 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Disentangling and Adaptation for Cross-Domain Person Re-Identification
Jul 20, 2020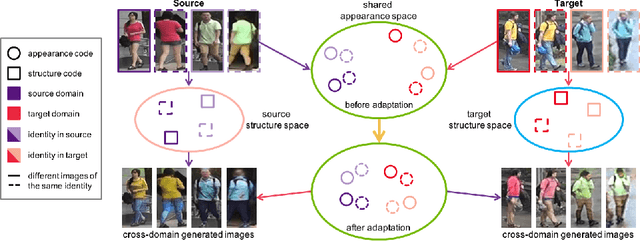
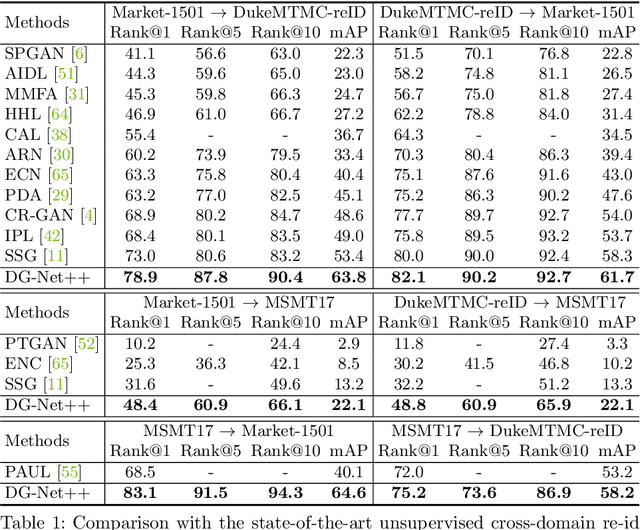
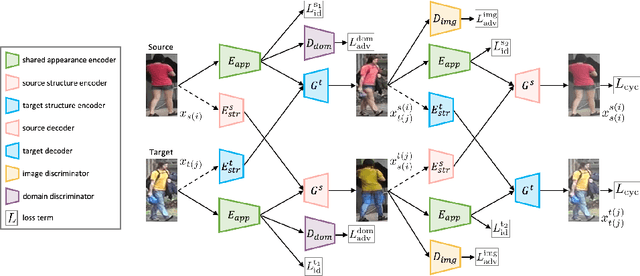
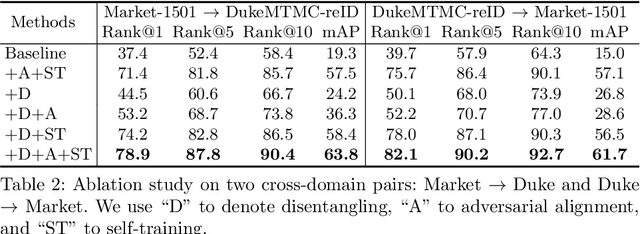
Although a significant progress has been witnessed in supervised person re-identification (re-id), it remains challenging to generalize re-id models to new domains due to the huge domain gaps. Recently, there has been a growing interest in using unsupervised domain adaptation to address this scalability issue. Existing methods typically conduct adaptation on the representation space that contains both id-related and id-unrelated factors, thus inevitably undermining the adaptation efficacy of id-related features. In this paper, we seek to improve adaptation by purifying the representation space to be adapted. To this end, we propose a joint learning framework that disentangles id-related/unrelated features and enforces adaptation to work on the id-related feature space exclusively. Our model involves a disentangling module that encodes cross-domain images into a shared appearance space and two separate structure spaces, and an adaptation module that performs adversarial alignment and self-training on the shared appearance space. The two modules are co-designed to be mutually beneficial. Extensive experiments demonstrate that the proposed joint learning framework outperforms the state-of-the-art methods by clear margins.
