 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAD: Retrieval-Augmented Monocular Metric Depth Estimation for Underrepresented Classes
Feb 10, 2026Monocular Metric Depth Estimation (MMDE) is essential for physically intelligent systems, yet accurate depth estimation for underrepresented classes in complex scenes remains a persistent challenge. To address this, we propose RAD, a retrieval-augmented framework that approximates the benefits of multi-view stereo by utilizing retrieved neighbors as structural geometric proxies. Our method first employs an uncertainty-aware retrieval mechanism to identify low-confidence regions in the input and retrieve RGB-D context samples containing semantically similar content. We then process both the input and retrieved context via a dual-stream network and fuse them using a matched cross-attention module, which transfers geometric information only at reliable point correspondences. Evaluations on NYU Depth v2, KITTI, and Cityscapes demonstrate that RAD significantly outperforms state-of-the-art baselines on underrepresented classes, reducing relative absolute error by 29.2% on NYU Depth v2, 13.3% on KITTI, and 7.2% on Cityscapes, while maintaining competitive performance on standard in-domain benchmarks.
FOR: Finetuning for Object Level Open Vocabulary Image Retrieval
Dec 25, 2024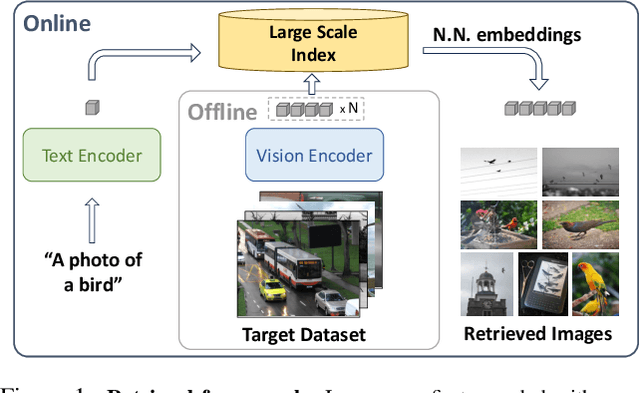
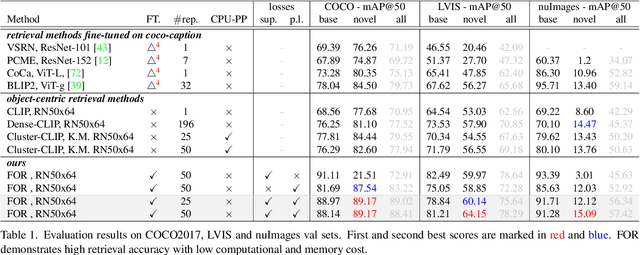
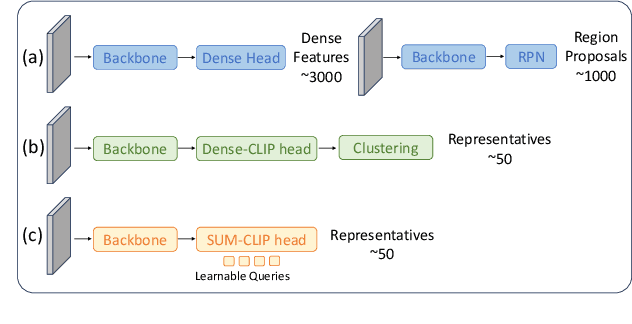
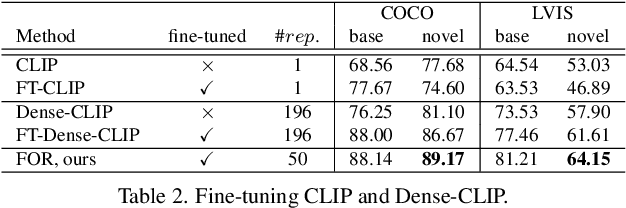
As working with large datasets becomes standard, the task of accurately retrieving images containing objects of interest by an open set textual query gains practical importance. The current leading approach utilizes a pre-trained CLIP model without any adaptation to the target domain, balancing accuracy and efficiency through additional post-processing. In this work, we propose FOR: Finetuning for Object-centric Open-vocabulary Image Retrieval, which allows finetuning on a target dataset using closed-set labels while keeping the visual-language association crucial for open vocabulary retrieval. FOR is based on two design elements: a specialized decoder variant of the CLIP head customized for the intended task, and its coupling within a multi-objective training framework. Together, these design choices result in a significant increase in accuracy, showcasing improvements of up to 8 mAP@50 points over SoTA across three datasets. Additionally, we demonstrate that FOR is also effective in a semi-supervised setting, achieving impressive results even when only a small portion of the dataset is labeled.
