 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Embedding Distortion for Robust Out-of-Distribution Performance
Sep 11, 2024Foundational models, trained on vast and diverse datasets, have demonstrated remarkable capabilities in generalizing across different domains and distributions for various zero-shot tasks. Our work addresses the challenge of retaining these powerful generalization capabilities when adapting foundational models to specific downstream tasks through fine-tuning. To this end, we introduce a novel approach we call "similarity loss", which can be incorporated into the fine-tuning process of any task. By minimizing the distortion of fine-tuned embeddings from the pre-trained embeddings, our method strikes a balance between task-specific adaptation and preserving broad generalization abilities. We evaluate our approach on two diverse tasks: image classification on satellite imagery and face recognition, focusing on open-class and domain shift scenarios to assess out-of-distribution (OOD) performance. We demonstrate that this approach significantly improves OOD performance while maintaining strong in-distribution (ID) performance.
Enhancing Generic Segmentation with Learned Region Representations
Nov 17, 2019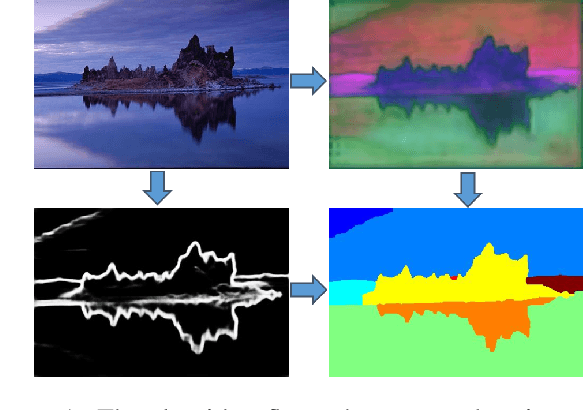
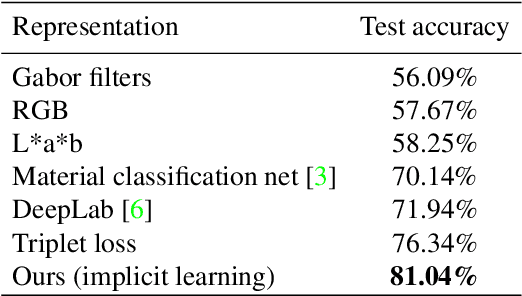

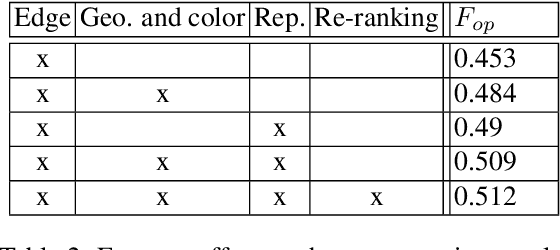
Current successful approaches for generic (non-semantic) segmentation rely mostly on edge detection and have leveraged the strengths of deep learning mainly by improving the edge detection stage in the algorithmic pipeline. This is in contrast to semantic and instance segmentation, where deep learning has made a dramatic affect and DNNs are applied directly to generate pixel-wise segment representations. We propose a new method for learning a pixelwise representation that reflects segment relatedness. This representation is combined with an edge map to yield a new segmentation algorithm. We show that the representations themselves achieve state-of-the-art segment similarity scores. Moreover, the proposed, combined segmentation algorithm provides results that are either the state of the art or improve it, for most quality measures.
