 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor-Parallelism with Partially Synchronized Activations
Jun 24, 2025Training and inference of Large Language Models (LLMs) with tensor-parallelism requires substantial communication to synchronize activations. Our findings suggest that with a few minor adjustments to current practices, LLMs can be trained without fully synchronizing activations, reducing bandwidth demands. We name this "Communication-Aware Architecture for Tensor-parallelism" (CAAT-Net). We train 1B and 7B parameter CAAT-Net models, with a 50% reduction in tensor-parallel communication and no significant drop in pretraining accuracy. Furthermore, we demonstrate how CAAT-Net accelerates both training and inference workloads.
DropCompute: simple and more robust distributed synchronous training via compute variance reduction
Jun 18, 2023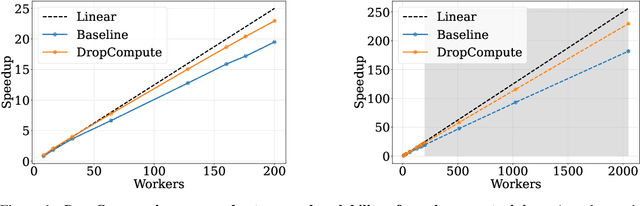

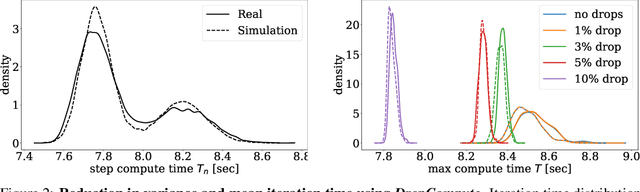
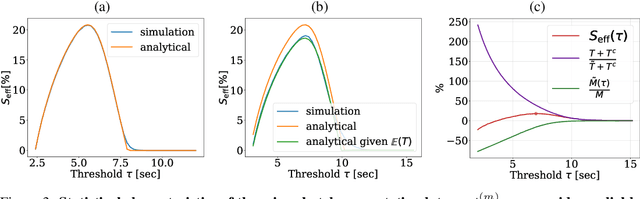
Background: Distributed training is essential for large scale training of deep neural networks (DNNs). The dominant methods for large scale DNN training are synchronous (e.g. All-Reduce), but these require waiting for all workers in each step. Thus, these methods are limited by the delays caused by straggling workers. Results: We study a typical scenario in which workers are straggling due to variability in compute time. We find an analytical relation between compute time properties and scalability limitations, caused by such straggling workers. With these findings, we propose a simple yet effective decentralized method to reduce the variation among workers and thus improve the robustness of synchronous training. This method can be integrated with the widely used All-Reduce. Our findings are validated on large-scale training tasks using 200 Gaudi Accelerators.
Flood forecasting with machine learning models in an operational framework
Nov 04, 2021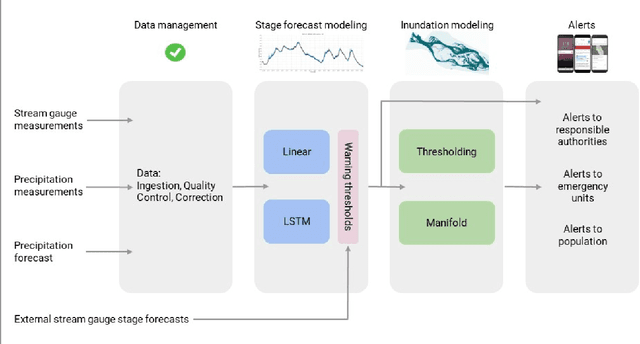
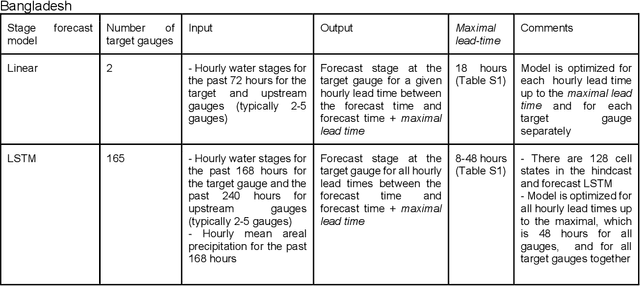
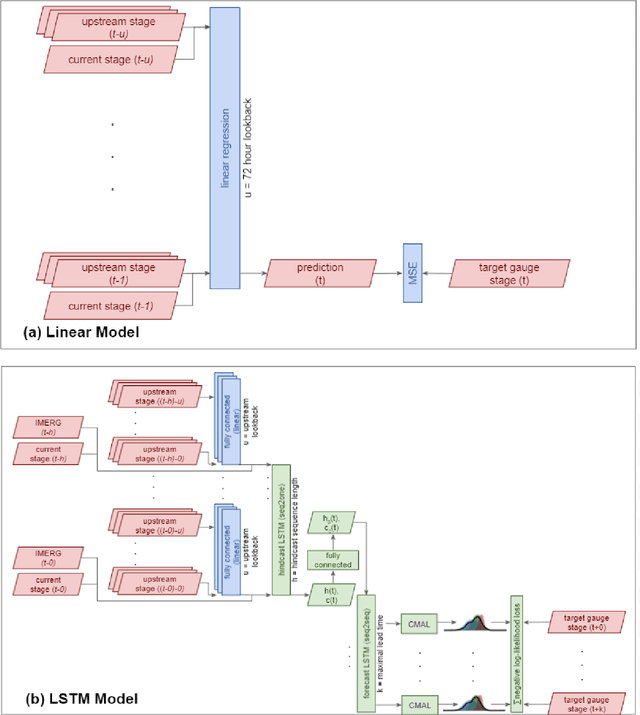
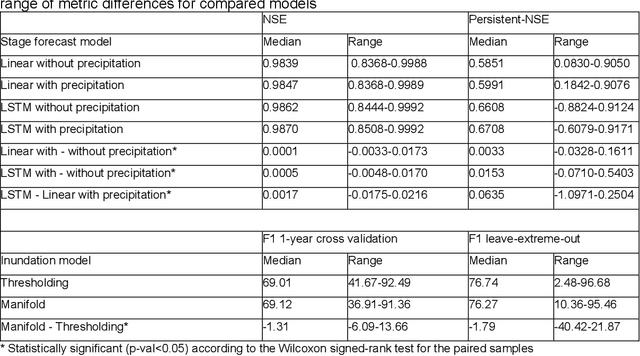
The operational flood forecasting system by Google was developed to provide accurate real-time flood warnings to agencies and the public, with a focus on riverine floods in large, gauged rivers. It became operational in 2018 and has since expanded geographically. This forecasting system consists of four subsystems: data validation, stage forecasting, inundation modeling, and alert distribution. Machine learning is used for two of the subsystems. Stage forecasting