Object-Centric Open-Vocabulary Image-Retrieval with Aggregated Features
Sep 26, 2023



The task of open-vocabulary object-centric image retrieval involves the retrieval of images containing a specified object of interest, delineated by an open-set text query. As working on large image datasets becomes standard, solving this task efficiently has gained significant practical importance. Applications include targeted performance analysis of retrieved images using ad-hoc queries and hard example mining during training. Recent advancements in contrastive-based open vocabulary systems have yielded remarkable breakthroughs, facilitating large-scale open vocabulary image retrieval. However, these approaches use a single global embedding per image, thereby constraining the system's ability to retrieve images containing relatively small object instances. Alternatively, incorporating local embeddings from detection pipelines faces scalability challenges, making it unsuitable for retrieval from large databases. In this work, we present a simple yet effective approach to object-centric open-vocabulary image retrieval. Our approach aggregates dense embeddings extracted from CLIP into a compact representation, essentially combining the scalability of image retrieval pipelines with the object identification capabilities of dense detection methods. We show the effectiveness of our scheme to the task by achieving significantly better results than global feature approaches on three datasets, increasing accuracy by up to 15 mAP points. We further integrate our scheme into a large scale retrieval framework and demonstrate our method's advantages in terms of scalability and interpretability.
Polarimetric Imaging for Perception
May 24, 2023Autonomous driving and advanced driver-assistance systems rely on a set of sensors and algorithms to perform the appropriate actions and provide alerts as a function of the driving scene. Typically, the sensors include color cameras, radar, lidar and ultrasonic sensors. Strikingly however, although light polarization is a fundamental property of light, it is seldom harnessed for perception tasks. In this work we analyze the potential for improvement in perception tasks when using an RGB-polarimetric camera, as compared to an RGB camera. We examine monocular depth estimation and free space detection during the middle of the day, when polarization is independent of subject heading, and show that a quantifiable improvement can be achieved for both of them using state-of-the-art deep neural networks, with a minimum of architectural changes. We also present a new dataset composed of RGB-polarimetric images, lidar scans, GNSS / IMU readings and free space segmentations that further supports developing perception algorithms that take advantage of light polarization.
3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation
Nov 04, 2020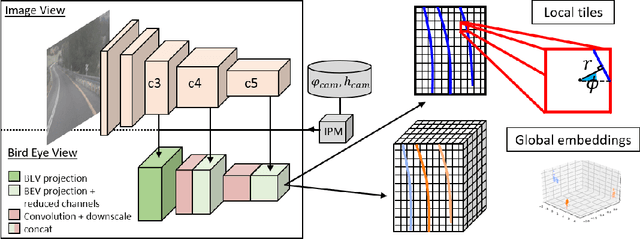

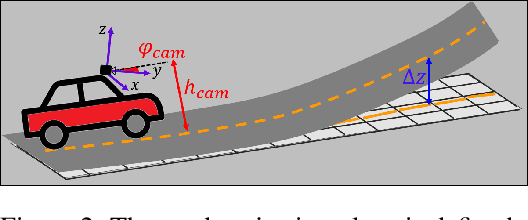
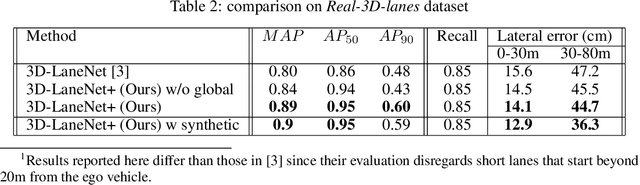
3D-LaneNet+ is a camera-based DNN method for anchor free 3D lane detection which is able to detect 3d lanes of any arbitrary topology such as splits, merges, as well as short and perpendicular lanes. We follow recently proposed 3D-LaneNet, and extend it to enable the detection of these previously unsupported lane topologies. Our output representation is an anchor free, semi-local tile representation that breaks down lanes into simple lane segments whose parameters can be learnt. In addition we learn, per lane instance, feature embedding that reasons for the global connectivity of locally detected segments to form full 3d lanes. This combination allows 3D-LaneNet+ to avoid using lane anchors, non-maximum suppression, and lane model fitting as in the original 3D-LaneNet. We demonstrate the efficacy of 3D-LaneNet+ using both synthetic and real world data. Results show significant improvement relative to the original 3D-LaneNet that can be attributed to better generalization to complex lane topologies, curvatures and surface geometries.
