 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation
Nov 04, 2020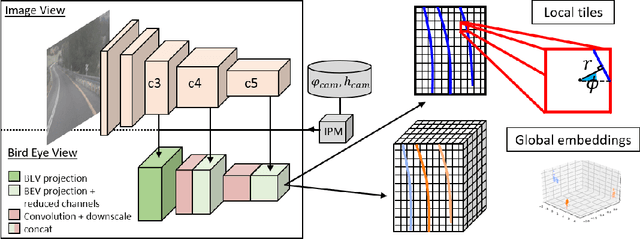

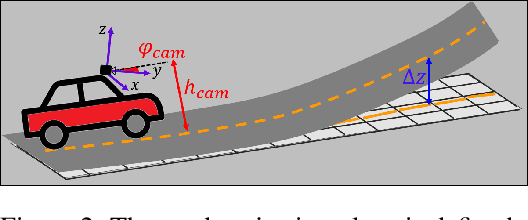
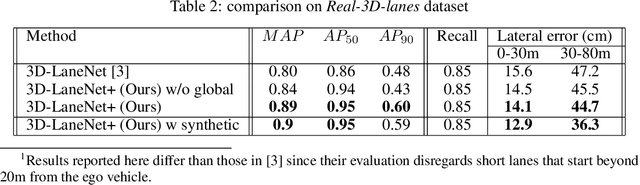
3D-LaneNet+ is a camera-based DNN method for anchor free 3D lane detection which is able to detect 3d lanes of any arbitrary topology such as splits, merges, as well as short and perpendicular lanes. We follow recently proposed 3D-LaneNet, and extend it to enable the detection of these previously unsupported lane topologies. Our output representation is an anchor free, semi-local tile representation that breaks down lanes into simple lane segments whose parameters can be learnt. In addition we learn, per lane instance, feature embedding that reasons for the global connectivity of locally detected segments to form full 3d lanes. This combination allows 3D-LaneNet+ to avoid using lane anchors, non-maximum suppression, and lane model fitting as in the original 3D-LaneNet. We demonstrate the efficacy of 3D-LaneNet+ using both synthetic and real world data. Results show significant improvement relative to the original 3D-LaneNet that can be attributed to better generalization to complex lane topologies, curvatures and surface geometries.
* arXiv admin note: substantial text overlap with arXiv:2003.05257
Synthetic-to-Real Domain Adaptation for Lane Detection
Jul 08, 2020
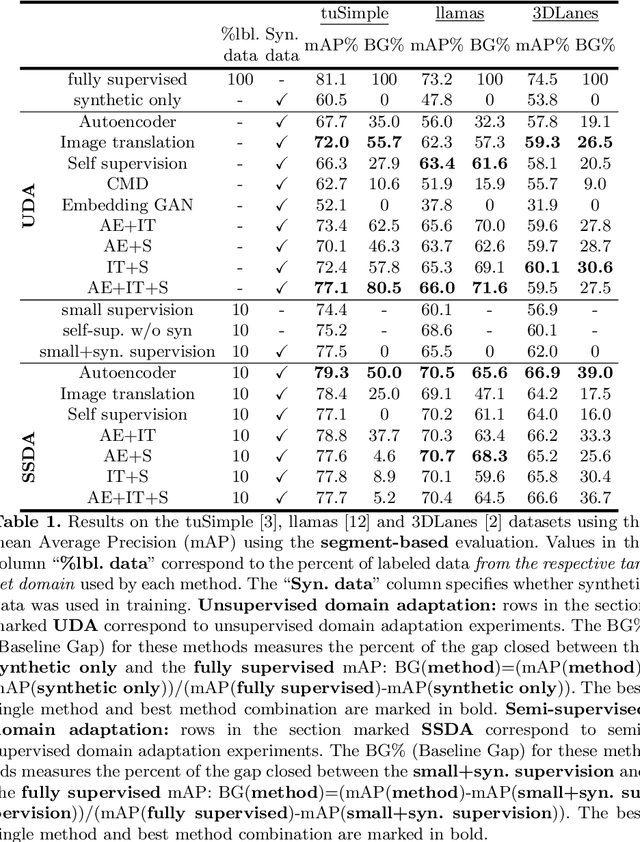
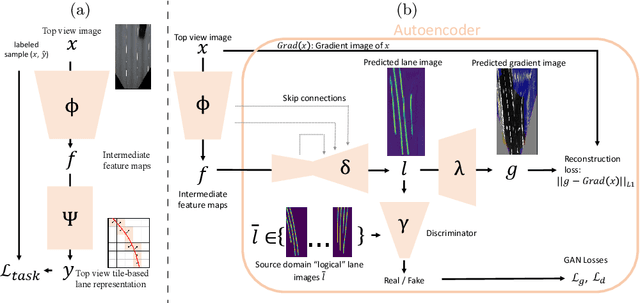
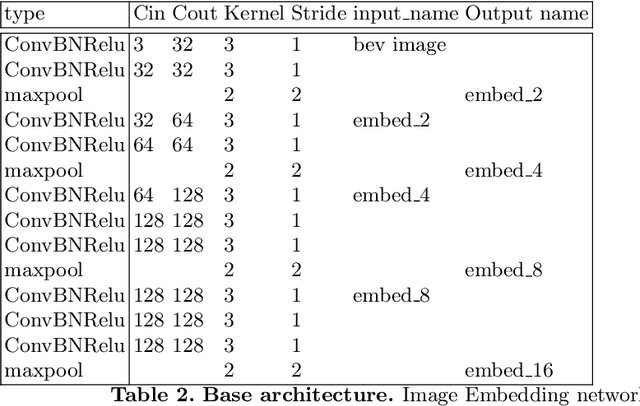
Accurate lane detection, a crucial enabler for autonomous driving, currently relies on obtaining a large and diverse labeled training dataset. In this work, we explore learning from abundant, randomly generated synthetic data, together with unlabeled or partially labeled target domain data, instead. Randomly generated synthetic data has the advantage of controlled variability in the lane geometry and lighting, but it is limited in terms of photo-realism. This poses the challenge of adapting models learned on the unrealistic synthetic domain to real images. To this end we develop a novel