 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Amortized Clustering via Generative Flow Networks
Feb 26, 2025



Neural models for amortized probabilistic clustering yield samples of cluster labels given a set-structured input, while avoiding lengthy Markov chain runs and the need for explicit data likelihoods. Existing methods which label each data point sequentially, like the Neural Clustering Process, often lead to cluster assignments highly dependent on the data order. Alternatively, methods that sequentially create full clusters, do not provide assignment probabilities. In this paper, we introduce GFNCP, a novel framework for amortized clustering. GFNCP is formulated as a Generative Flow Network with a shared energy-based parametrization of policy and reward. We show that the flow matching conditions are equivalent to consistency of the clustering posterior under marginalization, which in turn implies order invariance. GFNCP also outperforms existing methods in clustering performance on both synthetic and real-world data.
GIF: Generative Interpretable Faces
Aug 31, 2020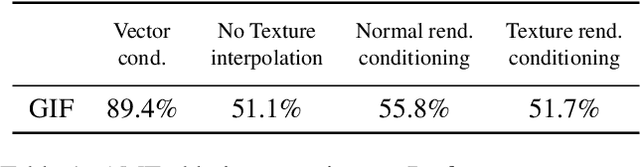
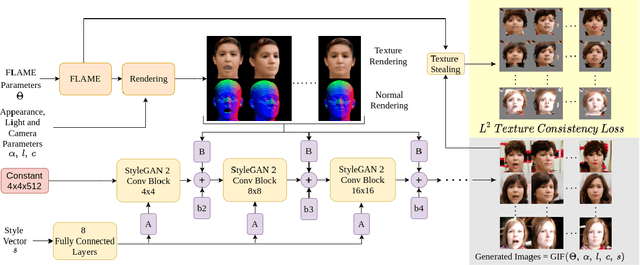
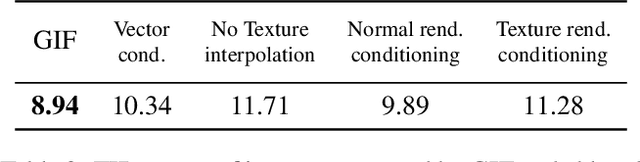

Photo-realistic visualization and animation of expressive human faces have been a long standing challenge. On one end of the spectrum, 3D face modeling methods provide parametric control but tend to generate unrealistic images, while on the other end, generative 2D models like GANs (Generative Adversarial Networks) output photo-realistic face images, but lack explicit control. Recent methods gain partial control, either by attempting to disentangle different factors in an unsupervised manner, or by adding control post hoc to a pre-trained model. Trained GANs without pre-defined control, however, may entangle factors that are hard to undo later. To guarantee some disentanglement that provides us with desired kinds of control, we train our generative model conditioned on pre-defined control parameters. Specifically, we condition StyleGAN2 on FLAME, a generative 3D face model. However, we found out that a naive conditioning on FLAME parameters yields rather unsatisfactory results. Instead we render out geometry and photo-metric details of the FLAME mesh and use these for conditioning instead. This gives us a generative 2D face model named GIF (Generative Interpretable Faces) that shares FLAME's parametric control. Given FLAME parameters for shape, pose, and expressions, parameters for appearance and lighting, and an additional style vector, GIF outputs photo-realistic face images. To evaluate how well GIF follows its conditioning and the impact of different design choices, we perform a perceptual study. The code and trained model are publicly available for research purposes at https://github.com/ParthaEth/GIF.
