 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonocular 3D Object Detection in Cylindrical Images from Fisheye Cameras
Mar 08, 2020



Detecting objects in 3D from a monocular camera has been successfully demonstrated using various methods based on convolutional neural networks. These methods have been demonstrated on rectilinear perspective images equivalent to being taken by a pinhole camera, whose geometry is explicitly or implicitly exploited. Such methods fail in images with alternative projections, such as those acquired by fisheye cameras, even when provided with a labeled training set of fisheye images and 3D bounding boxes. In this work, we show how to adapt existing 3D object detection methods to images from fisheye cameras, including in the case that no labeled fisheye data is available for training. We significantly outperform existing art on a benchmark of synthetic data, and we also experiment with an internal dataset of real fisheye images.
A Greedy Approach to $\ell_{0,\infty}$ Based Convolutional Sparse Coding
Dec 26, 2018
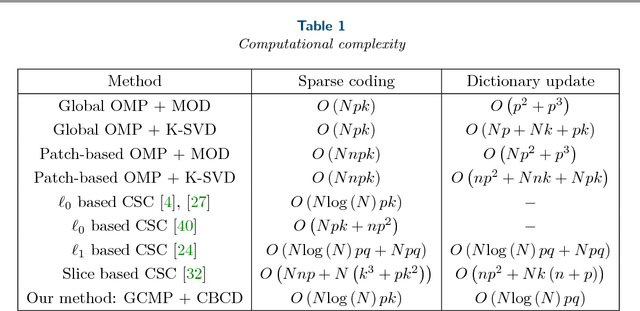
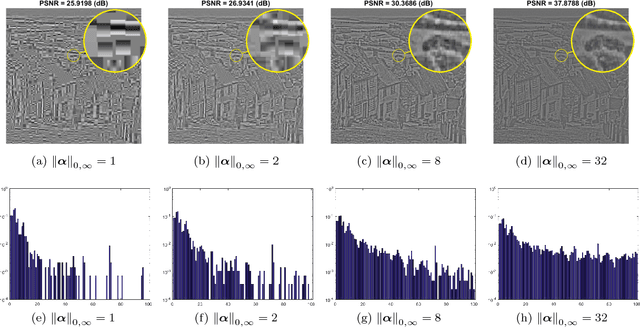
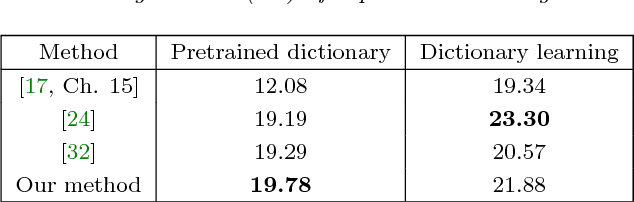
Sparse coding techniques for image processing traditionally rely on a processing of small overlapping patches separately followed by averaging. This has the disadvantage that the reconstructed image no longer obeys the sparsity prior used in the processing. For this purpose convolutional sparse coding has been introduced, where a shift-invariant dictionary is used and the sparsity of the recovered image is maintained. Most such strategies target the $\ell_0$ "norm" or the $\ell_1$ norm of the whole image, which may create an imbalanced sparsity across various regions in the image. In order to face this challenge, the $\ell_{0,\infty}$ "norm" has been proposed as an alternative that "operates locally while thinking globally". The approaches taken for tackling the non-convexity of these optimization problems have been either using a convex relaxation or local pursuit algorithms. In this paper, we present an efficient greedy method for sparse coding and dictionary learning, which is specifically tailored to $\ell_{0,\infty}$, and is based on matching pursuit. We demonstrate the usage of our approach in salt-and-pepper noise removal and image inpainting. A code package which reproduces the experiments presented in this work is available at https://web.eng.tau.ac.il/~raja
From Principal Subspaces to Principal Components with Linear Autoencoders
Aug 25, 2018



The autoencoder is an effective unsupervised learning model which is widely used in deep learning. It is well known that an autoencoder with a single fully-connected hidden layer, a linear activation function and a squared error cost function trains weights that span the same subspace as the one spanned by the principal component loading vectors, but that they are not identical to the loading vectors. In this paper, we show how to recover the loading vectors from the autoencoder weights.