* arXiv admin note: substantial text overlap with arXiv:2003.05257
Synthetic-to-Real Domain Adaptation for Lane Detection
Jul 08, 2020
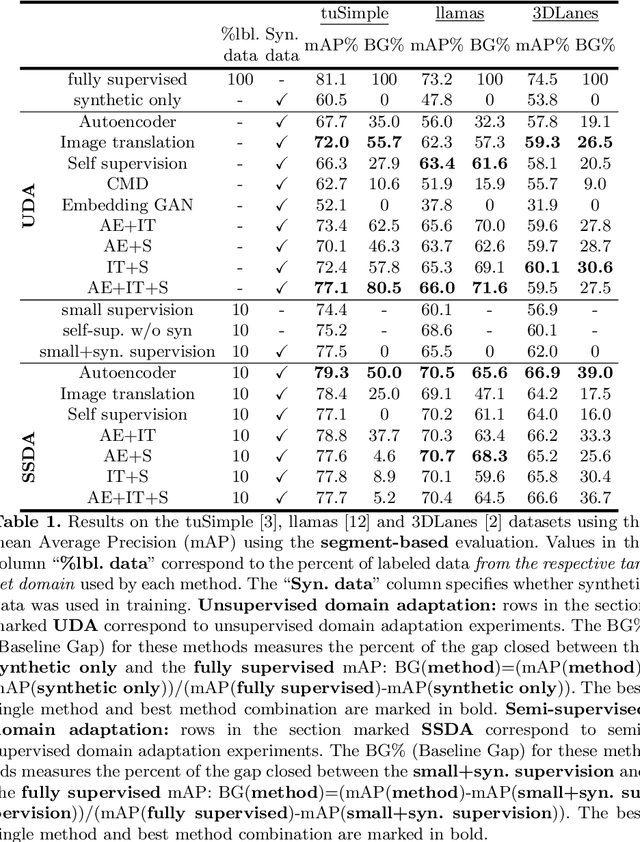
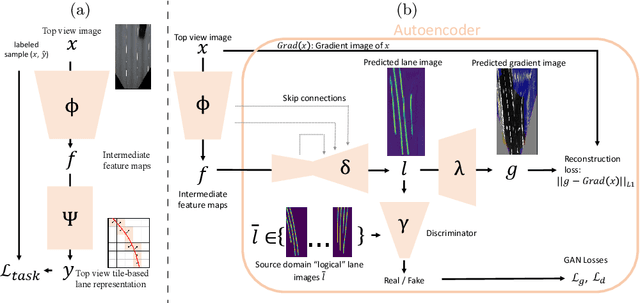
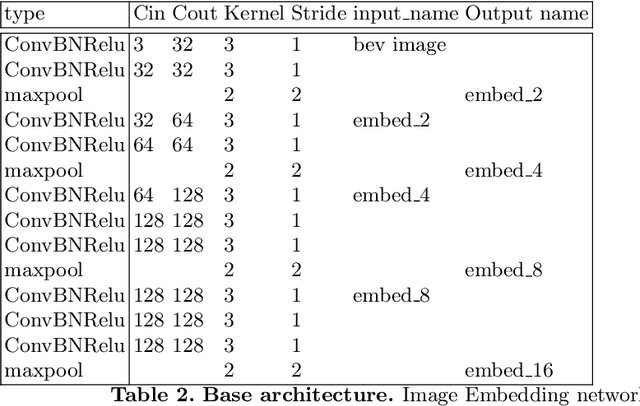
Accurate lane detection, a crucial enabler for autonomous driving, currently relies on obtaining a large and diverse labeled training dataset. In this work, we explore learning from abundant, randomly generated synthetic data, together with unlabeled or partially labeled target domain data, instead. Randomly generated synthetic data has the advantage of controlled variability in the lane geometry and lighting, but it is limited in terms of photo-realism. This poses the challenge of adapting models learned on the unrealistic synthetic domain to real images. To this end we develop a novel autoencoder-based approach that uses synthetic labels unaligned with particular images for adapting to target domain data. In addition, we explore existing domain adaptation approaches, such as image translation and self-supervision, and adjust them to the lane detection task. We test all approaches in the unsupervised domain adaptation setting in which no target domain labels are available and in the semi-supervised setting in which a small portion of the target images are labeled. In extensive experiments using three different datasets, we demonstrate the possibility to save costly target domain labeling efforts. For example, using our proposed autoencoder