Synthetic-to-Real Domain Adaptation for Lane Detection
Jul 08, 2020
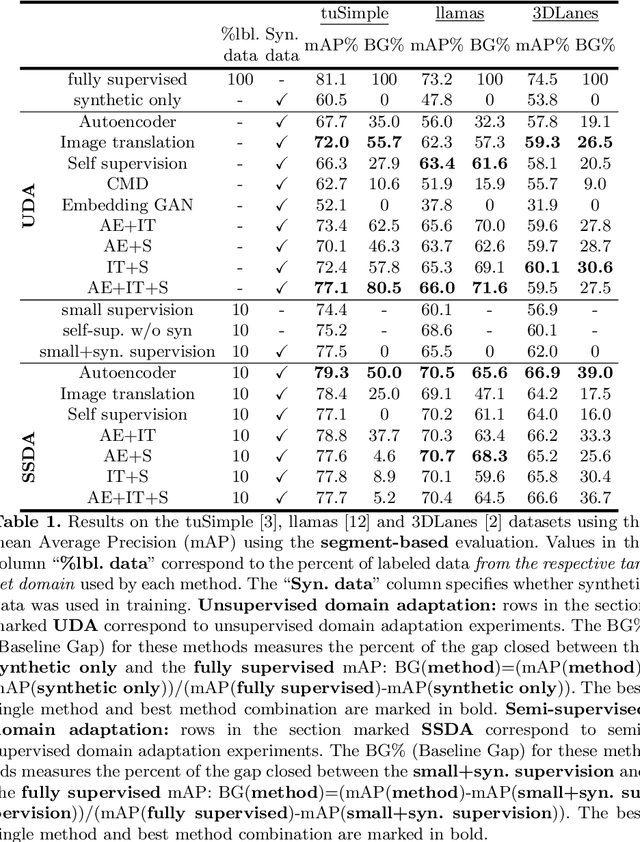
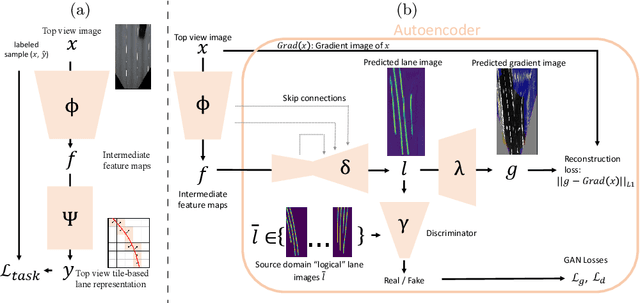
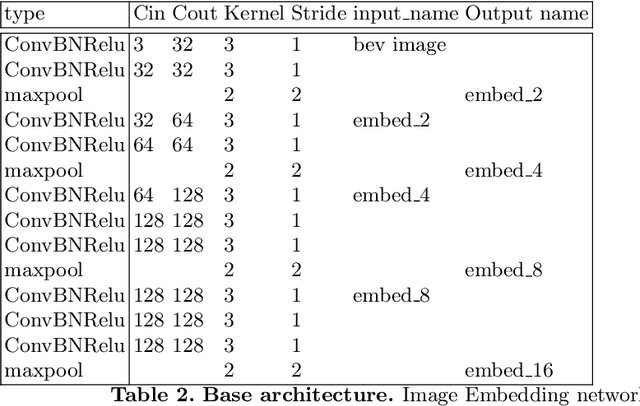
Accurate lane detection, a crucial enabler for autonomous driving, currently relies on obtaining a large and diverse labeled training dataset. In this work, we explore learning from abundant, randomly generated synthetic data, together with unlabeled or partially labeled target domain data, instead. Randomly generated synthetic data has the advantage of controlled variability in the lane geometry and lighting, but it is limited in terms of photo-realism. This poses the challenge of adapting models learned on the unrealistic synthetic domain to real images. To this end we develop a novel autoencoder-based approach that uses synthetic labels unaligned with particular images for adapting to target domain data. In addition, we explore existing domain adaptation approaches, such as image translation and self-supervision, and adjust them to the lane detection task. We test all approaches in the unsupervised domain adaptation setting in which no target domain labels are available and in the semi-supervised setting in which a small portion of the target images are labeled. In extensive experiments using three different datasets, we demonstrate the possibility to save costly target domain labeling efforts. For example, using our proposed autoencoder approach on the llamas and tuSimple lane datasets, we can almost recover the fully supervised accuracy with only 10% of the labeled data. In addition, our autoencoder approach outperforms all other methods in the semi-supervised domain adaptation scenario.