 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-LaneNet+: Anchor Free Lane Detection using a Semi-Local Representation
Nov 04, 2020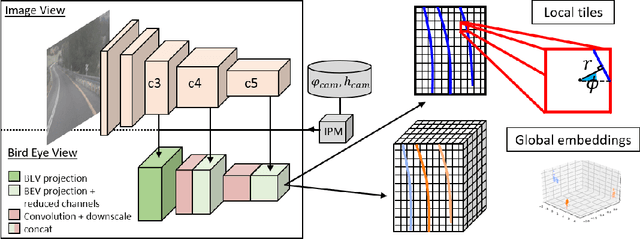

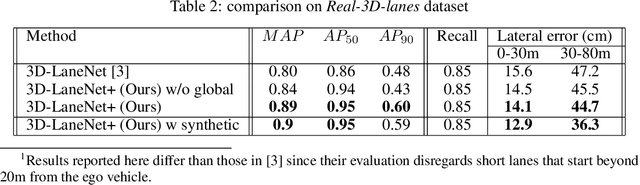
3D-LaneNet+ is a camera-based DNN method for anchor free 3D lane detection which is able to detect 3d lanes of any arbitrary topology such as splits, merges, as well as short and perpendicular lanes. We follow recently proposed 3D-LaneNet, and extend it to enable the detection of these previously unsupported lane topologies. Our output representation is an anchor free, semi-local tile representation that breaks down lanes into simple lane segments whose parameters can be learnt. In addition we learn, per lane instance, feature embedding that reasons for the global connectivity of locally detected segments to form full 3d lanes. This combination allows 3D-LaneNet+ to avoid using lane anchors, non-maximum suppression, and lane model fitting as in the original 3D-LaneNet. We demonstrate the efficacy of 3D-LaneNet+ using both synthetic and real world data. Results show significant improvement relative to the original 3D-LaneNet that can be attributed to better generalization to complex lane topologies, curvatures and surface geometries.
* arXiv admin note: substantial text overlap with arXiv:2003.05257
Semi-Local 3D Lane Detection and Uncertainty Estimation
Mar 11, 2020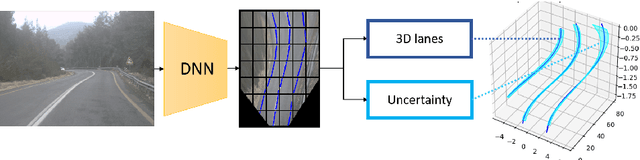
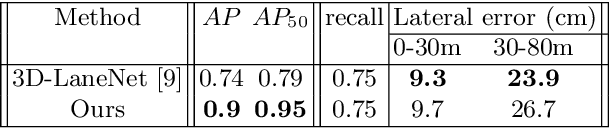

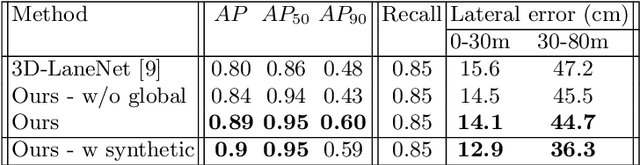
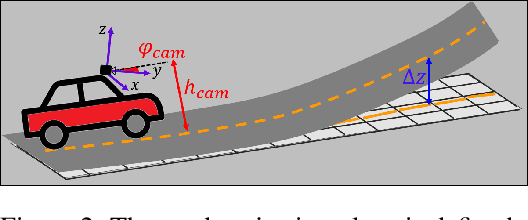
We propose a novel camera-based DNN method for 3D lane detection with uncertainty estimation. Our method is based on a semi-local, BEV, tile representation that breaks down lanes into simple lane segments. It combines learning a parametric model for the segments along with a deep feature embedding that is then used to cluster segment together into full lanes. This combination allows our method to generalize to complex lane topologies, curvatures and surface geometries. Additionally, our method is the first to output a learning based uncertainty estimation for the lane detection task. The efficacy of our method is demonstrated in extensive experiments achieving state-of-the-art results for camera-based 3D lane detection, while also showing our ability to generalize to complex topologies, curvatures and road geometries as well as to different cameras. We also demonstrate how our uncertainty estimation aligns with the empirical error statistics indicating that it is well calibrated and truly reflects the detection noise.
Monocular 3D Object Detection in Cylindrical Images from Fisheye Cameras
Mar 08, 2020



Detecting objects in 3D from a monocular camera has been successfully demonstrated using various methods based on convolutional neural networks. These methods have been demonstrated on rectilinear perspective images equivalent to being taken by a pinhole camera, whose geometry is explicitly or implicitly exploited. Such methods fail in images with alternative projections, such as those acquired by fisheye cameras, even when provided with a labeled training set of fisheye images and 3D bounding boxes. In this work, we show how to adapt existing 3D object detection methods to images from fisheye cameras, including in the case that no labeled fisheye data is available for training. We significantly outperform existing art on a benchmark of synthetic data, and we also experiment with an internal dataset of real fisheye images.
Self Supervised Occupancy Grid Learning from Sparse Radar for Autonomous Driving
Mar 31, 2019
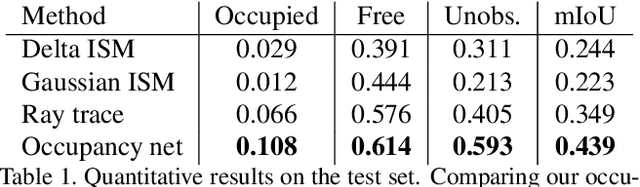

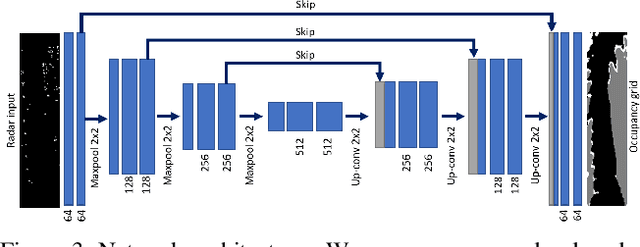
Occupancy grid mapping is an important component of autonomous vehicle perception. It encapsulates information of the drivable area, road obstacles and enables safe autonomous driving. To this end, radars are becoming widely used due to their long range sensing, low cost, and robustness to severe weather conditions. Despite recent advances in deep learning technology, occupancy grid mapping from radar data is still mostly done using classical filtering approaches. In this work, we propose a data driven approach for learning an inverse sensor model used for occupancy grid mapping from clustered radar data. This task is very challenging due to data sparsity and noise characteristics of the radar sensor. The problem is formulated as a semantic segmentation task and we show how it can be learned in a self-supervised manner using lidar data for generating ground truth. We show both qualitatively and quantitatively that our learned occupancy net outperforms classic methods by a large margin using the recently released NuScenes real-world driving data.