 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation
Nov 14, 2024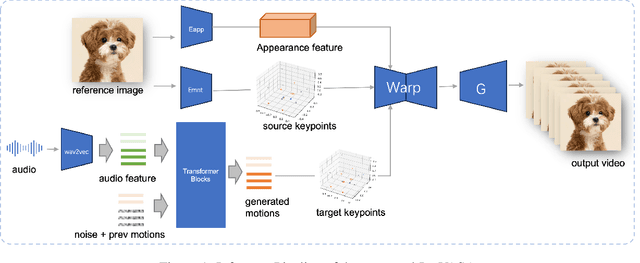
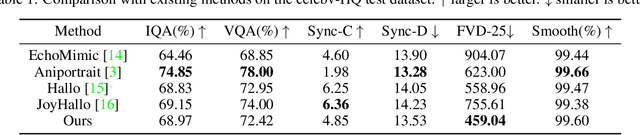
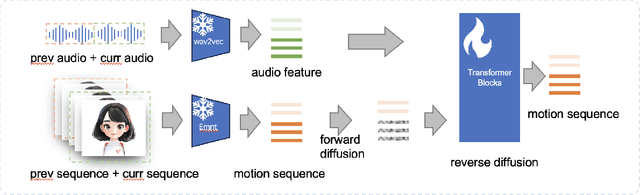
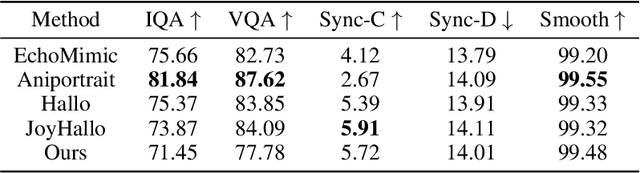
Audio-driven portrait animation has made significant advances with diffusion-based models, improving video quality and lipsync accuracy. However, the increasing complexity of these models has led to inefficiencies in training and inference, as well as constraints on video length and inter-frame continuity. In this paper, we propose JoyVASA, a diffusion-based method for generating facial dynamics and head motion in audio-driven facial animation. Specifically, in the first stage, we introduce a decoupled facial representation framework that separates dynamic facial expressions from static 3D facial representations. This decoupling allows the system to generate longer videos by combining any static 3D facial representation with dynamic motion sequences. Then, in the second stage, a diffusion transformer is trained to generate motion sequences directly from audio cues, independent of character identity. Finally, a generator trained in the first stage uses the 3D facial representation and the generated motion sequences as inputs to render high-quality animations. With the decoupled facial representation and the identity-independent motion generation process, JoyVASA extends beyond human portraits to animate animal faces seamlessly. The model is trained on a hybrid dataset of private Chinese and public English data, enabling multilingual support. Experimental results validate the effectiveness of our approach. Future work will focus on improving real-time performance and refining expression control, further expanding the applications in portrait animation. The code will be available at: https://jdhalgo.github.io/JoyVASA.
A Bi-Pyramid Multimodal Fusion Method for the Diagnosis of Bipolar Disorders
Jan 15, 2024



Previous research on the diagnosis of Bipolar disorder has mainly focused on resting-state functional magnetic resonance imaging. However, their accuracy can not meet the requirements of clinical diagnosis. Efficient multimodal fusion strategies have great potential for applications in multimodal data and can further improve the performance of medical diagnosis models. In this work, we utilize both sMRI and fMRI data and propose a novel multimodal diagnosis model for bipolar disorder. The proposed Patch Pyramid Feature Extraction Module extracts sMRI features, and the spatio-temporal pyramid structure extracts the fMRI features. Finally, they are fused by a fusion module to output diagnosis results with a classifier. Extensive experiments show that our proposed method outperforms others in balanced accuracy from 0.657 to 0.732 on the OpenfMRI dataset, and achieves the state of the art.
Window Normalization: Enhancing Point Cloud Understanding by Unifying Inconsistent Point Densities
Dec 05, 2022



Downsampling and feature extraction are essential procedures for 3D point cloud understanding. Existing methods are limited by the inconsistent point densities of different parts in the point cloud. In this work, we analyze the limitation of the downsampling stage and propose the pre-abstraction group-wise window-normalization module. In particular, the window-normalization method is leveraged to unify the point densities in different parts. Furthermore, the group-wise strategy is proposed to obtain multi-type features, including texture and spatial information. We also propose the pre-abstraction module to balance local and global features. Extensive experiments show that our module performs better on several tasks. In segmentation tasks on S3DIS (Area 5), the proposed module performs better on small object recognition, and the results have more precise boundaries than others. The recognition of the sofa and the column is improved from 69.2% to 84.4% and from 42.7% to 48.7%, respectively. The benchmarks are improved from 71.7%/77.6%/91.9% (mIoU/mAcc/OA) to 72.2%/78.2%/91.4%. The accuracies of 6-fold cross-validation on S3DIS are 77.6%/85.8%/91.7%. It outperforms the best model PointNeXt-XL (74.9%/83.0%/90.3%) by 2.7% on mIoU and achieves state-of-the-art performance. The code and models are available at https://github.com/DBDXSS/Window-Normalization.git.