autoencoder-based approach that uses synthetic labels unaligned with particular images for adapting to target domain data. In addition, we explore existing domain adaptation approaches, such as image translation and self-supervision, and adjust them to the lane detection task. We test all approaches in the unsupervised domain adaptation setting in which no target domain labels are available and in the semi-supervised setting in which a small portion of the target images are labeled. In extensive experiments using three different datasets, we demonstrate the possibility to save costly target domain labeling efforts. For example, using our proposed autoencoder approach on the llamas and tuSimple lane datasets, we can almost recover the fully supervised accuracy with only 10% of the labeled data. In addition, our autoencoder approach outperforms all other methods in the semi-supervised domain adaptation scenario.
Semi-Local 3D Lane Detection and Uncertainty Estimation
Mar 11, 2020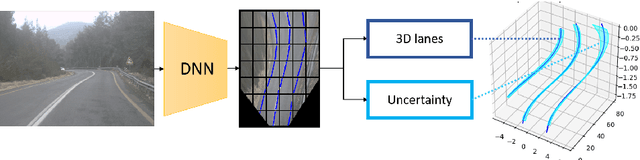
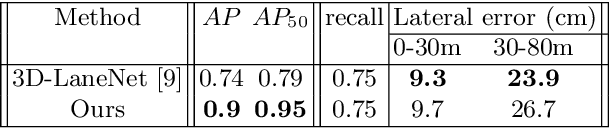

We propose a novel camera-based DNN method for 3D lane detection with uncertainty estimation. Our method is based on a semi-local, BEV, tile representation that breaks down lanes into simple lane segments. It combines learning a parametric model for the segments along with a deep feature embedding that is then used to cluster segment together into full lanes. This combination allows our method to generalize to complex lane topologies, curvatures and surface geometries. Additionally, our method is the first to output a learning based uncertainty estimation for the lane detection task. The efficacy of our method is demonstrated in extensive experiments achieving state-of-the-art results for camera-based 3D lane detection, while also showing our ability to generalize to complex topologies, curvatures and road geometries as well as to different cameras. We also demonstrate how our uncertainty estimation aligns with the empirical error statistics indicating that it is well calibrated and truly reflects the detection noise.
