 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation
Nov 14, 2024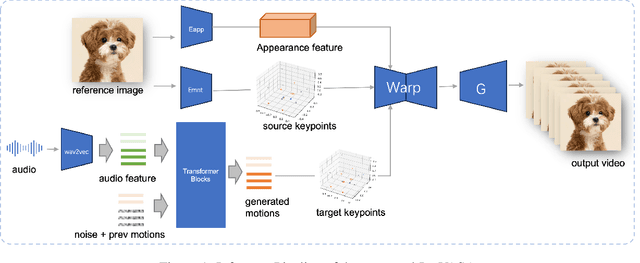
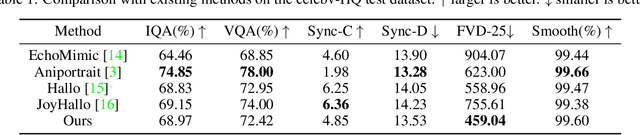
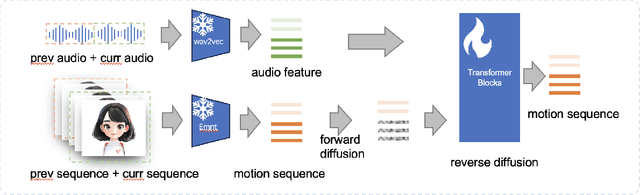
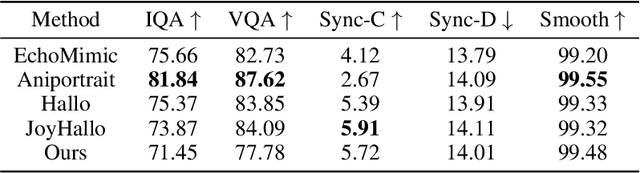
Audio-driven portrait animation has made significant advances with diffusion-based models, improving video quality and lipsync accuracy. However, the increasing complexity of these models has led to inefficiencies in training and inference, as well as constraints on video length and inter-frame continuity. In this paper, we propose JoyVASA, a diffusion-based method for generating facial dynamics and head motion in audio-driven facial animation. Specifically, in the first stage, we introduce a decoupled facial representation framework that separates dynamic facial expressions from static 3D facial representations. This decoupling allows the system to generate longer videos by combining any static 3D facial representation with dynamic motion sequences. Then, in the second stage, a diffusion transformer is trained to generate motion sequences directly from audio cues, independent of character identity. Finally, a generator trained in the first stage uses the 3D facial representation and the generated motion sequences as inputs to render high-quality animations. With the decoupled facial representation and the identity-independent motion generation process, JoyVASA extends beyond human portraits to animate animal faces seamlessly. The model is trained on a hybrid dataset of private Chinese and public English data, enabling multilingual support. Experimental results validate the effectiveness of our approach. Future work will focus on improving real-time performance and refining expression control, further expanding the applications in portrait animation. The code will be available at: https://jdhalgo.github.io/JoyVASA.
Multi-Dimension-Embedding-Aware Modality Fusion Transformer for Psychiatric Disorder Clasification
Oct 04, 2023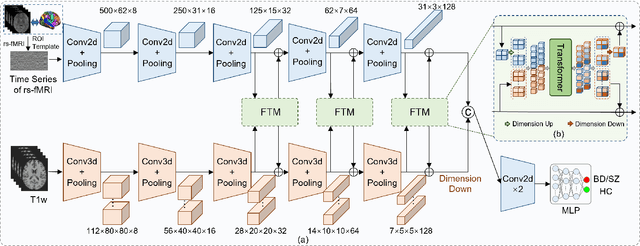
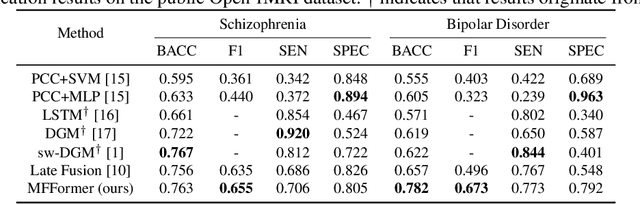
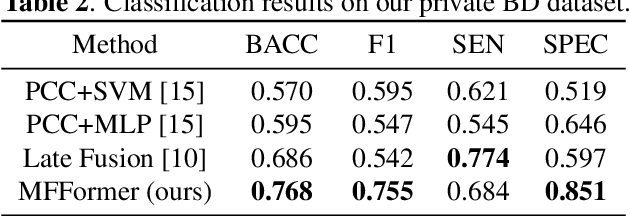
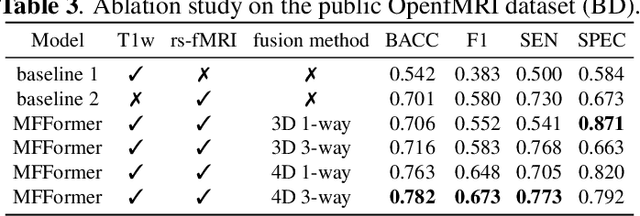
Deep learning approaches, together with neuroimaging techniques, play an important role in psychiatric disorders classification. Previous studies on psychiatric disorders diagnosis mainly focus on using functional connectivity matrices of resting-state functional magnetic resonance imaging (rs-fMRI) as input, which still needs to fully utilize the rich temporal information of the time series of rs-fMRI data. In this work, we proposed a multi-dimension-embedding-aware modality fusion transformer (MFFormer) for schizophrenia and bipolar disorder classification using rs-fMRI and T1 weighted structural MRI (T1w sMRI). Concretely, to fully utilize the temporal information of rs-fMRI and spatial information of sMRI, we constructed a deep learning architecture that takes as input 2D time series of rs-fMRI and 3D volumes T1w. Furthermore, to promote intra-modality attention and information fusion across different modalities, a fusion transformer module (FTM) is designed through extensive self-attention of hybrid feature maps of multi-modality. In addition, a dimension-up and dimension-down strategy is suggested to properly align feature maps of multi-dimensional from different modalities. Experimental results on our private and public OpenfMRI datasets show that our proposed MFFormer performs better than that using a single modality or multi-modality MRI on schizophrenia and bipolar disorder diagnosis.