 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePost-Training Sparsity-Aware Quantization
May 23, 2021


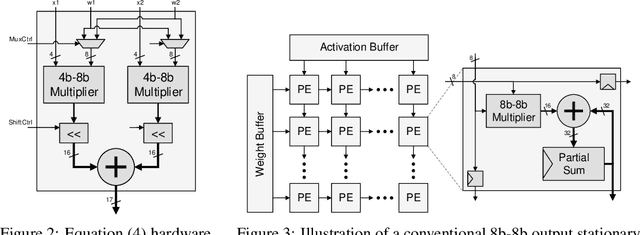
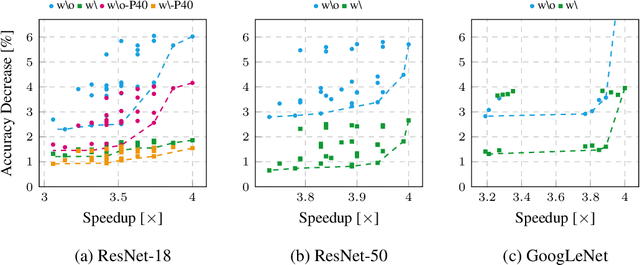
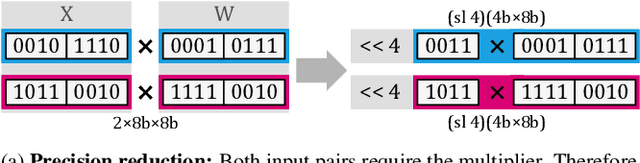
Quantization is a technique used in deep neural networks (DNNs) to increase execution performance and hardware efficiency. Uniform post-training quantization (PTQ) methods are common, since they can be implemented efficiently in hardware and do not require extensive hardware resources or a training set. Mapping FP32 models to INT8 using uniform PTQ yields models with negligible accuracy degradation; however, reducing precision below 8 bits with PTQ is challenging, as accuracy degradation becomes noticeable, due to the increase in quantization noise. In this paper, we propose a sparsity-aware quantization (SPARQ) method, in which the unstructured and dynamic activation sparsity is leveraged in different representation granularities. 4-bit quantization, for example, is employed by dynamically examining the bits of 8-bit values and choosing a window of 4 bits, while first skipping zero-value bits. Moreover, instead of quantizing activation-by-activation to 4 bits, we focus on pairs of 8-bit activations and examine whether one of the two is equal to zero. If one is equal to zero, the second can opportunistically use the other's 4-bit budget; if both do not equal zero, then each is dynamically quantized to 4 bits, as described. SPARQ achieves minor accuracy degradation, 2x speedup over widely used hardware architectures, and a practical hardware implementation. The code is available at https://github.com/gilshm/sparq.
Post-Training BatchNorm Recalibration
Oct 12, 2020
We revisit non-blocking simultaneous multithreading (NB-SMT) introduced previously by Shomron and Weiser (2020). NB-SMT trades accuracy for performance by occasionally "squeezing" more than one thread into a shared multiply-and-accumulate (MAC) unit. However, the method of accommodating more than one thread in a shared MAC unit may contribute noise to the computations, thereby changing the internal statistics of the model. We show that substantial model performance can be recouped by post-training recalibration of the batch normalization layers' running mean and running variance statistics, given the presence of NB-SMT.
Non-Blocking Simultaneous Multithreading: Embracing the Resiliency of Deep Neural Networks
Apr 17, 2020

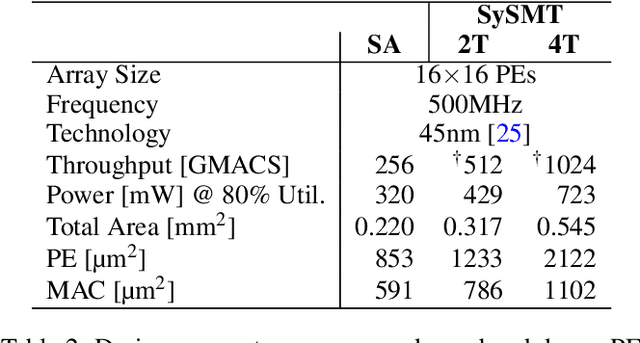
Deep neural networks (DNNs) are known for their inability to utilize underlying hardware resources due to hardware susceptibility to sparse activations and weights. Even in finer granularities, many of the non-zero values hold a portion of zero-valued bits that may cause inefficiencies when executed on hardware. Inspired by conventional CPU simultaneous multithreading (SMT) that increases computer resource utilization by sharing them across several threads, we propose non-blocking SMT (NB-SMT) designated for DNN accelerators. Like conventional SMT, NB-SMT shares hardware resources among several execution flows. Yet, unlike SMT, NB-SMT is non-blocking, as it handles structural hazards by exploiting the algorithmic resiliency of DNNs. Instead of opportunistically dispatching instructions while they wait in a reservation station for available hardware, NB-SMT temporarily reduces the computation precision to accommodate all threads at once, enabling a non-blocking operation. We demonstrate NB-SMT applicability using SySMT, an NB-SMT-enabled output-stationary systolic array (OS-SA). Compared with a conventional OS-SA, a 2-threaded SySMT consumes 1.4x the area and delivers 2x speedup with 33% energy savings and less than 1% accuracy degradation of state-of-the-art CNNs with ImageNet. A 4-threaded SySMT consumes 2.5x the area and delivers, for example, 3.4x speedup and 39% energy savings with 1% accuracy degradation of 40%-pruned ResNet-18.