approach on the llamas and tuSimple lane datasets, we can almost recover the fully supervised accuracy with only 10% of the labeled data. In addition, our autoencoder approach outperforms all other methods in the semi-supervised domain adaptation scenario.
Semi-Local 3D Lane Detection and Uncertainty Estimation
Mar 11, 2020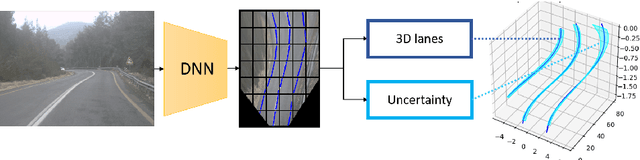
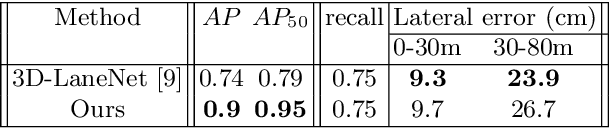

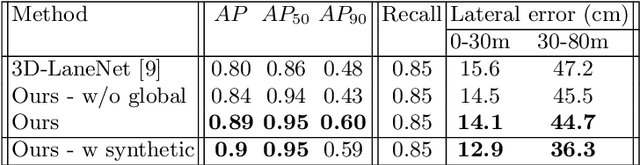
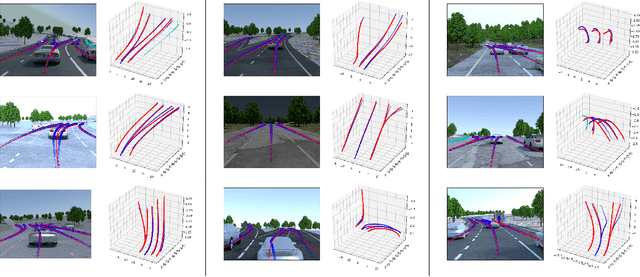
We propose a novel camera-based DNN method for 3D lane detection with uncertainty estimation. Our method is based on a semi-local, BEV, tile representation that breaks down lanes into simple lane segments. It combines learning a parametric model for the segments along with a deep feature embedding that is then used to cluster segment together into full lanes. This combination allows our method to generalize to complex lane topologies, curvatures and surface geometries. Additionally, our method is the first to output a learning based uncertainty estimation for the lane detection task. The efficacy of our method is demonstrated in extensive experiments achieving state-of-the-art results for camera-based 3D lane detection, while also showing our ability to generalize to complex topologies, curvatures and road geometries as well as to different cameras. We also demonstrate how our uncertainty estimation aligns with the empirical error statistics indicating that it is well calibrated and truly reflects the detection noise.
