 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEXAQ: Exponent Aware Quantization For LLMs Acceleration
Oct 04, 2024



Quantization has established itself as the primary approach for decreasing the computational and storage expenses associated with Large Language Models (LLMs) inference. The majority of current research emphasizes quantizing weights and activations to enable low-bit general-matrix-multiply (GEMM) operations, with the remaining non-linear operations executed at higher precision. In our study, we discovered that following the application of these techniques, the primary bottleneck in LLMs inference lies in the softmax layer. The softmax operation comprises three phases: exponent calculation, accumulation, and normalization, Our work focuses on optimizing the first two phases. We propose an analytical approach to determine the optimal clipping value for the input to the softmax function, enabling sub-4-bit quantization for LLMs inference. This method accelerates the calculations of both $e^x$ and $\sum(e^x)$ with minimal to no accuracy degradation. For example, in LLaMA1-30B, we achieve baseline performance with 2-bit quantization on the well-known "Physical Interaction: Question Answering" (PIQA) dataset evaluation. This ultra-low bit quantization allows, for the first time, an acceleration of approximately 4x in the accumulation phase. The combination of accelerating both $e^x$ and $\sum(e^x)$ results in a 36.9% acceleration in the softmax operation.
DropCompute: simple and more robust distributed synchronous training via compute variance reduction
Jun 18, 2023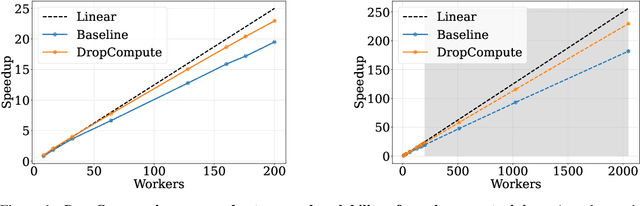

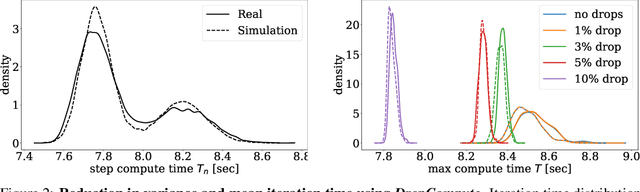
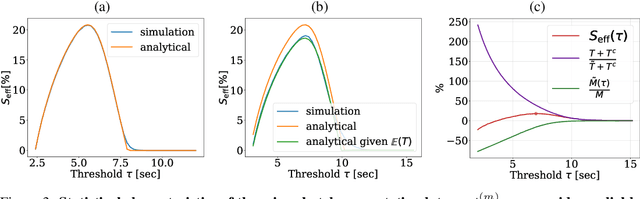
Background: Distributed training is essential for large scale training of deep neural networks (DNNs). The dominant methods for large scale DNN training are synchronous (e.g. All-Reduce), but these require waiting for all workers in each step. Thus, these methods are limited by the delays caused by straggling workers. Results: We study a typical scenario in which workers are straggling due to variability in compute time. We find an analytical relation between compute time properties and scalability limitations, caused by such straggling workers. With these findings, we propose a simple yet effective decentralized method to reduce the variation among workers and thus improve the robustness of synchronous training. This method can be integrated with the widely used All-Reduce. Our findings are validated on large-scale training tasks using 200 Gaudi Accelerators.
