 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWindow Normalization: Enhancing Point Cloud Understanding by Unifying Inconsistent Point Densities
Dec 05, 2022



Downsampling and feature extraction are essential procedures for 3D point cloud understanding. Existing methods are limited by the inconsistent point densities of different parts in the point cloud. In this work, we analyze the limitation of the downsampling stage and propose the pre-abstraction group-wise window-normalization module. In particular, the window-normalization method is leveraged to unify the point densities in different parts. Furthermore, the group-wise strategy is proposed to obtain multi-type features, including texture and spatial information. We also propose the pre-abstraction module to balance local and global features. Extensive experiments show that our module performs better on several tasks. In segmentation tasks on S3DIS (Area 5), the proposed module performs better on small object recognition, and the results have more precise boundaries than others. The recognition of the sofa and the column is improved from 69.2% to 84.4% and from 42.7% to 48.7%, respectively. The benchmarks are improved from 71.7%/77.6%/91.9% (mIoU/mAcc/OA) to 72.2%/78.2%/91.4%. The accuracies of 6-fold cross-validation on S3DIS are 77.6%/85.8%/91.7%. It outperforms the best model PointNeXt-XL (74.9%/83.0%/90.3%) by 2.7% on mIoU and achieves state-of-the-art performance. The code and models are available at https://github.com/DBDXSS/Window-Normalization.git.
Single Image Super-Resolution via a Holistic Attention Network
Aug 20, 2020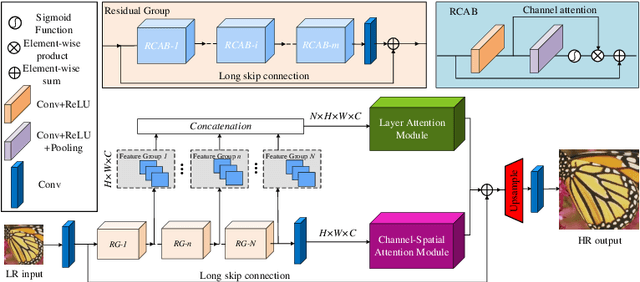

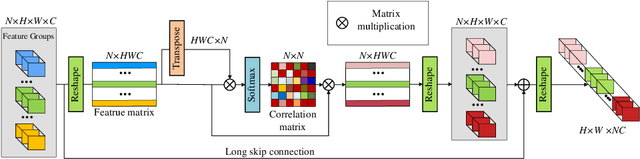

Informative features play a crucial role in the single image super-resolution task. Channel attention has been demonstrated to be effective for preserving information-rich features in each layer. However, channel attention treats each convolution layer as a separate process that misses the correlation among different layers. To address this problem, we propose a new holistic attention network (HAN), which consists of a layer attention module (LAM) and a channel-spatial attention module (CSAM), to model the holistic interdependencies among layers, channels, and positions. Specifically, the proposed LAM adaptively emphasizes hierarchical features by considering correlations among layers. Meanwhile, CSAM learns the confidence at all the positions of each channel to selectively capture more informative features. Extensive experiments demonstrate that the proposed HAN performs favorably against the state-of-the-art single image super-resolution approaches.
Hallucinating very low-resolution and obscured face images
Dec 12, 2018

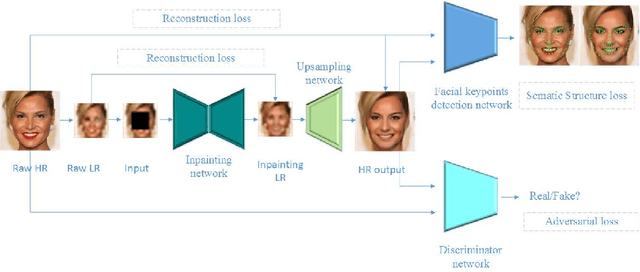

Most of the face hallucination methods are designed for complete inputs. They will not work well if the inputs are very tiny or contaminated by large occlusion. Inspired by this fact, we propose an obscured face hallucination network(OFHNet). The OFHNet consists of four parts: an inpainting network, an upsampling network, a discriminative network, and a fixed facial landmark detection network. The inpainting network restores the low-resolution(LR) obscured face images. The following upsampling network is to upsample the output of inpainting network. In order to ensure the generated high-resolution(HR) face images more photo-realistic, we utilize the discriminative network and the facial landmark detection network to better the result of upsampling network. In addition, we present a semantic structure loss, which makes the generated HR face images more pleasing. Extensive experiments show that our framework can restore the appealing HR face images from 1/4 missing area LR face images with a challenging scaling factor of 8x.