is modeled with the Long Short-Term Memory (LSTM) networks and the Linear models. Flood inundation is computed with the Thresholding and the Manifold models, where the former computes inundation extent and the latter computes both inundation extent and depth. The Manifold model, presented here for the first time, provides a machine-learning alternative to hydraulic modeling of flood inundation. When evaluated on historical data, all models achieve sufficiently high-performance metrics for operational use. The LSTM showed higher skills than the Linear model, while the Thresholding and Manifold models achieved similar performance metrics for modeling inundation extent. During the 2021 monsoon season, the flood warning system was operational in India and Bangladesh, covering flood-prone regions around rivers with a total area of 287,000 km2, home to more than 350M people. More than 100M flood alerts were sent to affected populations, to relevant authorities, and to emergency organizations. Current and future work on the system includes extending coverage to additional flood-prone locations, as well as improving modeling capabilities and accuracy.
Physics-Aware Downsampling with Deep Learning for Scalable Flood Modeling
Jun 14, 2021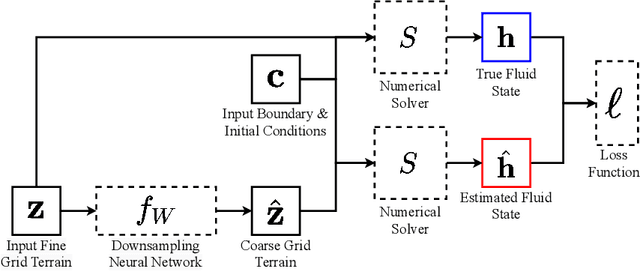
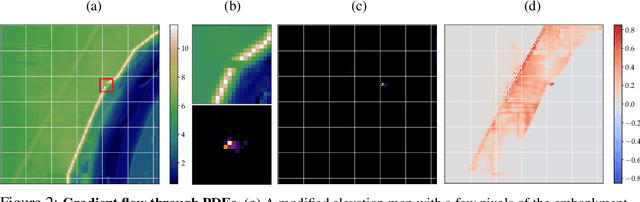
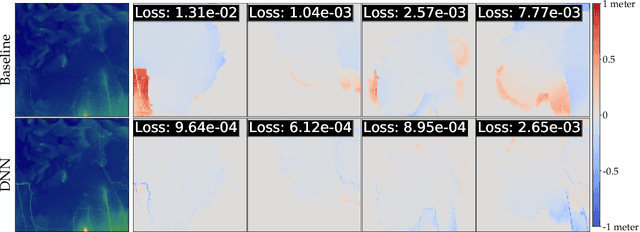

Background: Floods are the most common natural disaster in the world, affecting the lives of hundreds of millions. Flood forecasting is therefore a vitally important endeavor, typically achieved using physical water flow simulations, which rely on accurate terrain elevation maps. However, such simulations, based on solving partial differential equations, are computationally prohibitive on a large scale. This scalability issue is commonly alleviated using a coarse grid representation of the elevation map, though this representation may distort crucial terrain details, leading to significant inaccuracies in the simulation. Contributions: We train a deep neural network to perform physics-informed downsampling of the terrain map: we optimize the coarse grid representation of the terrain maps, so that the flood prediction will match the fine grid solution. For the learning process to succeed, we configure a dataset specifically for this task. We demonstrate that with this method, it is possible to achieve a significant reduction in computational cost, while maintaining an accurate solution. A reference implementation accompanies the paper as well as documentation and code for dataset reproduction.