Robust Quantization: One Model to Rule Them All
Feb 18, 2020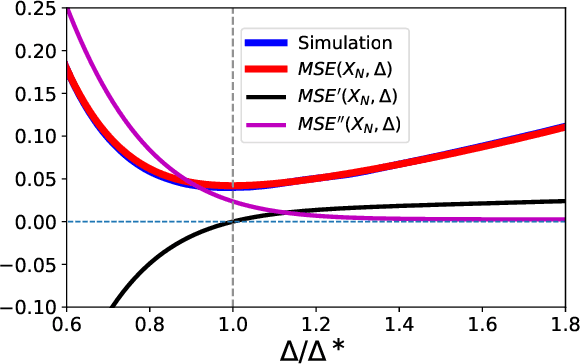
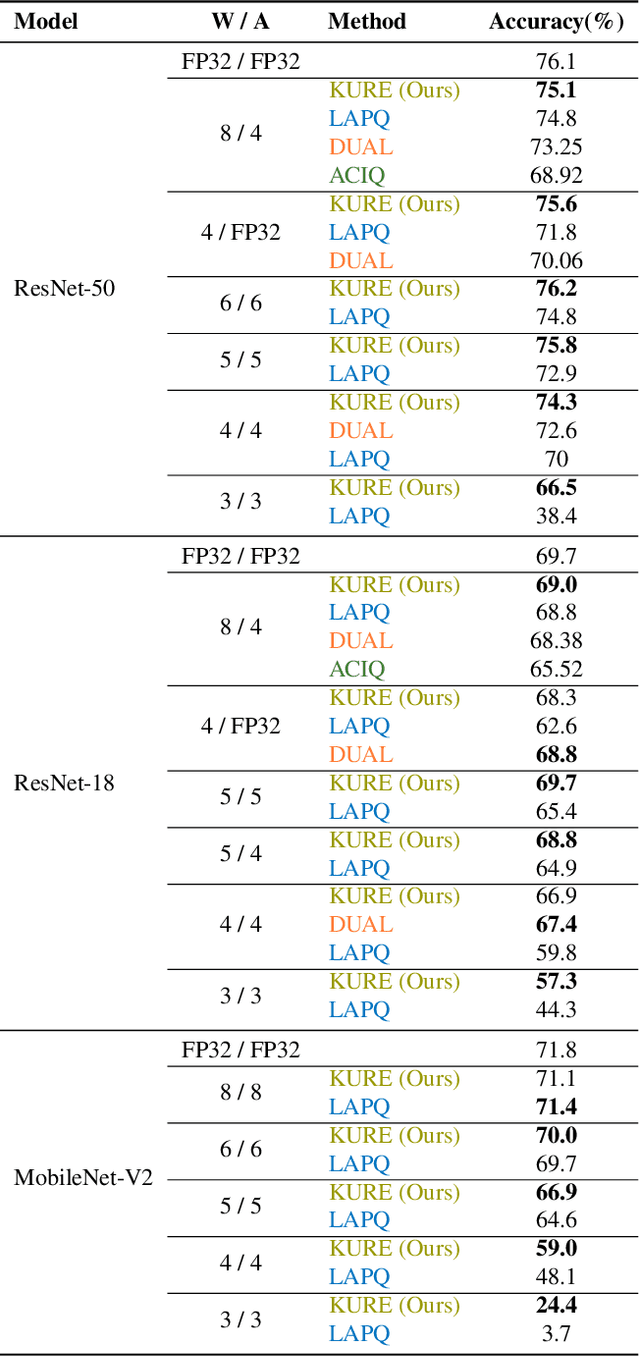
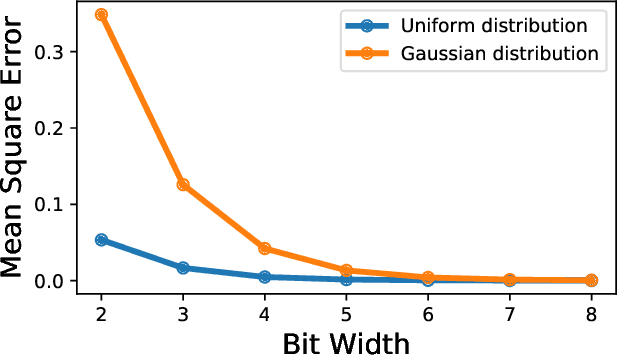

Neural network quantization methods often involve simulating the quantization process during training. This makes the trained model highly dependent on the precise way quantization is performed. Since low-precision accelerators differ in their quantization policies and their supported mix of data-types, a model trained for one accelerator may not be suitable for another. To address this issue, we propose KURE, a method that provides intrinsic robustness to the model against a broad range of quantization implementations. We show that KURE yields a generic model that may be deployed on numerous inference accelerators without a significant loss in accuracy.
