 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMembership Inference Attack Using Self Influence Functions
May 26, 2022
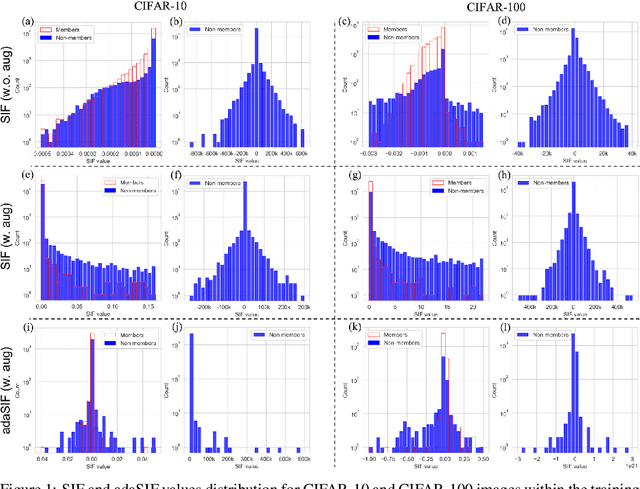
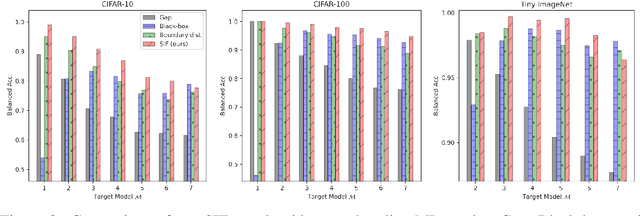
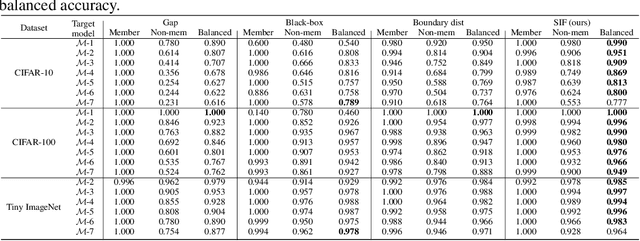
Member inference (MI) attacks aim to determine if a specific data sample was used to train a machine learning model. Thus, MI is a major privacy threat to models trained on private sensitive data, such as medical records. In MI attacks one may consider the black-box settings, where the model's parameters and activations are hidden from the adversary, or the white-box case where they are available to the attacker. In this work, we focus on the latter and present a novel MI attack for it that employs influence functions, or more specifically the samples' self-influence scores, to perform the MI prediction. We evaluate our attack on CIFAR-10, CIFAR-100, and Tiny ImageNet datasets, using versatile architectures such as AlexNet, ResNet, and DenseNet. Our attack method achieves new state-of-the-art results for both training with and without data augmentations. Code is available at https://github.com/giladcohen/sif_mi_attack.
Generative Adversarial Networks
Mar 01, 2022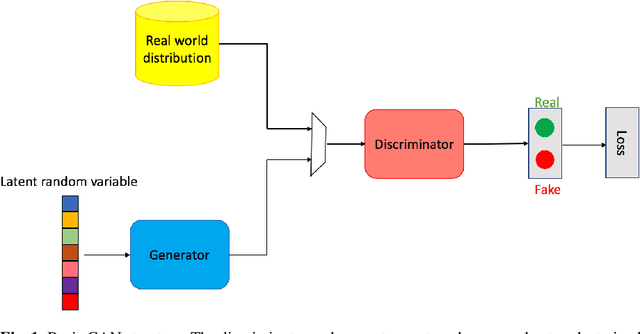

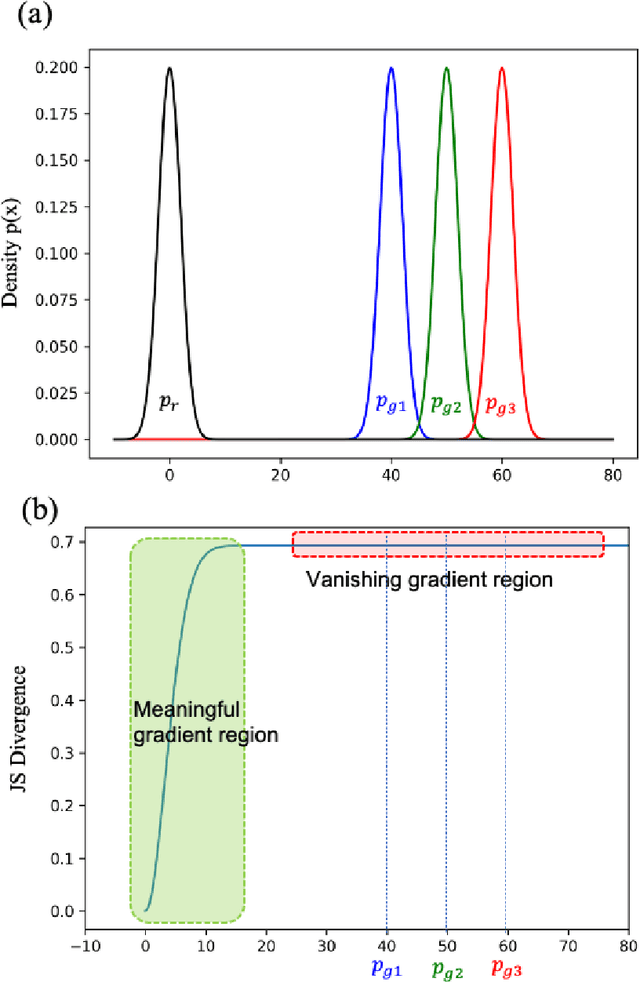
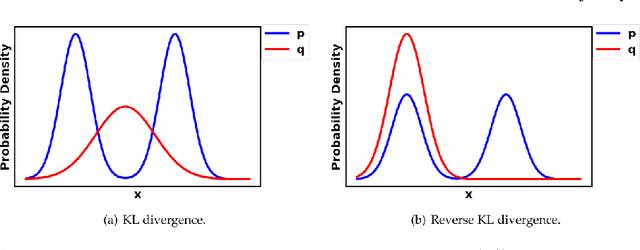
Generative Adversarial Networks (GANs) are very popular frameworks for generating high-quality data, and are immensely used in both the academia and industry in many domains. Arguably, their most substantial impact has been in the area of computer vision, where they achieve state-of-the-art image generation. This chapter gives an introduction to GANs, by discussing their principle mechanism and presenting