 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDispelling the Curse of Singularities in Neural Network Optimizations
Feb 01, 2026This work investigates the optimization instability of deep neural networks from a less-explored yet insightful perspective: the emergence and amplification of singularities in the parametric space. Our analysis reveals that parametric singularities inevitably grow with gradient updates and further intensify alignment with representations, leading to increased singularities in the representation space. We show that the gradient Frobenius norms are bounded by the top singular values of the weight matrices, and as training progresses, the mutually reinforcing growth of weight and representation singularities, termed the curse of singularities, relaxes these bounds, escalating the risk of sharp loss explosions. To counter this, we propose Parametric Singularity Smoothing (PSS), a lightweight, flexible, and effective method for smoothing the singular spectra of weight matrices. Extensive experiments across diverse datasets, architectures, and optimizers demonstrate that PSS mitigates instability, restores trainability even after failure, and improves both training efficiency and generalization.
InfoBound: A Provable Information-Bounds Inspired Framework for Both OoD Generalization and OoD Detection
Apr 13, 2025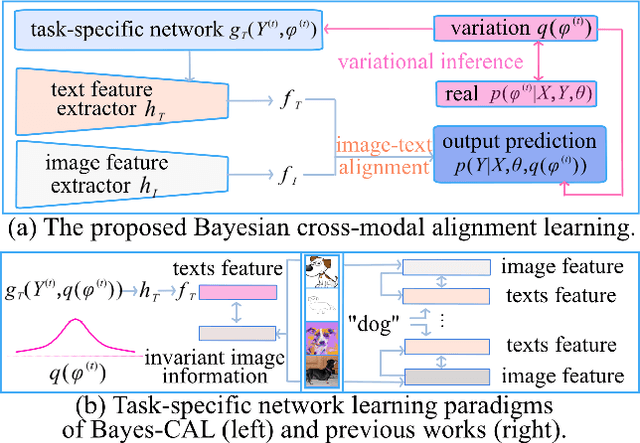
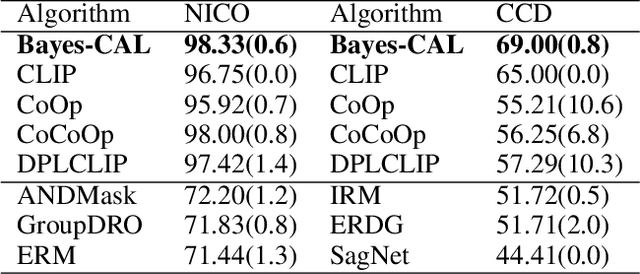
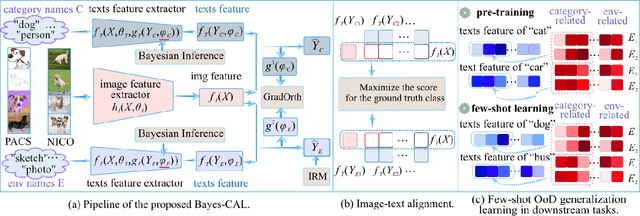
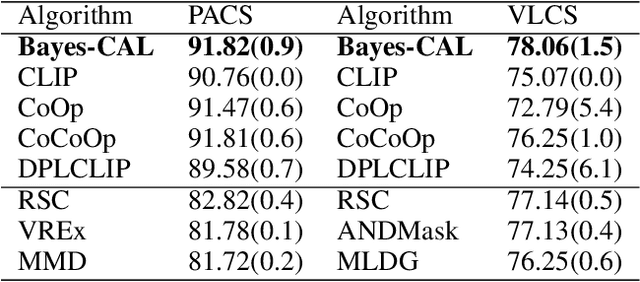
In real-world scenarios, distribution shifts give rise to the importance of two problems: out-of-distribution (OoD) generalization, which focuses on models' generalization ability against covariate shifts (i.e., the changes of environments), and OoD detection, which aims to be aware of semantic shifts (i.e., test-time unseen classes). Real-world testing environments often involve a combination of both covariate and semantic shifts. While numerous methods have been proposed to address these critical issues, only a few works tackled them simultaneously. Moreover, prior works often improve one problem but sacrifice the other. To overcome these limitations, we delve into boosting OoD detection and OoD generalization from the perspective of information theory, which can be easily applied to existing models and different tasks. Building upon the theoretical bounds for mutual information and conditional entropy, we provide a unified approach, composed of Mutual Information Minimization (MI-Min) and Conditional Entropy Maximizing (CE-Max). Extensive experiments and comprehensive evaluations on multi-label image classification and object detection have demonstrated the superiority of our method. It successfully mitigates trade-offs between the two challenges compared to competitive baselines.
OODD: Test-time Out-of-Distribution Detection with Dynamic Dictionary
Mar 13, 2025