An Extension of LIME with Improvement of Interpretability and Fidelity
Apr 26, 2020
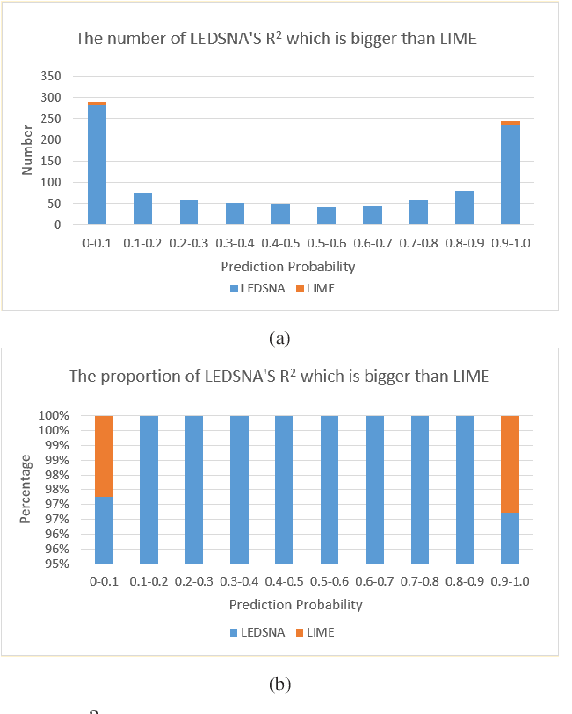
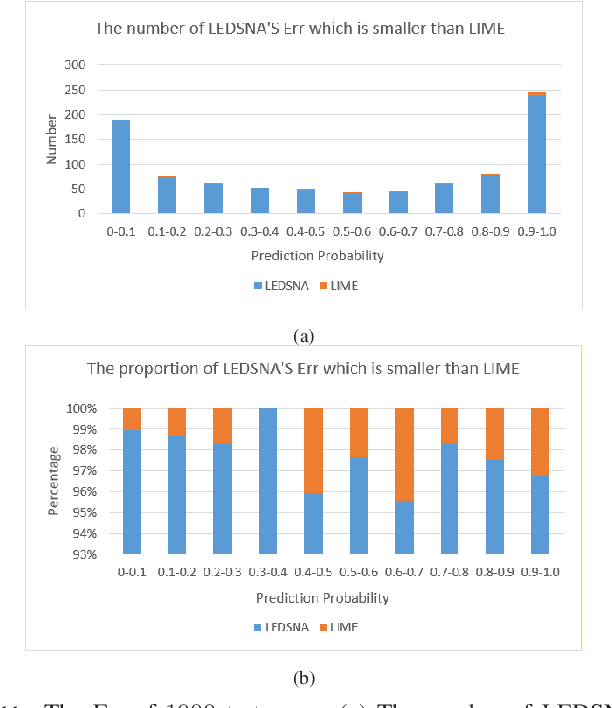
While deep learning makes significant achievements in Artificial Intelligence (AI), the lack of transparency has limited its broad application in various vertical domains. Explainability is not only a gateway between AI and real world, but also a powerful feature to detect flaw of the models and bias of the data. Local Interpretable Model-agnostic Explanation (LIME) is a widely-accepted technique that explains the prediction of any classifier faithfully by learning an interpretable model locally around the predicted instance. As an extension of LIME, this paper proposes an high-interpretability and high-fidelity local explanation method, known as Local Explanation using feature Dependency Sampling and Nonlinear Approximation (LEDSNA). Given an instance being explained, LEDSNA enhances interpretability by feature sampling with intrinsic dependency. Besides, LEDSNA improves the local explanation fidelity by approximating nonlinear boundary of local decision. We evaluate our method with classification tasks in both image domain and text domain. Experiments show that LEDSNA's explanation of the back-box model achieves much better performance than original LIME in terms of interpretability and fidelity.