some of their inherent problems during training and evaluation. We focus on these three issues: (1) mode collapse, (2) vanishing gradients, and (3) generation of low-quality images. We then list some architecture-variant and loss-variant GANs that remedy the above challenges. Lastly, we present two utilization examples of GANs for real-world applications: Data augmentation and face images generation.
KATANA: Simple Post-Training Robustness Using Test Time Augmentations
Sep 16, 2021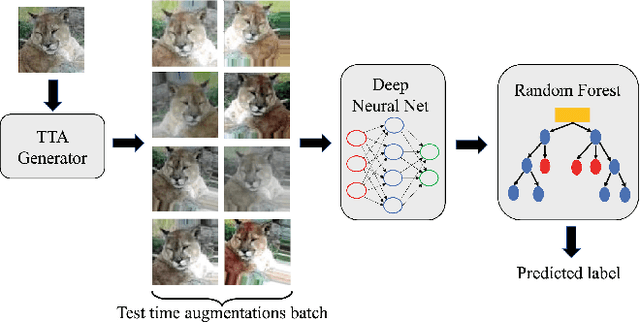
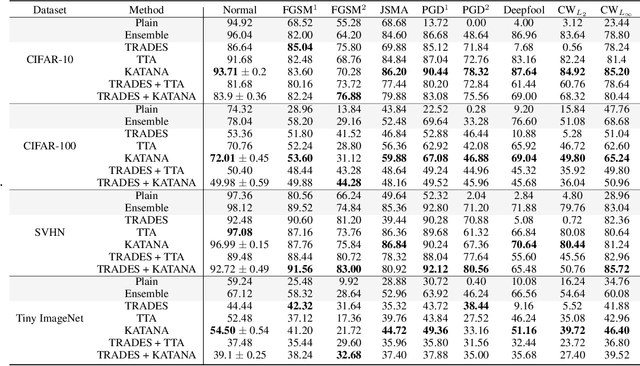

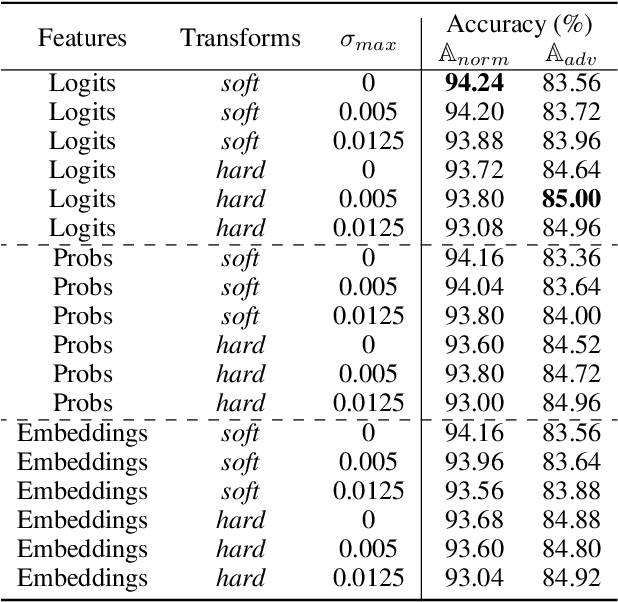
Although Deep Neural Networks (DNNs) achieve excellent performance on many real-world tasks, they are highly vulnerable to adversarial attacks. A leading defense against such attacks is adversarial training, a technique in which a DNN is trained to be robust to adversarial attacks by introducing adversarial noise to its input. This procedure is effective but must be done during the training phase. In this work, we propose a new simple and easy-to-use technique, KATANA, for robustifying an existing pretrained DNN without modifying its weights. For every image, we generate N randomized Test Time Augmentations (TTAs) by applying diverse color, blur, noise, and geometric transforms. Next, we utilize the DNN's logits output to train a simple random forest classifier to predict the real class label. Our strategy achieves state-of-the-art adversarial robustness on diverse attacks with minimal compromise on the natural images' classification. We test KATANA also against two adaptive white-box attacks and it shows excellent results when combined with adversarial training. Code is available in https://github.com/giladcohen/KATANA.