At Stability's Edge: How to Adjust Hyperparameters to Preserve Minima Selection in Asynchronous Training of Neural Networks?
Sep 26, 2019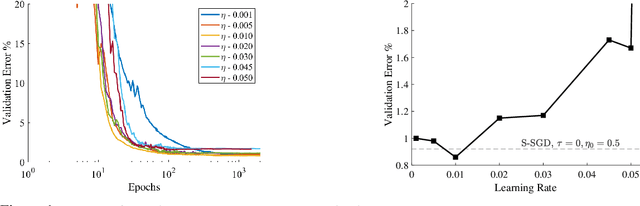

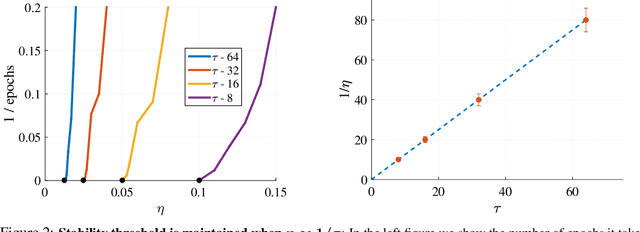
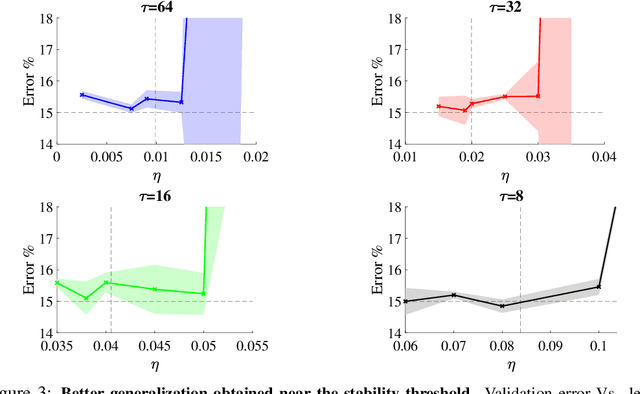
Background: Recent developments have made it possible to accelerate neural networks training significantly using large batch sizes and data parallelism. Training in an asynchronous fashion, where delay occurs, can make training even more scalable. However, asynchronous training has its pitfalls, mainly a degradation in generalization, even after convergence of the algorithm. This gap remains not well understood, as theoretical analysis so far mainly focused on the convergence rate of asynchronous methods. Contributions: We examine asynchronous training from the perspective of dynamical stability. We find that the degree of delay interacts with the learning rate, to change the set of minima accessible by an asynchronous stochastic gradient descent algorithm. We derive closed-form rules on how the learning rate could be changed, while keeping the accessible set the same. Specifically, for high delay values, we find that the learning rate should be kept inversely proportional to the delay. We then extend this analysis to include momentum. We find momentum should be either turned off, or modified to improve training stability. We provide empirical experiments to validate our theoretical findings.