Neural gradients are lognormally distributed: understanding sparse and quantized training
Jun 17, 2020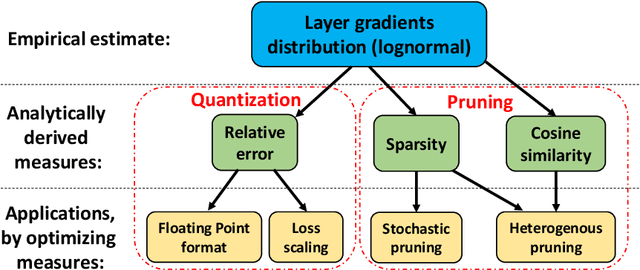

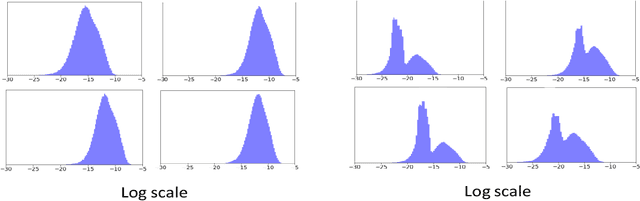
Neural gradient compression remains a main bottleneck in improving training efficiency, as most existing neural network compression methods (e.g., pruning or quantization) focus on weights, activations, and weight gradients. However, these methods are not suitable for compressing neural gradients, which have a very different distribution. Specifically, we find that the neural gradients follow a lognormal distribution. Taking this into account, we suggest two methods to reduce the computational and memory burdens of neural gradients. The first one is stochastic gradient pruning, which can accurately set the sparsity level -- up to 85% gradient sparsity without hurting validation accuracy (ResNet18 on ImageNet). The second method determines the floating-point format for low numerical precision gradients (e.g., FP8). Our results shed light on previous findings related to local scaling, the optimal bit-allocation for the mantissa and exponent, and challenging workloads for which low-precision floating-point arithmetic has reported to fail. Reference implementation accompanies the paper.
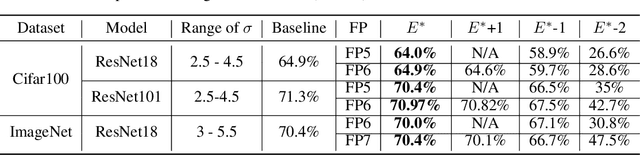
Robust Quantization: One Model to Rule Them All
Feb 18, 2020
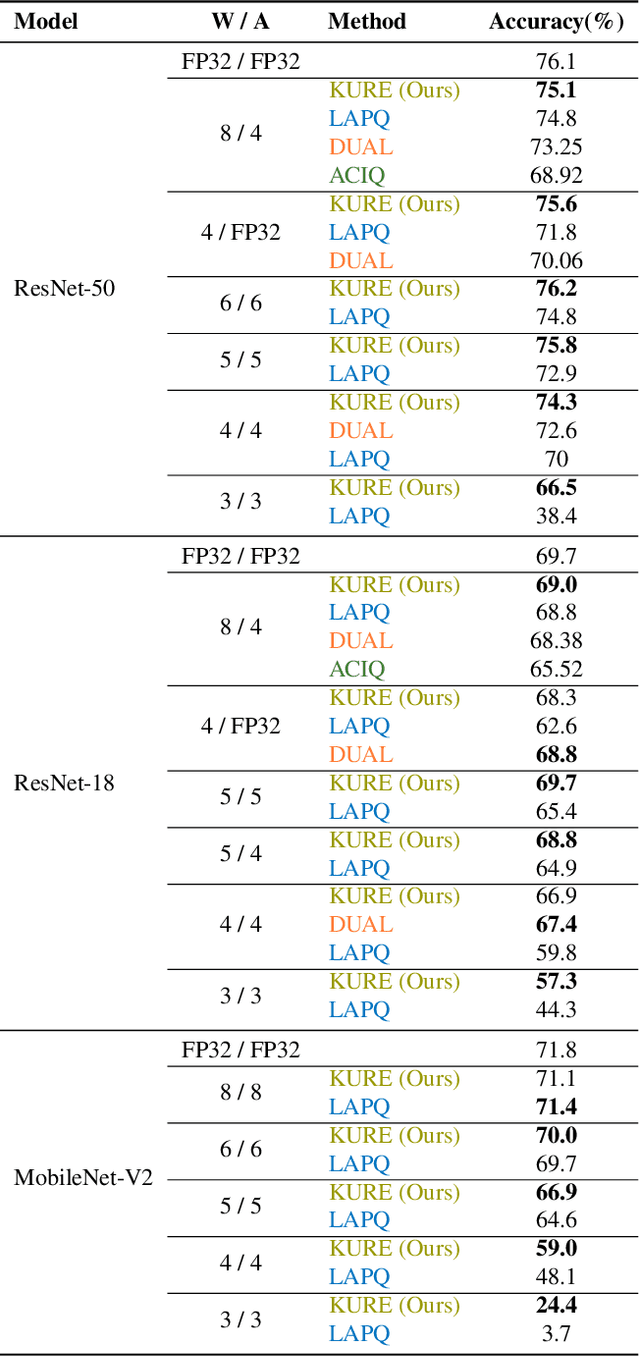
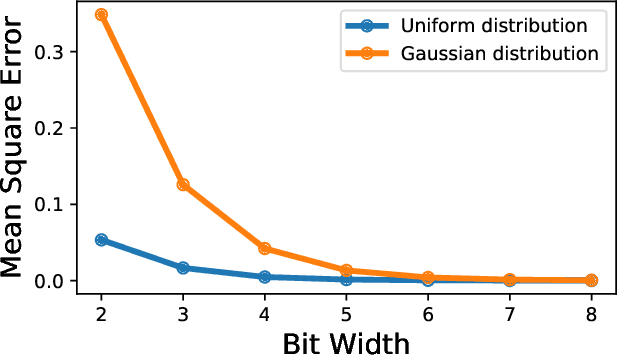