Detecting Adversarial Samples Using Influence Functions and Nearest Neighbors
Sep 15, 2019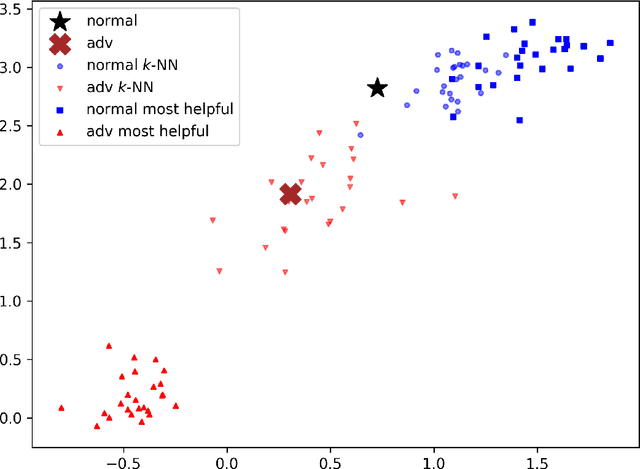
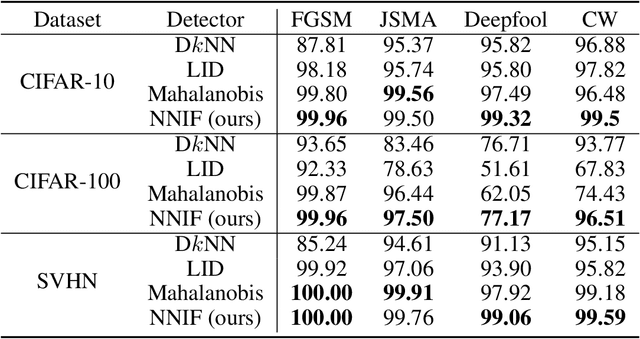
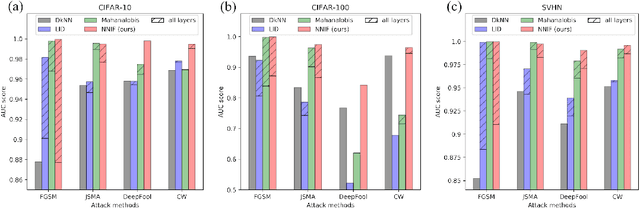

Deep neural networks (DNNs) are notorious for their vulnerability to adversarial attacks, which are small perturbations added to their input images to mislead their prediction. Detection of adversarial examples is, therefore, a fundamental requirement for robust classification frameworks. In this work, we present a method for detecting such adversarial attacks, which is suitable for any pre-trained neural network classifier. We use influence functions to measure the impact of every training sample on the validation set data. From the influence scores, we find the most supportive training samples for any given validation example. A k-nearest neighbor (k-NN) model fitted on the DNN's activation layers is employed to search for the ranking of these supporting training samples. We observe that these samples are highly correlated with the nearest neighbors of the normal inputs, while this correlation is much weaker for adversarial inputs. We train an adversarial detector using the k-NN ranks and distances and show that it successfully distinguishes adversarial examples, getting state-of-the-art results on four attack methods with three datasets.