Evaluating and Calibrating Uncertainty Prediction in Regression Tasks
May 30, 2019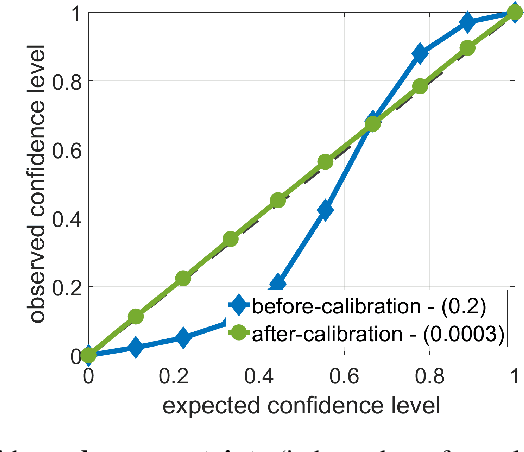
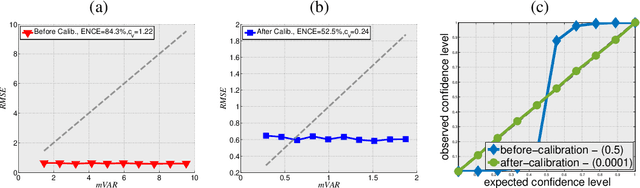
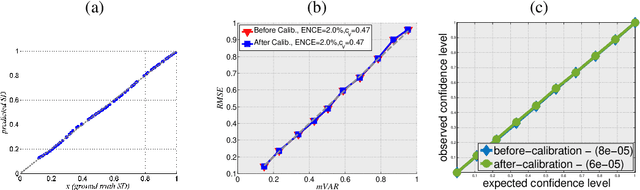

Predicting not only the target but also an accurate measure of uncertainty is important for many applications and in particular safety-critical ones. In this work we study the calibration of uncertainty prediction for regression tasks which often arise in real-world systems. We show that the existing approach for evaluating the calibration of a regression uncertainty [Kuleshov et al. 2018] has severe limitations in distinguishing informative from non-informative uncertainty predictions. We propose a new evaluation method that escapes this caveat using a simple histogram-based approach inspired by reliability diagrams used in classification tasks. Our method clusters examples with similar uncertainty prediction and compares the prediction with the empirical uncertainty on these examples. We also propose a simple scaling-based calibration that preforms well in our experimental tests. We show results on both a synthetic, controlled problem and on the object detection bounding-box regression task using the COCO and KITTI datasets.
3D-LaneNet: end-to-end 3D multiple lane detection
Nov 27, 2018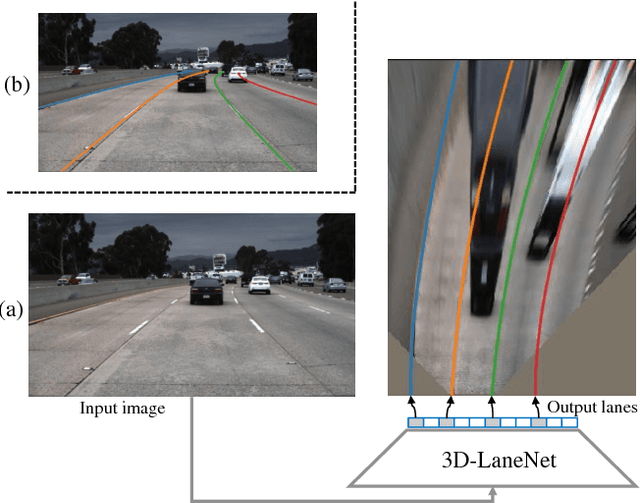
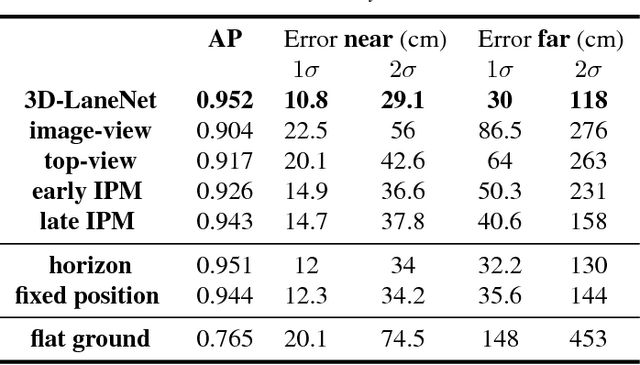

We introduce a network that directly predicts the 3D layout of lanes in a road scene from a single image. This work marks a first attempt to address this task with on-board sensing instead of relying on pre-mapped environments. Our network architecture, 3D-LaneNet, applies two new concepts: intra-network inverse-perspective mapping (IPM) and anchor-based lane representation. The intra-network IPM projection facilitates a dual-representation information flow in both regular image-view and top-view. An anchor-per-column output representation enables our end-to-end approach replacing common heuristics such as clustering and outlier rejection. In addition, our approach explicitly handles complex situations such as lane merges and splits. Promising results are shown on a new 3D lane synthetic dataset. For comparison with existing methods, we verify our approach on the image-only tuSimple lane detection benchmark and reach competitive performance.