Performance Advantages of Deep Neural Networks for Angle of Arrival Estimation
Feb 17, 2019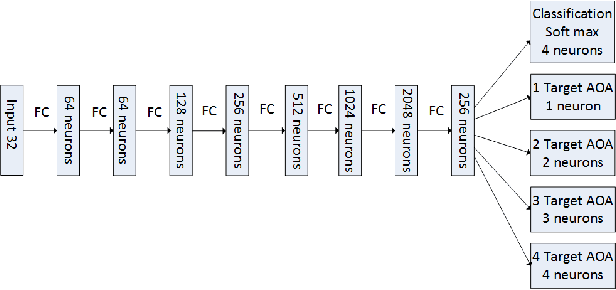
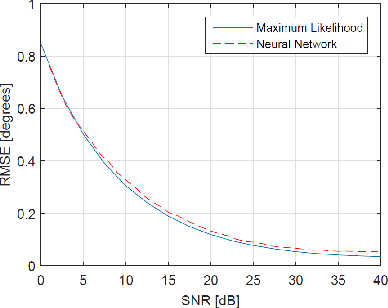


The problem of estimating the number of sources and their angles of arrival from a single antenna array observation has been an active area of research in the signal processing community for the last few decades. When the number of sources is large, the maximum likelihood estimator is intractable due to its very high complexity, and therefore alternative signal processing methods have been developed with some performance loss. In this paper, we apply a deep neural network (DNN) approach to the problem and analyze its advantages with respect to signal processing algorithms. We show that an appropriate designed network can attain the maximum likelihood performance with feasible complexity and outperform other feasible signal processing estimation methods over various signal to noise ratios and array response inaccuracies.
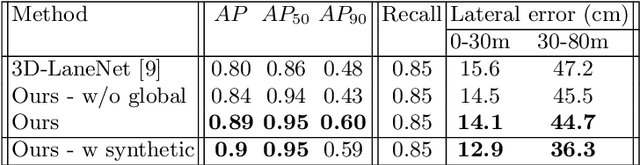
3D-LaneNet: end-to-end 3D multiple lane detection
Nov 27, 2018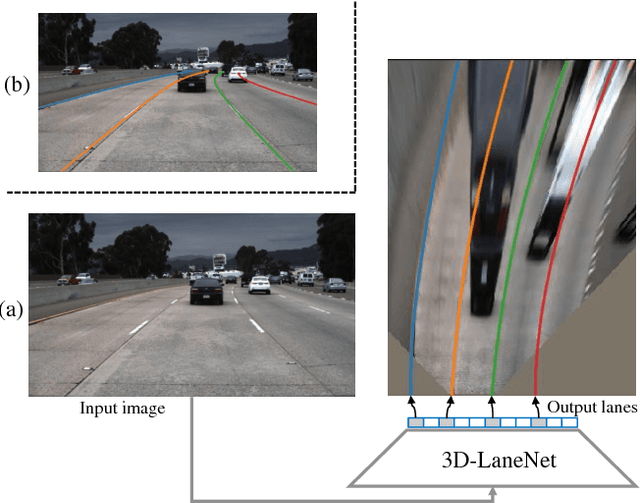
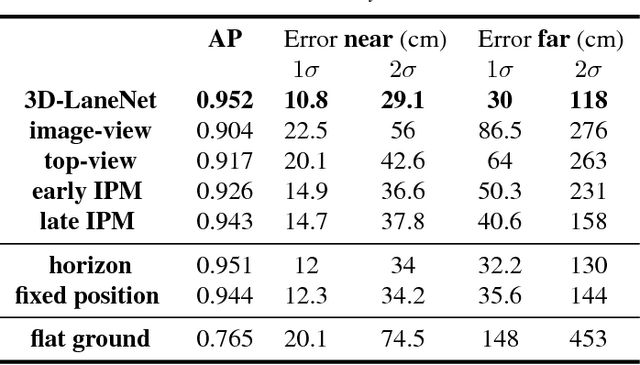
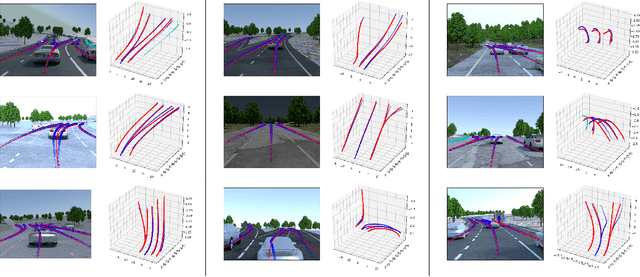

We introduce a network that directly predicts the 3D layout of lanes in a road scene from a single image. This work marks a first attempt to address this task with on-board sensing instead of relying on pre-mapped environments. Our network architecture, 3D-LaneNet, applies two new concepts: intra-network inverse-perspective mapping (IPM) and anchor-based lane representation. The intra-network IPM projection facilitates a dual-representation information flow in both regular image-view and top-view. An anchor-per-column output representation enables our end-to-end approach replacing common heuristics such as clustering and outlier rejection. In addition, our approach explicitly handles complex situations such as lane merges and splits. Promising results are shown on a new 3D lane synthetic dataset. For comparison with existing methods, we verify our approach on the image-only tuSimple lane detection benchmark and reach competitive performance.