Self Supervised Occupancy Grid Learning from Sparse Radar for Autonomous Driving
Mar 31, 2019
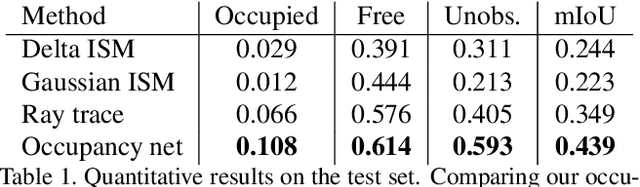

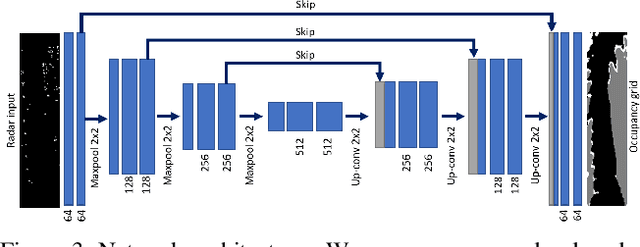
Occupancy grid mapping is an important component of autonomous vehicle perception. It encapsulates information of the drivable area, road obstacles and enables safe autonomous driving. To this end, radars are becoming widely used due to their long range sensing, low cost, and robustness to severe weather conditions. Despite recent advances in deep learning technology, occupancy grid mapping from radar data is still mostly done using classical filtering approaches. In this work, we propose a data driven approach for learning an inverse sensor model used for occupancy grid mapping from clustered radar data. This task is very challenging due to data sparsity and noise characteristics of the radar sensor. The problem is formulated as a semantic segmentation task and we show how it can be learned in a self-supervised manner using lidar data for generating ground truth. We show both qualitatively and quantitatively that our learned occupancy net outperforms classic methods by a large margin using the recently released NuScenes real-world driving data.
DNN or $k$-NN: That is the Generalize vs. Memorize Question
May 28, 2018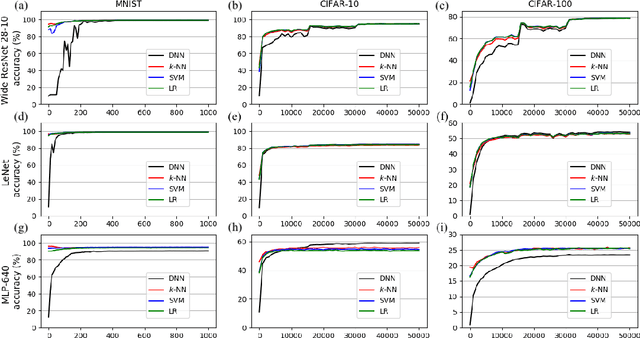
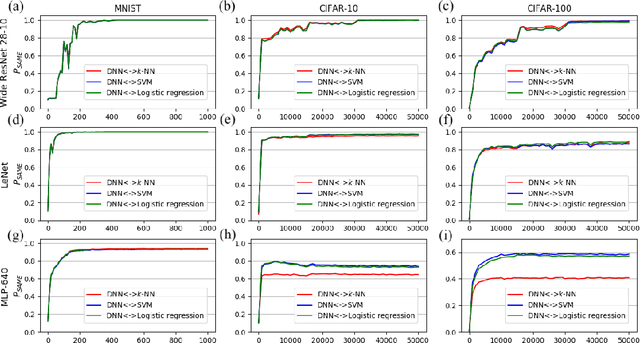
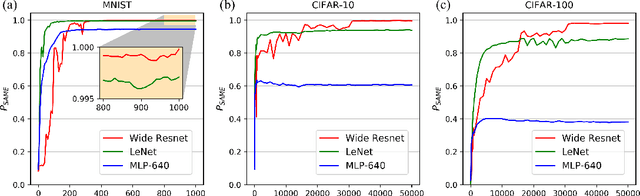
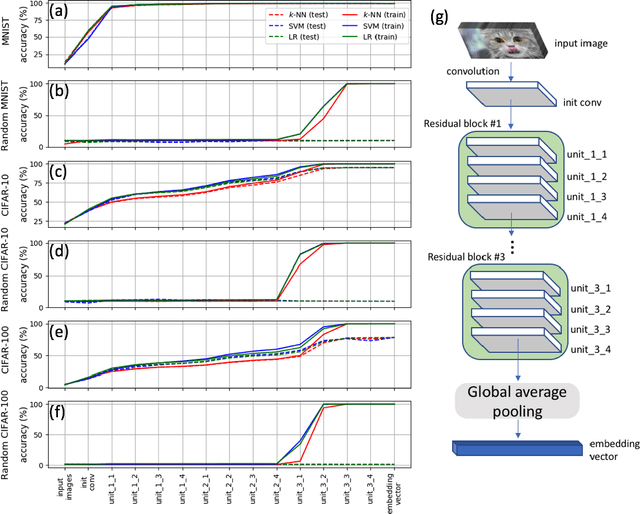
This paper studies the relationship between the classification performed by deep neural networks and the $k$-NN decision at the embedding space of these networks. This simple important connection shown here provides a better understanding of the relationship between the ability of neural networks to generalize and their tendency to memorize the training data, which are traditionally considered to be contradicting to each other and here shown to be compatible and complementary. Our results support the conjecture that deep neural networks approach Bayes optimal error rates.