Learning Pixel Representations for Generic Segmentation
Sep 25, 2019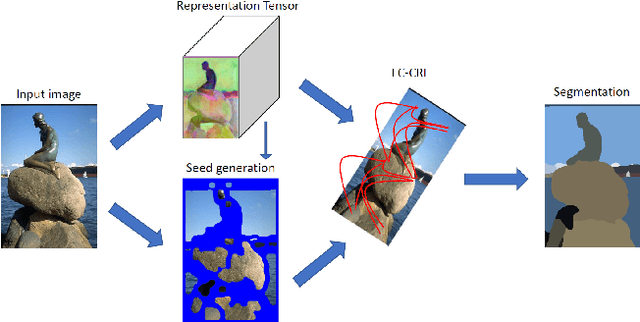


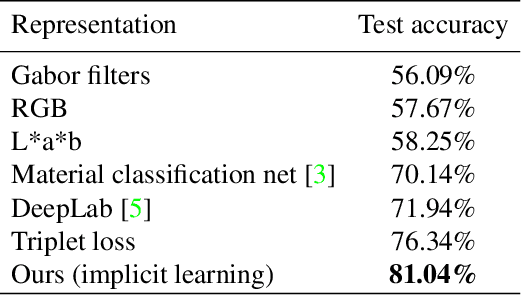
Deep learning approaches to generic (non-semantic) segmentation have so far been indirect and relied on edge detection. This is in contrast to semantic segmentation, where DNNs are applied directly. We propose an alternative approach called Deep Generic Segmentation (DGS) and try to follow the path used for semantic segmentation. Our main contribution is a new method for learning a pixel-wise representation that reflects segment relatedness. This representation is combined with a CRF to yield the segmentation algorithm. We show that we are able to learn meaningful representations that improve segmentation quality and that the representations themselves achieve state-of-the-art segment similarity scores. The segmentation results are competitive and promising.
Learning Discrete Weights Using the Local Reparameterization Trick
Feb 02, 2018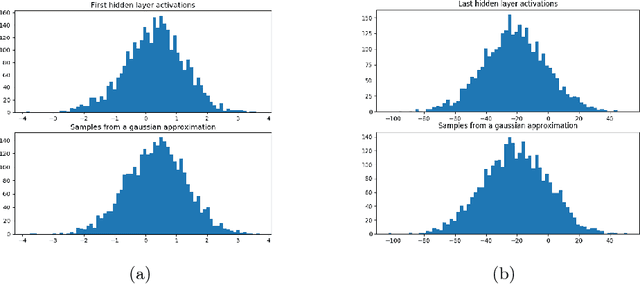
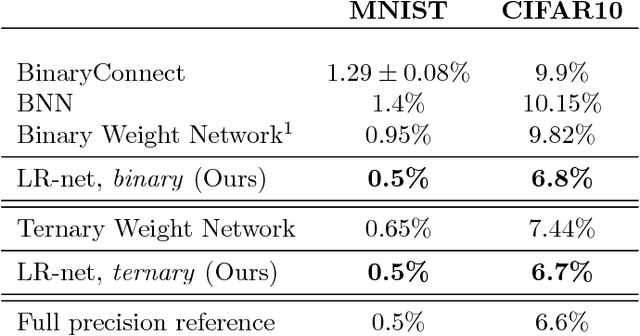
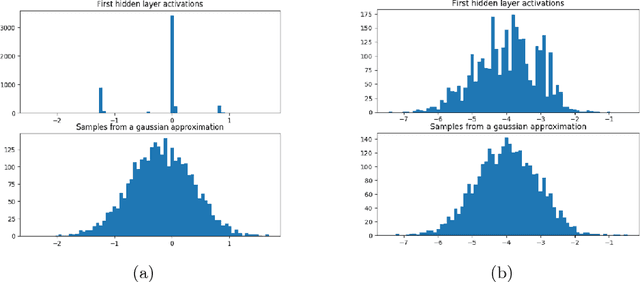
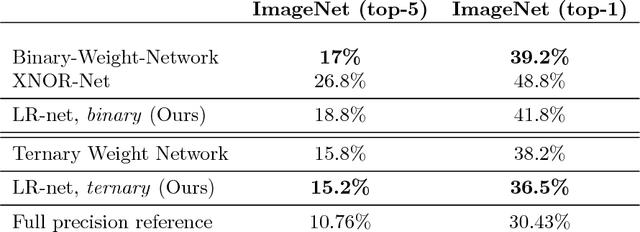
Recent breakthroughs in computer vision make use of large deep neural networks, utilizing the substantial speedup offered by GPUs. For applications running on limited hardware, however, high precision real-time processing can still be a challenge. One approach to solving this problem is training networks with binary or ternary weights, thus removing the need to calculate multiplications and significantly reducing memory size. In this work, we introduce LR-nets (Local reparameterization networks), a new method for training neural networks with discrete weights using stochastic parameters. We show how a simple modification to the local reparameterization trick, previously used to train Gaussian distributed weights, enables the training of discrete weights. Using the proposed training we test both binary and ternary models on MNIST, CIFAR-10 and ImageNet benchmarks and reach state-of-the-art results on most experiments.