Towards Occlusion-Aware Multifocal Displays
May 02, 2020


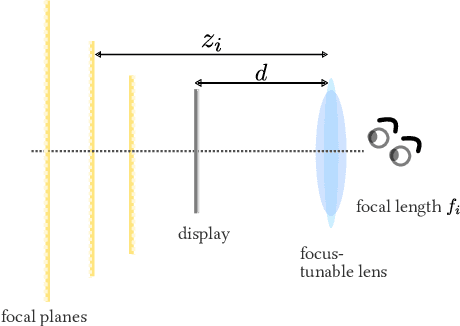
The human visual system uses numerous cues for depth perception, including disparity, accommodation, motion parallax and occlusion. It is incumbent upon virtual-reality displays to satisfy these cues to provide an immersive user experience. Multifocal displays, one of the classic approaches to satisfy the accommodation cue, place virtual content at multiple focal planes, each at a di erent depth. However, the content on focal planes close to the eye do not occlude those farther away; this deteriorates the occlusion cue as well as reduces contrast at depth discontinuities due to leakage of the defocus blur. This paper enables occlusion-aware multifocal displays using a novel ConeTilt operator that provides an additional degree of freedom -- tilting the light cone emitted at each pixel of the display panel. We show that, for scenes with relatively simple occlusion con gurations, tilting the light cones provides the same e ect as physical occlusion. We demonstrate that ConeTilt can be easily implemented by a phase-only spatial light modulator. Using a lab prototype, we show results that demonstrate the presence of occlusion cues and the increased contrast of the display at depth edges.
Deep Classification Network for Monocular Depth Estimation
Oct 23, 2019
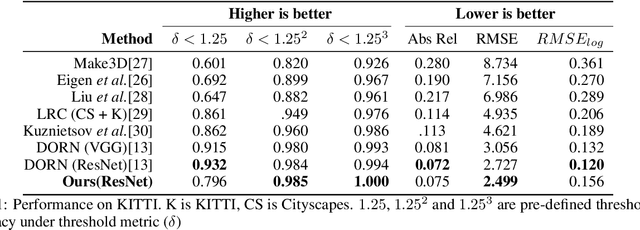

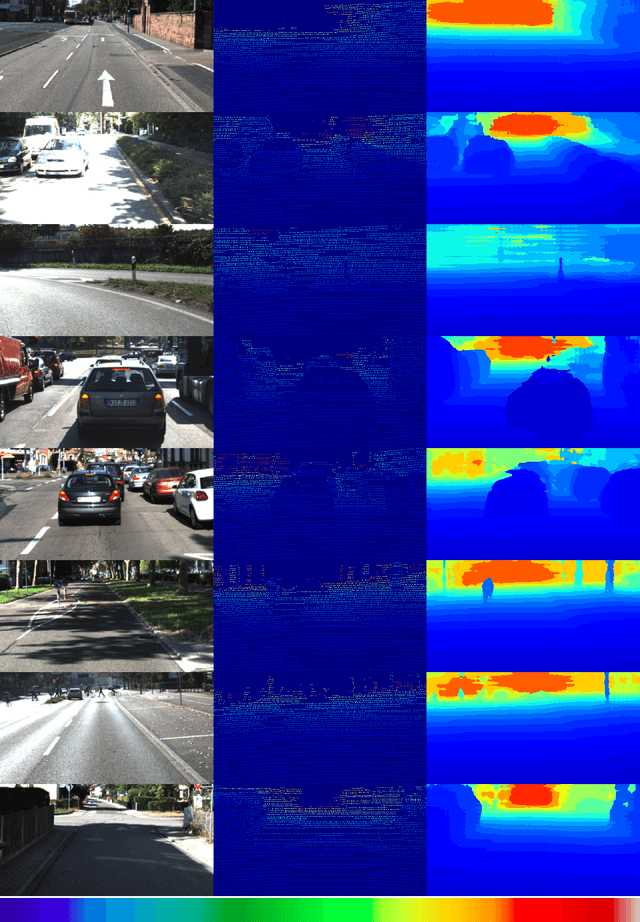
Monocular Depth Estimation is usually treated as a supervised and regression problem when it actually is very similar to semantic segmentation task since they both are fundamentally pixel-level classification tasks. We applied depth increments that increases with depth in discretizing depth values and then applied Deeplab v2 and the result was higher accuracy. We were able to achieve a state-of-the-art result on the KITTI dataset and outperformed existing architecture by an 8% margin.