A Modified Perturbed Sampling Method for Local Interpretable Model-agnostic Explanation
Feb 18, 2020
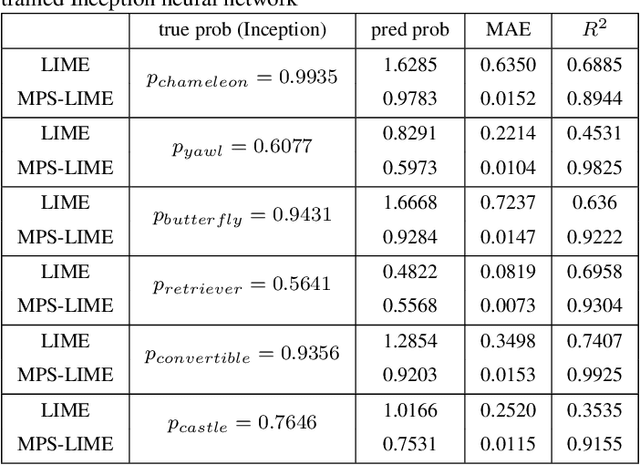
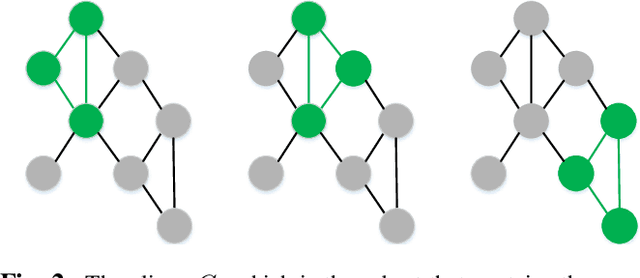
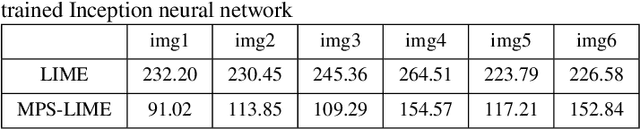
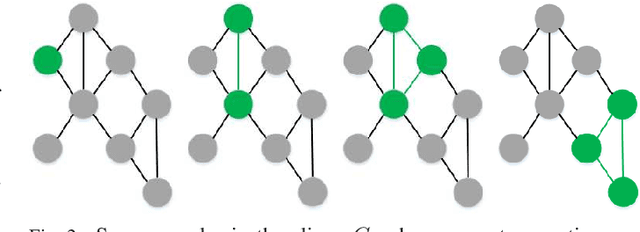
Explainability is a gateway between Artificial Intelligence and society as the current popular deep learning models are generally weak in explaining the reasoning process and prediction results. Local Interpretable Model-agnostic Explanation (LIME) is a recent technique that explains the predictions of any classifier faithfully by learning an interpretable model locally around the prediction. However, the sampling operation in the standard implementation of LIME is defective. Perturbed samples are generated from a uniform distribution, ignoring the complicated correlation between features. This paper proposes a novel Modified Perturbed Sampling operation for LIME (MPS-LIME), which is formalized as the clique set construction problem. In image classification, MPS-LIME converts the superpixel image into an undirected graph. Various experiments show that the MPS-LIME explanation of the black-box model achieves much better performance in terms of understandability, fidelity, and efficiency.
Explaining the Predictions of Any Image Classifier via Decision Trees
Nov 04, 2019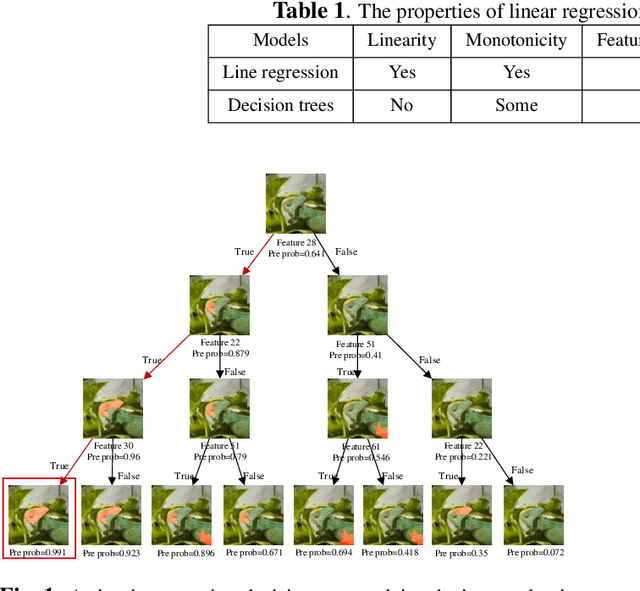


Despite outstanding contribution to the significant progress of Artificial Intelligence (AI), deep learning models remain mostly black boxes, which are extremely weak in explainability of the reasoning process and prediction results. Explainability is not only a gateway between AI and society but also a powerful tool to detect flaws in the model and biases in the data. Local Interpretable Model-agnostic Explanation (LIME) is a recent approach that uses a linear regression model to form a local explanation for the individual prediction result. However, being so restricted and usually oversimplifying the relationships, linear models fail in situations where nonlinear associations and interactions exist among features and prediction results. This paper proposes an extended Decision Tree-based LIME (TLIME) approach, which uses a decision tree model to form an interpretable representation that is locally faithful to the original model. The new approach can capture nonlinear interactions among features in the data and creates plausible explanations. Various experiments show that the TLIME explanation of multiple blackbox models can achieve more reliable performance in terms of understandability, fidelity, and efficiency.