 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dimension-Embedding-Aware Modality Fusion Transformer for Psychiatric Disorder Clasification
Oct 04, 2023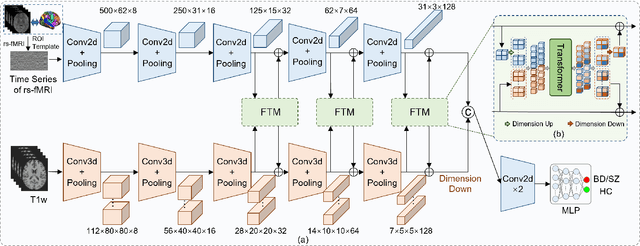
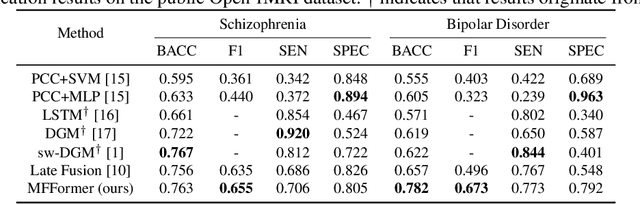
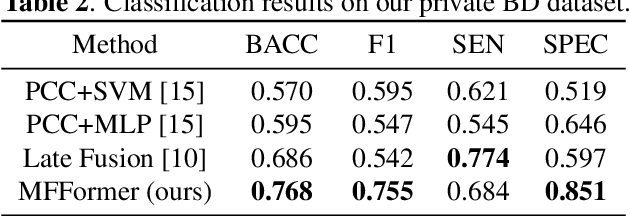
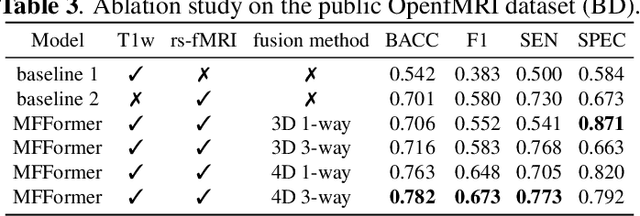
Deep learning approaches, together with neuroimaging techniques, play an important role in psychiatric disorders classification. Previous studies on psychiatric disorders diagnosis mainly focus on using functional connectivity matrices of resting-state functional magnetic resonance imaging (rs-fMRI) as input, which still needs to fully utilize the rich temporal information of the time series of rs-fMRI data. In this work, we proposed a multi-dimension-embedding-aware modality fusion transformer (MFFormer) for schizophrenia and bipolar disorder classification using rs-fMRI and T1 weighted structural MRI (T1w sMRI). Concretely, to fully utilize the temporal information of rs-fMRI and spatial information of sMRI, we constructed a deep learning architecture that takes as input 2D time series of rs-fMRI and 3D volumes T1w. Furthermore, to promote intra-modality attention and information fusion across different modalities, a fusion transformer module (FTM) is designed through extensive self-attention of hybrid feature maps of multi-modality. In addition, a dimension-up and dimension-down strategy is suggested to properly align feature maps of multi-dimensional from different modalities. Experimental results on our private and public OpenfMRI datasets show that our proposed MFFormer performs better than that using a single modality or multi-modality MRI on schizophrenia and bipolar disorder diagnosis.
Wind Turbine Gearbox Fault Detection Based on Sparse Filtering and Graph Neural Networks
Mar 06, 2023

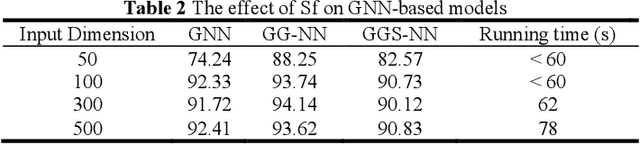
The wind energy industry has been experiencing tremendous growth and confronting the failures of wind turbine components. Wind turbine gearbox malfunctions are particularly prevalent and lead to the most prolonged downtime and highest cost. This paper presents a data-driven gearbox fault detection algorithm base on high frequency vibration data using graph neural network (GNN) models and sparse filtering (SF). The approach can take advantage of the comprehensive data sources and the complicated sensing networks. The GNN models, including basic graph neural networks, gated graph neural networks, and gated graph sequential neural networks, are used to detect gearbox condition from knowledge-based graphs formed using wind turbine information. Sparse filtering is used as an unsupervised feature learning method to accelerate the training of the GNN models. The effectiveness of the proposed method was verified on practical experimental data.