Confidence Regularized Self-Training
Aug 27, 2019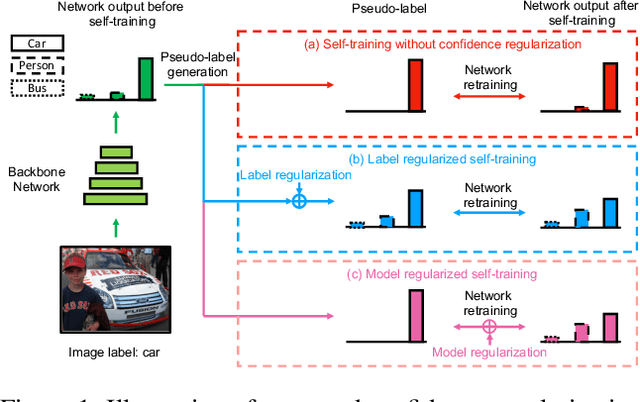

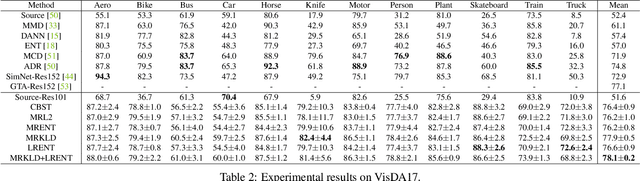
Recent advances in domain adaptation show that deep self-training presents a powerful means for unsupervised domain adaptation. These methods often involve an iterative process of predicting on target domain and then taking the confident predictions as pseudo-labels for retraining. However, since pseudo-labels can be noisy, self-training can put overconfident label belief on wrong classes, leading to deviated solutions with propagated errors. To address the problem, we propose a confidence regularized self-training (CRST) framework, formulated as regularized self-training. Our method treats pseudo-labels as continuous latent variables jointly optimized via alternating optimization. We propose two types of confidence regularization: label regularization (LR) and model regularization (MR). CRST-LR generates soft pseudo-labels while CRST-MR encourages the smoothness on network output. Extensive experiments on image classification and semantic segmentation show that CRSTs outperform their non-regularized counterpart with state-of-the-art performance. The code and models of this work are available at https://github.com/yzou2/CRST.
Simultaneous Edge Alignment and Learning
Oct 26, 2018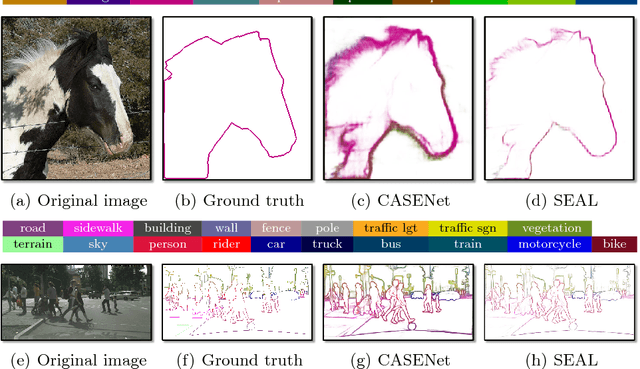



Edge detection is among the most fundamental vision problems for its role in perceptual grouping and its wide applications. Recent advances in representation learning have led to considerable improvements in this area. Many state of the art edge detection models are learned with fully convolutional networks (FCNs). However, FCN-based edge learning tends to be vulnerable to misaligned labels due to the delicate structure of edges. While such problem was considered in evaluation benchmarks, similar issue has not been explicitly addressed in general edge learning. In this paper, we show that label misalignment can cause considerably degraded edge learning quality, and address this issue by proposing a simultaneous edge alignment and learning framework. To this end, we formulate a probabilistic model where edge alignment is treated as latent variable optimization, and is learned end-to-end during network training. Experiments show several applications of this work, including improved edge detection with state of the art performance, and automatic refinement of noisy annotations.
