcealGS not only successfully recovers implicit information but also has almost no impact on rendering quality, providing a new approach for embedding invisible and recoverable information into 3D models in the future.
IIMedGPT: Promoting Large Language Model Capabilities of Medical Tasks by Efficient Human Preference Alignment
Jan 06, 2025Recent researches of large language models(LLM), which is pre-trained on massive general-purpose corpora, have achieved breakthroughs in responding human queries. However, these methods face challenges including limited data insufficiency to support extensive pre-training and can not align responses with users' instructions. To address these issues, we introduce a medical instruction dataset, CMedINS, containing six medical instructions derived from actual medical tasks, which effectively fine-tunes LLM in conjunction with other data. Subsequently, We launch our medical model, IIMedGPT, employing an efficient preference alignment method, Direct preference Optimization(DPO). The results show that our final model outperforms existing medical models in medical dialogue.Datsets, Code and model checkpoints will be released upon acceptance.
Beyond Training: Dynamic Token Merging for Zero-Shot Video Understanding
Nov 21, 2024Recent advancements in multimodal large language models (MLLMs) have opened new avenues for video understanding. However, achieving high fidelity in zero-shot video tasks remains challenging. Traditional video processing methods rely heavily on fine-tuning to capture nuanced spatial-temporal details, which incurs significant data and computation costs. In contrast, training-free approaches, though efficient, often lack robustness in preserving context-rich features across complex video content. To this end, we propose DYTO, a novel dynamic token merging framework for zero-shot video understanding that adaptively optimizes token efficiency while preserving crucial scene details. DYTO integrates a hierarchical frame selection and a bipartite token merging strategy to dynamically cluster key frames and selectively compress token sequences, striking a balance between computational efficiency with semantic richness. Extensive experiments across multiple benchmarks demonstrate the effectiveness of DYTO, achieving superior performance compared to both fine-tuned and training-free methods and setting a new state-of-the-art for zero-shot video understanding.
RankCLIP: Ranking-Consistent Language-Image Pretraining
Apr 15, 2024Among the ever-evolving development of vision-language models, contrastive language-image pretraining (CLIP) has set new benchmarks in many downstream tasks such as zero-shot classifications by leveraging self-supervised contrastive learning on large amounts of text-image pairs. However, its dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RankCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By leveraging both in-modal and cross-modal ranking consistency, RankCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the enhanced capability of RankCLIP to effectively improve performance across various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the potential of RankCLIP in further advancing vision-language pretraining.
Application of Pre-training Models in Named Entity Recognition
Feb 09, 2020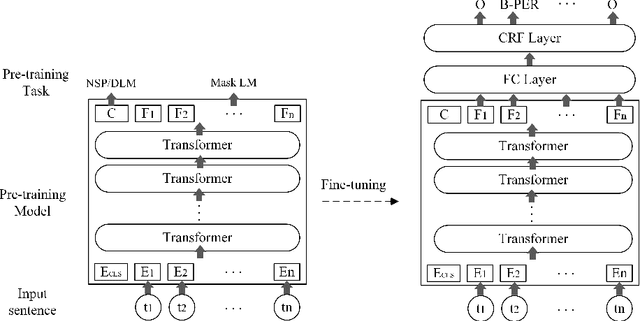
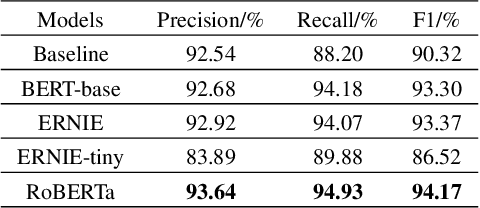
Named Entity Recognition (NER) is a fundamental Natural Language Processing (NLP) task to extract entities from unstructured data. The previous methods for NER were based on machine learning or deep learning. Recently, pre-training models have significantly improved performance on multiple NLP tasks. In this paper, firstly, we introduce the architecture and pre-training tasks of four common pre-training models: BERT, ERNIE, ERNIE2.0-tiny, and RoBERTa. Then, we apply these pre-training models to a NER task by fine-tuning, and compare the effects of the different model architecture and pre-training tasks on the NER task. The experiment results showed that RoBERTa achieved state-of-the-art results on the MSRA-2006 dataset.