Evolutionary Deep Nets for Non-Intrusive Load Monitoring
Mar 06, 2023
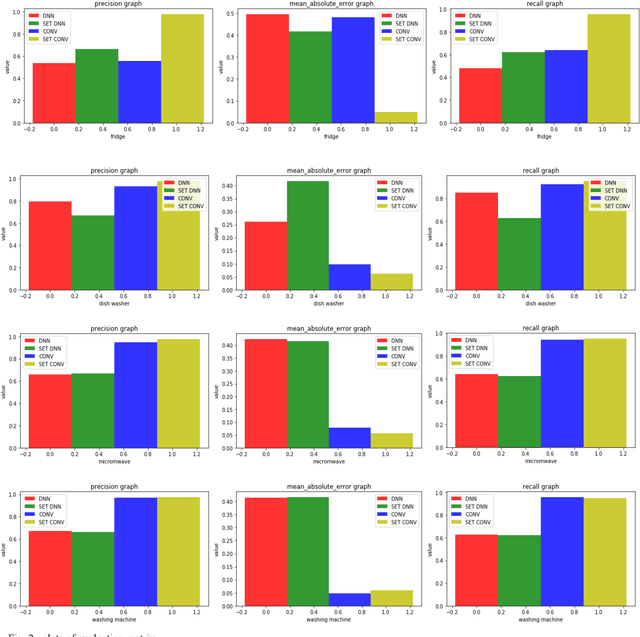
Non-Intrusive Load Monitoring (NILM) is an energy efficiency technique to track electricity consumption of an individual appliance in a household by one aggregated single, such as building level meter readings. The goal of NILM is to disaggregate the appliance from the aggregated singles by computational method. In this work, deep learning approaches are implemented to operate the desegregations. Deep neural networks, convolutional neural networks, and recurrent neural networks are employed for this operation. Additionally, sparse evolutionary training is applied to accelerate training efficiency of each deep learning model. UK-Dale dataset is used for this work.
Confidence Regularized Self-Training
Aug 27, 2019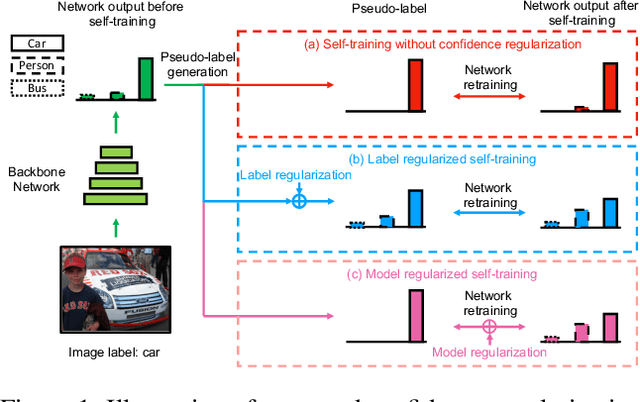

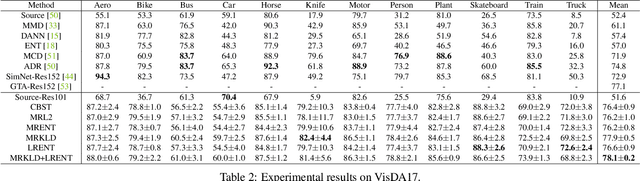
Recent advances in domain adaptation show that deep self-training presents a powerful means for unsupervised domain adaptation. These methods often involve an iterative process of predicting on target domain and then taking the confident predictions as pseudo-labels for retraining. However, since pseudo-labels can be noisy, self-training can put overconfident label belief on wrong classes, leading to deviated solutions with propagated errors. To address the problem, we propose a confidence regularized self-training (CRST) framework, formulated as regularized self-training. Our method treats pseudo-labels as continuous latent variables jointly optimized via alternating optimization. We propose two types of confidence regularization: label regularization (LR) and model regularization (MR). CRST-LR generates soft pseudo-labels while CRST-MR encourages the smoothness on network output. Extensive experiments on image classification and semantic segmentation show that CRSTs outperform their non-regularized counterpart with state-of-the-art performance. The code and models of this work are available at https://github.com/yzou2/CRST.
Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
Oct 25, 2018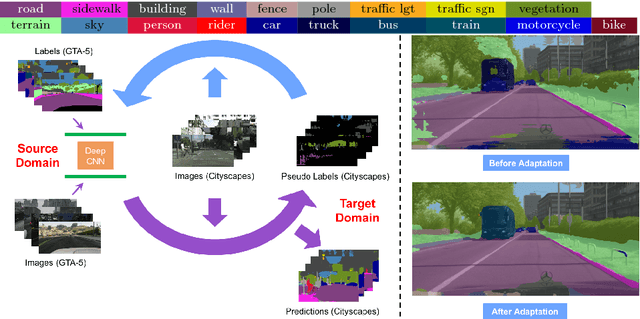
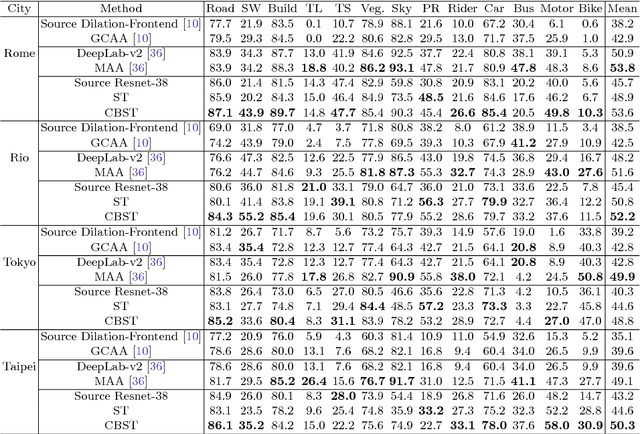
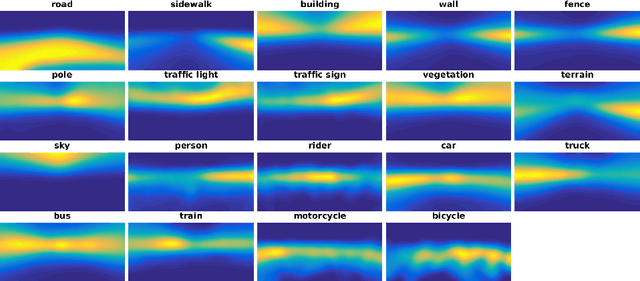
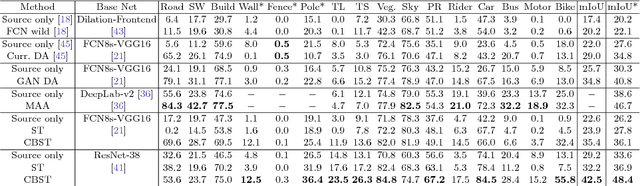
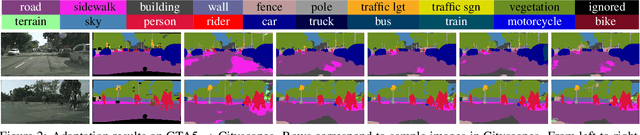
Recent deep networks achieved state of the art performance on a variety of semantic segmentation tasks. Despite such progress, these models often face challenges in real world `wild tasks' where large difference between labeled training/source data and unseen test/target data exists. In particular, such difference is often referred to as `domain gap', and could cause significantly decreased performance which cannot be easily remedied by further increasing the representation power. Unsupervised domain adaptation (UDA) seeks to overcome such problem without target domain labels. In this paper, we propose a novel UDA framework based on an iterative self-training procedure, where the problem is formulated as latent variable loss minimization, and can be solved by alternatively generating pseudo labels on target data and re-training the model with these labels. On top of self-training, we also propose a novel class-balanced self-training framework to avoid the gradual dominance of large classes on pseudo-label generation, and introduce spatial priors to refine generated labels. Comprehensive experiments show that the proposed methods achieve state of the art semantic segmentation performance under multiple major UDA settings.