Domain Adaptation for Semantic Segmentation via Class-Balanced Self-Training
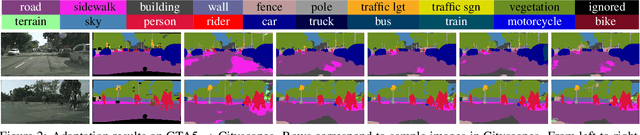
Oct 25, 2018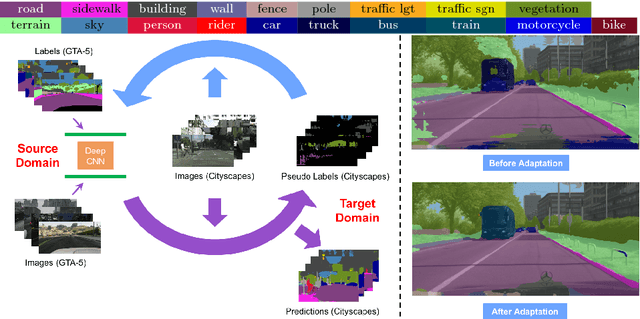
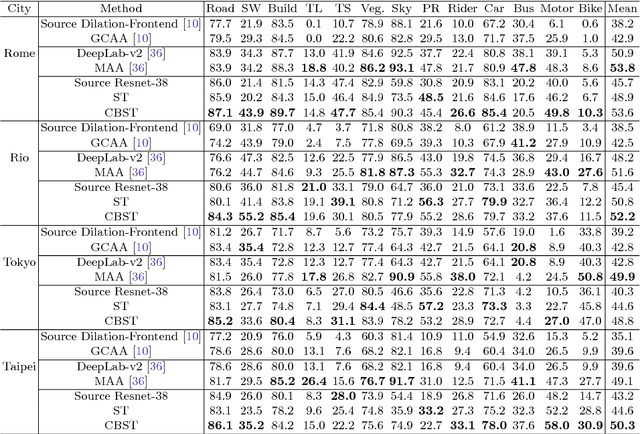
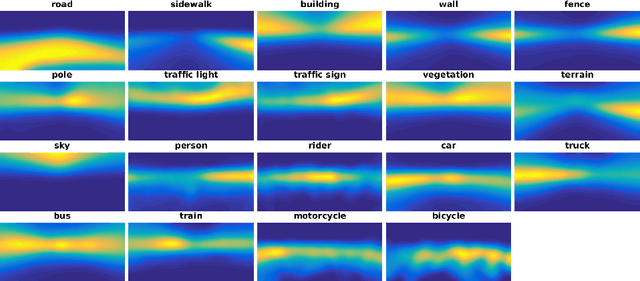
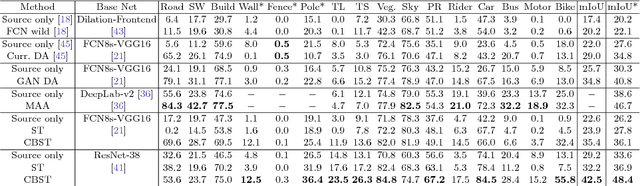
Recent deep networks achieved state of the art performance on a variety of semantic segmentation tasks. Despite such progress, these models often face challenges in real world `wild tasks' where large difference between labeled training/source data and unseen test/target data exists. In particular, such difference is often referred to as `domain gap', and could cause significantly decreased performance which cannot be easily remedied by further increasing the representation power. Unsupervised domain adaptation (UDA) seeks to overcome such problem without target domain labels. In this paper, we propose a novel UDA framework based on an iterative self-training procedure, where the problem is formulated as latent variable loss minimization, and can be solved by alternatively generating pseudo labels on target data and re-training the model with these labels. On top of self-training, we also propose a novel class-balanced self-training framework to avoid the gradual dominance of large classes on pseudo-label generation, and introduce spatial priors to refine generated labels. Comprehensive experiments show that the proposed methods achieve state of the art semantic segmentation performance under multiple major UDA settings.
Towards Multifocal Displays with Dense Focal Stacks
Sep 22, 2018
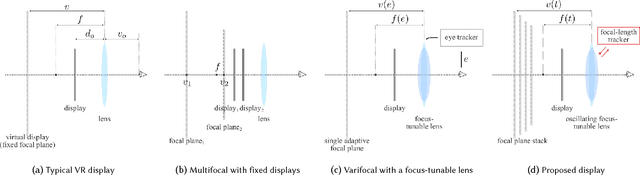
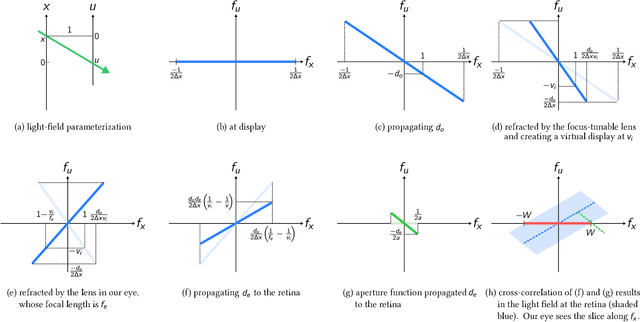
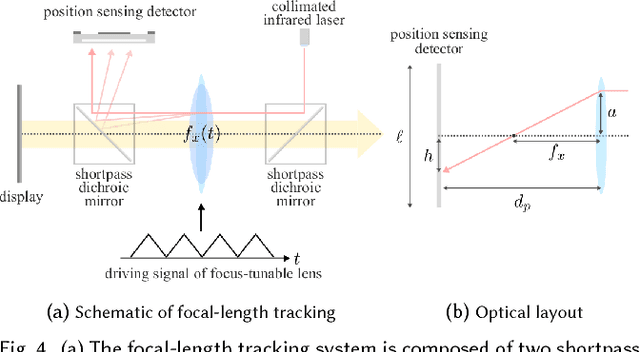
We present a virtual reality display that is capable of generating a dense collection of depth/focal planes. This is achieved by driving a focus-tunable lens to sweep a range of focal lengths at a high frequency and, subsequently, tracking the focal length precisely at microsecond time resolutions using an optical module. Precise tracking of the focal length, coupled with a high-speed display, enables our lab prototype to generate 1600 focal planes per second. This enables a novel first-of-its-kind virtual reality multifocal display that is capable of resolving the vergence-accommodation conflict endemic to today's displays.