Evaluating and Calibrating Uncertainty Prediction in Regression Tasks
May 30, 2019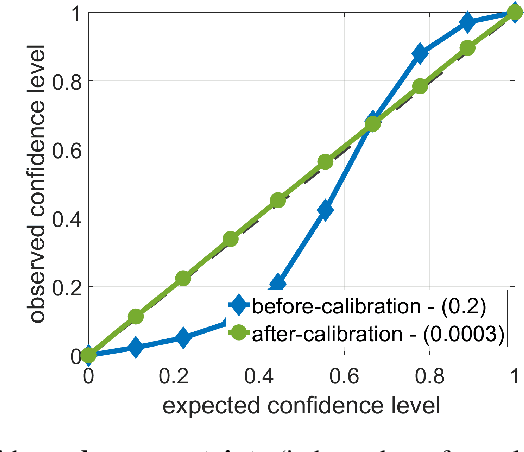
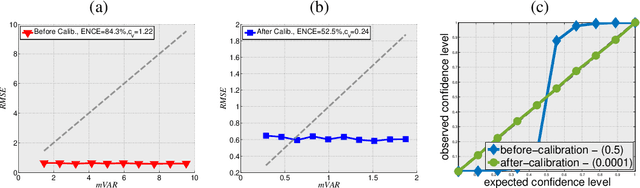
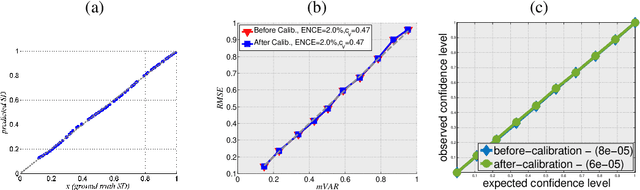

Predicting not only the target but also an accurate measure of uncertainty is important for many applications and in particular safety-critical ones. In this work we study the calibration of uncertainty prediction for regression tasks which often arise in real-world systems. We show that the existing approach for evaluating the calibration of a regression uncertainty [Kuleshov et al. 2018] has severe limitations in distinguishing informative from non-informative uncertainty predictions. We propose a new evaluation method that escapes this caveat using a simple histogram-based approach inspired by reliability diagrams used in classification tasks. Our method clusters examples with similar uncertainty prediction and compares the prediction with the empirical uncertainty on these examples. We also propose a simple scaling-based calibration that preforms well in our experimental tests. We show results on both a synthetic, controlled problem and on the object detection bounding-box regression task using the COCO and KITTI datasets.
Augment your batch: better training with larger batches
Jan 27, 2019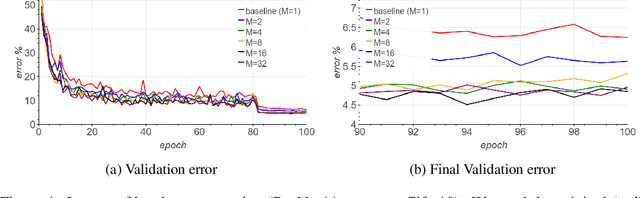
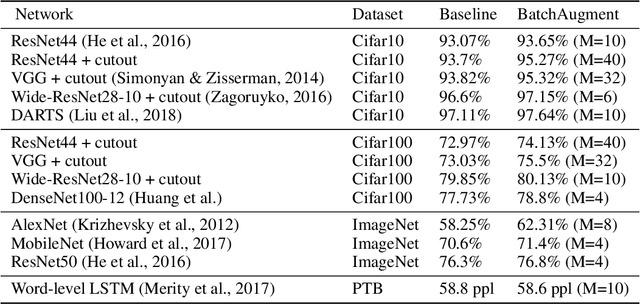
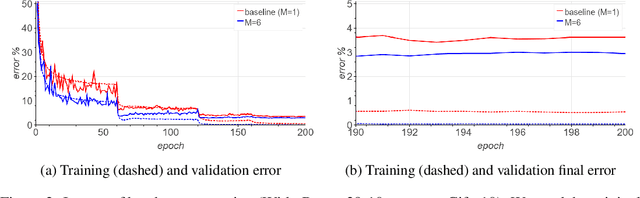

Large-batch SGD is important for scaling training of deep neural networks. However, without fine-tuning hyperparameter schedules, the generalization of the model may be hampered. We propose to use batch augmentation: replicating instances of samples within the same batch with different data augmentations. Batch augmentation acts as a regularizer and an accelerator, increasing both generalization and performance scaling. We analyze the effect of batch augmentation on gradient variance and show that it empirically improves convergence for a wide variety of deep neural networks and datasets. Our results show that batch augmentation reduces the number of necessary SGD updates to achieve the same accuracy as the state-of-the-art. Overall, this simple yet effective method enables faster training and better generalization by allowing more computational resources to be used concurrently.