Learning Discrete Weights Using the Local Reparameterization Trick
Feb 02, 2018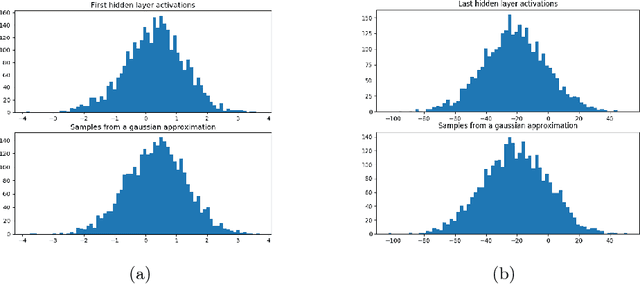
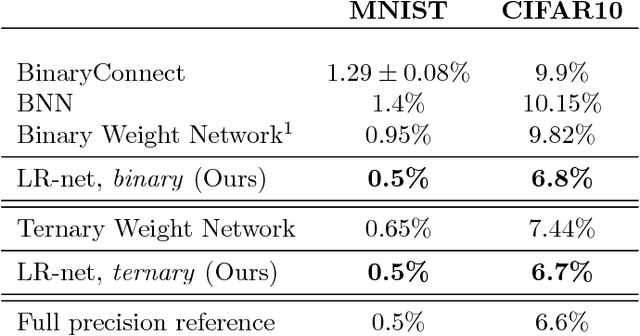
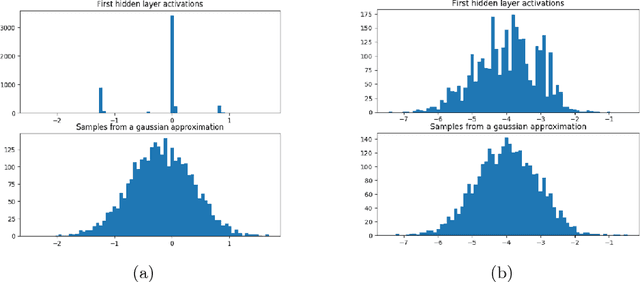
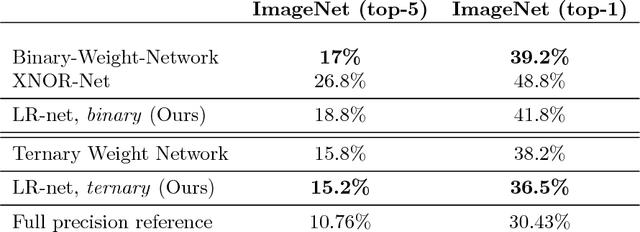
Recent breakthroughs in computer vision make use of large deep neural networks, utilizing the substantial speedup offered by GPUs. For applications running on limited hardware, however, high precision real-time processing can still be a challenge. One approach to solving this problem is training networks with binary or ternary weights, thus removing the need to calculate multiplications and significantly reducing memory size. In this work, we introduce LR-nets (Local reparameterization networks), a new method for training neural networks with discrete weights using stochastic parameters. We show how a simple modification to the local reparameterization trick, previously used to train Gaussian distributed weights, enables the training of discrete weights. Using the proposed training we test both binary and ternary models on MNIST, CIFAR-10 and ImageNet benchmarks and reach state-of-the-art results on most experiments.