One Network to Solve Them All --- Solving Linear Inverse Problems using Deep Projection Models
Mar 29, 2017
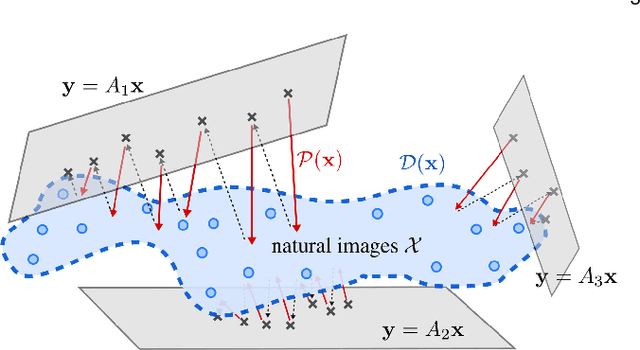
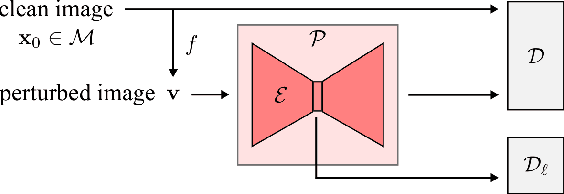
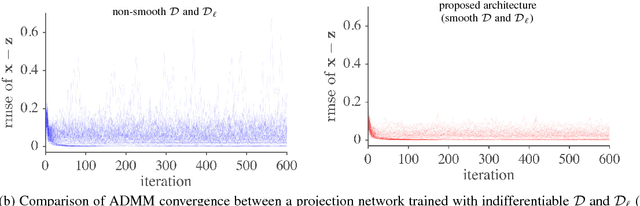
While deep learning methods have achieved state-of-the-art performance in many challenging inverse problems like image inpainting and super-resolution, they invariably involve problem-specific training of the networks. Under this approach, different problems require different networks. In scenarios where we need to solve a wide variety of problems, e.g., on a mobile camera, it is inefficient and costly to use these specially-trained networks. On the other hand, traditional methods using signal priors can be used in all linear inverse problems but often have worse performance on challenging tasks. In this work, we provide a middle ground between the two kinds of methods --- we propose a general framework to train a single deep neural network that solves arbitrary linear inverse problems. The proposed network acts as a proximal operator for an optimization algorithm and projects non-image signals onto the set of natural images defined by the decision boundary of a classifier. In our experiments, the proposed framework demonstrates superior performance over traditional methods using a wavelet sparsity prior and achieves comparable performance of specially-trained networks on tasks including compressive sensing and pixel-wise inpainting.