Neural network quantization methods often involve simulating the quantization process during training. This makes the trained model highly dependent on the precise way quantization is performed. Since low-precision accelerators differ in their quantization policies and their supported mix of data-types, a model trained for one accelerator may not be suitable for another. To address this issue, we propose KURE, a method that provides intrinsic robustness to the model against a broad range of quantization implementations. We show that KURE yields a generic model that may be deployed on numerous inference accelerators without a significant loss in accuracy.
Thanks for Nothing: Predicting Zero-Valued Activations with Lightweight Convolutional Neural Networks
Sep 17, 2019
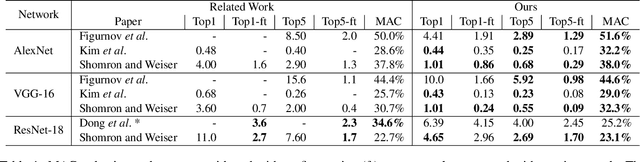
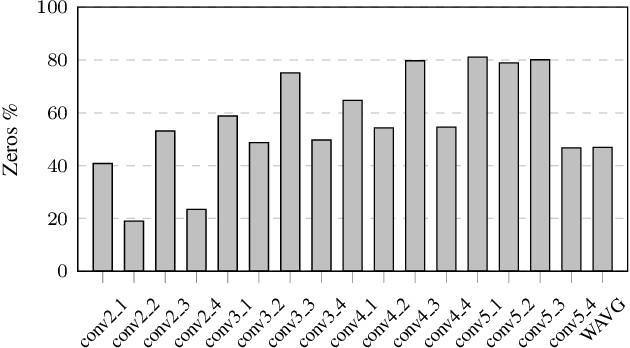
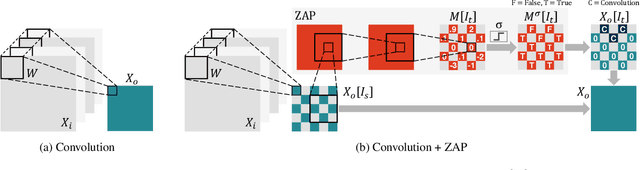
Convolutional neural networks (CNNs) introduce state-of-the-art results for various tasks with the price of high computational demands. Inspired by the observation that spatial correlation exists in CNN output feature maps (ofms), we propose a method to dynamically predict whether ofm activations are zero-valued or not according to their neighboring activation values, thereby avoiding zero-valued activations and reducing the number of convolution operations. We implement the zero activation predictor (ZAP) with a lightweight CNN, which imposes negligible overheads and is easy to deploy and train. Furthermore, the same ZAP can be tuned to many different operating points along the accuracy-savings trade-off curve. For example, using VGG-16 and the ILSVRC-2012 dataset, different operating points achieve a reduction of 23.5% and 32.3% multiply-accumulate (MAC) operations with top-1/top-5 accuracy degradation of 0.3%/0.1% and 1%/0.5% without fine-tuning, respectively. Considering one-epoch fine-tuning, 41.7% MAC operations may be reduced with 1.1%/0.52% accuracy degradation.