Out-of-distribution (OOD) detection remains challenging for deep learning models, particularly when test-time OOD samples differ significantly from training outliers. We propose OODD, a novel test-time OOD detection method that dynamically maintains and updates an OOD dictionary without fine-tuning. Our approach leverages a priority queue-based dictionary that accumulates representative OOD features during testing, combined with an informative inlier sampling strategy for in-distribution (ID) samples. To ensure stable performance during early testing, we propose a dual OOD stabilization mechanism that leverages strategically generated outliers derived from ID data. To our best knowledge, extensive experiments on the OpenOOD benchmark demonstrate that OODD significantly outperforms existing methods, achieving a 26.0% improvement in FPR95 on CIFAR-100 Far OOD detection compared to the state-of-the-art approach. Furthermore, we present an optimized variant of the KNN-based OOD detection framework that achieves a 3x speedup while maintaining detection performance.
ConcealGS: Concealing Invisible Copyright Information in 3D Gaussian Splatting
Jan 07, 2025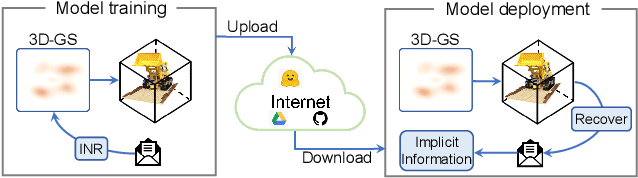
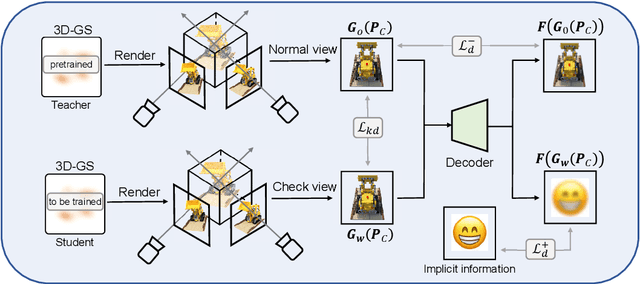


With the rapid development of 3D reconstruction technology, the widespread distribution of 3D data has become a future trend. While traditional visual data (such as images and videos) and NeRF-based formats already have mature techniques for copyright protection, steganographic techniques for the emerging 3D Gaussian Splatting (3D-GS) format have yet to be fully explored. To address this, we propose ConcealGS, an innovative method for embedding implicit information into 3D-GS. By introducing the knowledge distillation and gradient optimization strategy based on 3D-GS, ConcealGS overcomes the limitations of NeRF-based models and enhances the robustness of implicit information and the quality of 3D reconstruction. We evaluate ConcealGS in various potential application scenarios, and experimental results have demonstrated that ConcealGS not only successfully recovers implicit information but also has almost no impact on rendering quality, providing a new approach for embedding invisible and recoverable information into 3D models in the future.
Seed-Music: A Unified Framework for High Quality and Controlled Music Generation
Sep 13, 2024