Zero-Aliasing Correlation Filters for Object Recognition
Nov 19, 2014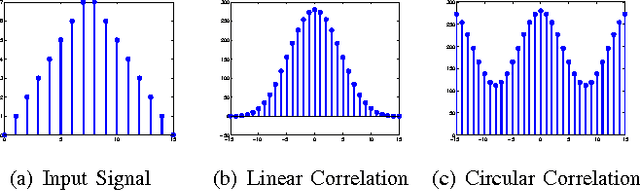

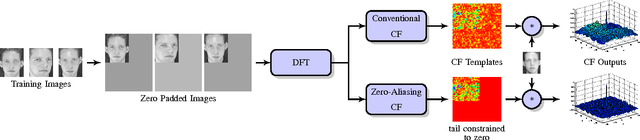
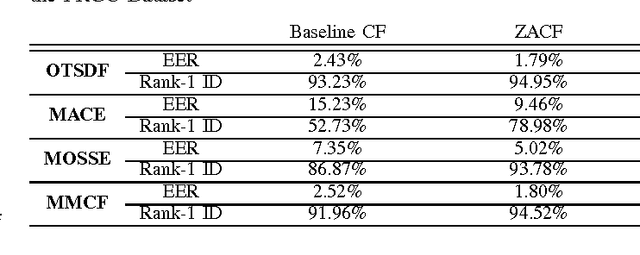
Correlation filters (CFs) are a class of classifiers that are attractive for object localization and tracking applications. Traditionally, CFs have been designed in the frequency domain using the discrete Fourier transform (DFT), where correlation is efficiently implemented. However, existing CF designs do not account for the fact that the multiplication of two DFTs in the frequency domain corresponds to a circular correlation in the time/spatial domain. Because this was previously unaccounted for, prior CF designs are not truly optimal, as their optimization criteria do not accurately quantify their optimization intention. In this paper, we introduce new zero-aliasing constraints that completely eliminate this aliasing problem by ensuring that the optimization criterion for a given CF corresponds to a linear correlation rather than a circular correlation. This means that previous CF designs can be significantly improved by this reformulation. We demonstrate the benefits of this new CF design approach with several important CFs. We present experimental results on diverse data sets and present solutions to the computational challenges associated with computing these CFs. Code for the CFs described in this paper and their respective zero-aliasing versions is available at http://vishnu.boddeti.net/projects/correlation-filters.html
Structured Hough Voting for Vision-based Highway Border Detection
Nov 18, 2014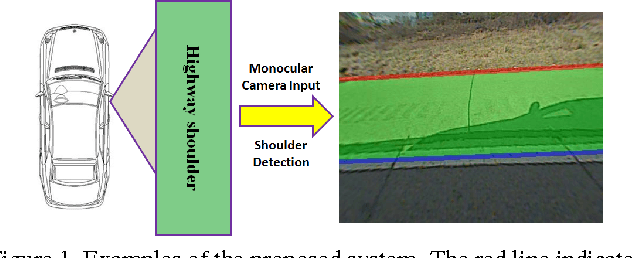
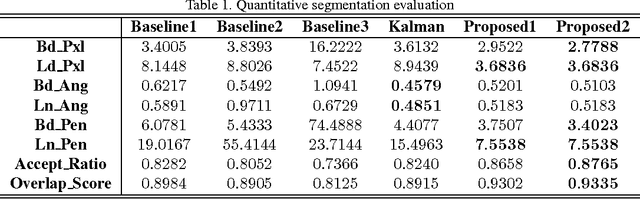

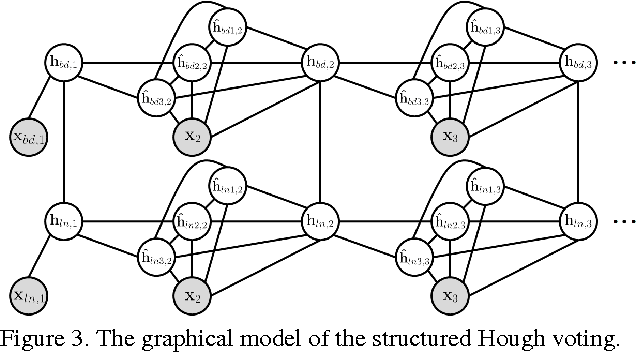
We propose a vision-based highway border detection algorithm using structured Hough voting. Our approach takes advantage of the geometric relationship between highway road borders and highway lane markings. It uses a strategy where a number of trained road border and lane marking detectors are triggered, followed by Hough voting to generate corresponding detection of the border and lane marking. Since the initially triggered detectors usually result in large number of positives, conventional frame-wise Hough voting is not able to always generate robust border and lane marking results. Therefore, we formulate this problem as a joint detection-and-tracking problem under the structured Hough voting model, where tracking refers to exploiting inter-frame structural information to stabilize the detection results. Both qualitative and quantitative evaluations show the superiority of the proposed structured Hough voting model over a number of baseline methods.