Thanks for Nothing: Predicting Zero-Valued Activations with Lightweight Convolutional Neural Networks
Sep 17, 2019
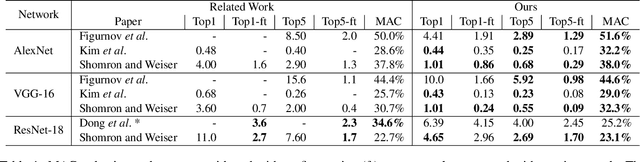
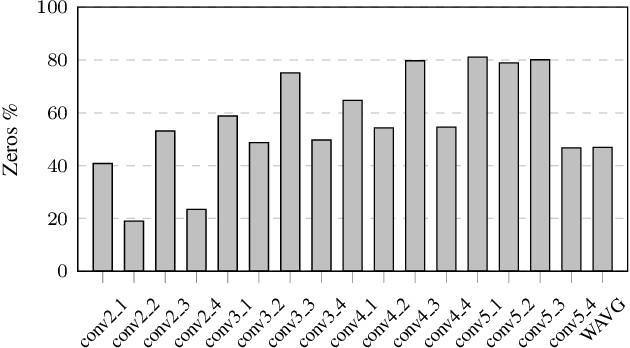
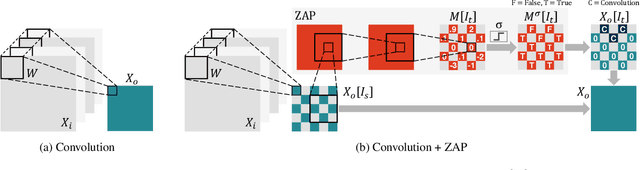
Convolutional neural networks (CNNs) introduce state-of-the-art results for various tasks with the price of high computational demands. Inspired by the observation that spatial correlation exists in CNN output feature maps (ofms), we propose a method to dynamically predict whether ofm activations are zero-valued or not according to their neighboring activation values, thereby avoiding zero-valued activations and reducing the number of convolution operations. We implement the zero activation predictor (ZAP) with a lightweight CNN, which imposes negligible overheads and is easy to deploy and train. Furthermore, the same ZAP can be tuned to many different operating points along the accuracy-savings trade-off curve. For example, using VGG-16 and the ILSVRC-2012 dataset, different operating points achieve a reduction of 23.5% and 32.3% multiply-accumulate (MAC) operations with top-1/top-5 accuracy degradation of 0.3%/0.1% and 1%/0.5% without fine-tuning, respectively. Considering one-epoch fine-tuning, 41.7% MAC operations may be reduced with 1.1%/0.52% accuracy degradation.
Exploiting Spatial Correlation in Convolutional Neural Networks for Activation Value Prediction
Jul 21, 2018

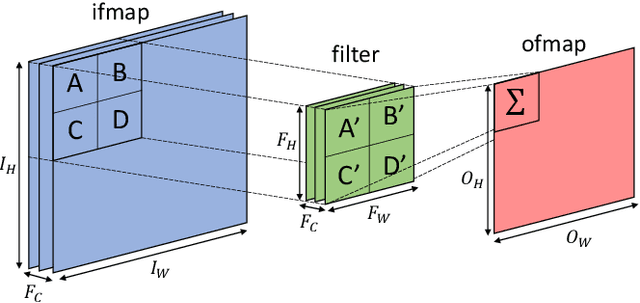
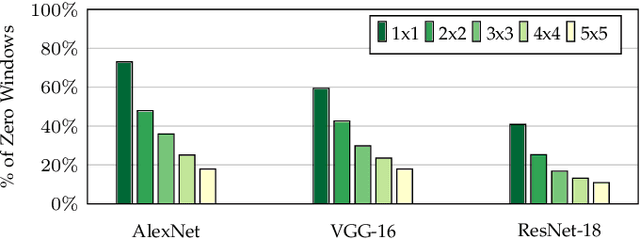
Convolutional neural networks (CNNs) compute their output using weighted-sums of adjacent input elements. This method enables CNNs to achieve state-of-the-art results in a wide range of applications such as computer vision and speech recognition. However, it also comes with the cost of high computational intensity. In this paper we propose to exploit the spatial correlation inherent in CNNs, and use it for value prediction. We show that spatial correlation may be exploited to predict activation values, thus reducing the needed computations in the network. We demonstrate this method with a heuristic that predicts which activations are zero-valued according to nearby activation values, in a scheme we call cross-neuron prediction. Our prediction heuristic reduces the number of multiply-accumulate operations by an average of 40.8%, 36.2%, and 20.8%, with degradation in top-5 accuracy of 2.9%, 5.1%, and 7.6%, for AlexNet, VGG-16, and ResNet-18, respectively.