We introduce Seed-Music, a suite of music generation systems capable of producing high-quality music with fine-grained style control. Our unified framework leverages both auto-regressive language modeling and diffusion approaches to support two key music creation workflows: \textit{controlled music generation} and \textit{post-production editing}. For controlled music generation, our system enables vocal music generation with performance controls from multi-modal inputs, including style descriptions, audio references, musical scores, and voice prompts. For post-production editing, it offers interactive tools for editing lyrics and vocal melodies directly in the generated audio. We encourage readers to listen to demo audio examples at https://team.doubao.com/seed-music .
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.
CRoFT: Robust Fine-Tuning with Concurrent Optimization for OOD Generalization and Open-Set OOD Detection
May 26, 2024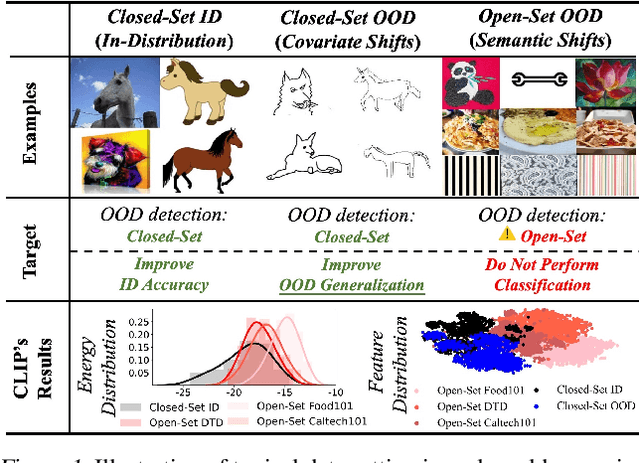



Recent vision-language pre-trained models (VL-PTMs) have shown remarkable success in open-vocabulary tasks. However, downstream use cases often involve further fine-tuning of VL-PTMs, which may distort their general knowledge and impair their ability to handle distribution shifts. In real-world scenarios, machine learning systems inevitably encounter both covariate shifts (e.g., changes in image styles) and semantic shifts (e.g., test-time unseen classes). This highlights the importance of enhancing out-of-distribution (OOD) generalization on covariate shifts and simultaneously detecting semantic-shifted unseen classes. Thus a critical but underexplored question arises: How to improve VL-PTMs' generalization ability to closed-set OOD data, while effectively detecting open-set unseen classes during fine-tuning? In this paper, we propose a novel objective function of OOD detection that also serves to improve OOD generalization. We show that minimizing the gradient magnitude of energy scores on training data leads to domain-consistent Hessians of classification loss, a strong indicator for OOD generalization revealed by theoretical analysis. Based on this finding, we have developed a unified fine-tuning framework that allows for concurrent optimization of both tasks. Extensive experiments have demonstrated the superiority of our method. The code is available at https://github.com/LinLLLL/CRoFT.
Selective Learning: Towards Robust Calibration with Dynamic Regularization
Feb 13, 2024



Miscalibration in deep learning refers to there is a discrepancy between the predicted confidence and performance. This problem usually arises due to the overfitting problem, which is characterized by learning everything presented in the training set, resulting in overconfident predictions during testing. Existing methods typically address overfitting and mitigate the miscalibration by adding a maximum-entropy regularizer to the objective function. The objective can be understood as seeking a model that fits the ground-truth labels by increasing the confidence while also maximizing the entropy of predicted probabilities by decreasing the confidence. However, previous methods lack clear guidance on confidence adjustment, leading to conflicting objectives (increasing but also decreasing confidence). Therefore, we introduce a method called Dynamic Regularization (DReg), which aims to learn what should be learned during training thereby circumventing the confidence adjusting trade-off. At a high level, DReg aims to obtain a more reliable model capable of acknowledging what it knows and does not know. Specifically, DReg effectively fits the labels for in-distribution samples (samples that should be learned) while applying regularization dynamically to samples beyond model capabilities (e.g., outliers), thereby obtaining a robust calibrated model especially on the samples beyond model capabilities. Both theoretical and empirical analyses sufficiently demonstrate the superiority of DReg compared with previous methods.