 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Media Similarity Evaluation for Web Image Retrieval in the Wild
Paper and Code

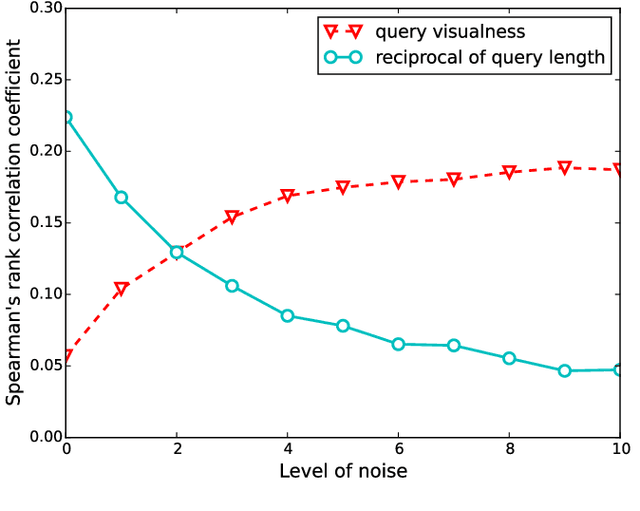
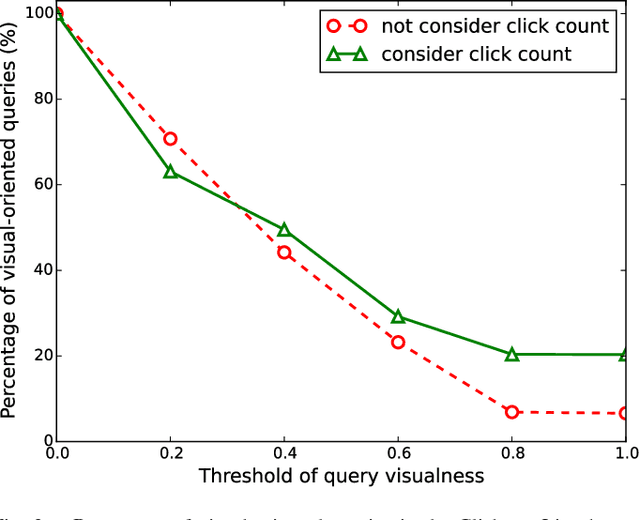
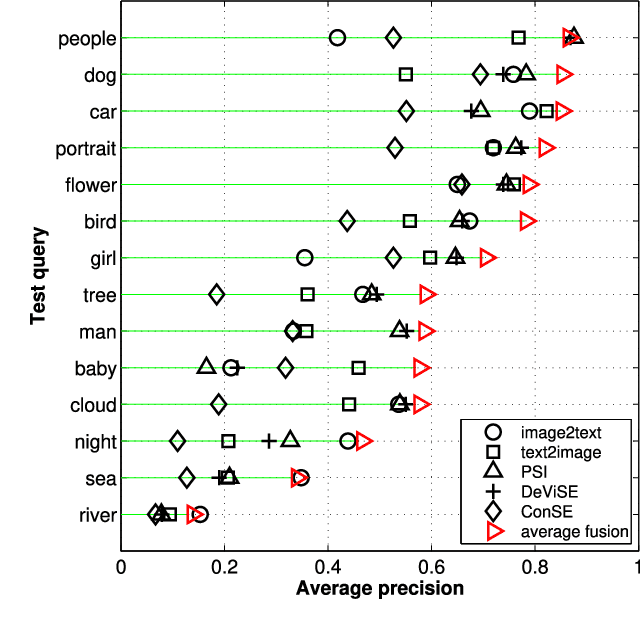
In order to retrieve unlabeled images by textual queries, cross-media similarity computation is a key ingredient. Although novel methods are continuously introduced, little has been done to evaluate these methods together with large-scale query log analysis. Consequently, how far have these methods brought us in answering real-user queries is unclear. Given baseline methods that compute cross-media similarity using relatively simple text/image matching, how much progress have advanced models made is also unclear. This paper takes a pragmatic approach to answering the two questions. Queries are automatically categorized according to the proposed query visualness measure, and later connected to the evaluation of multiple cross-media similarity models on three test sets. Such a connection reveals that the success of the state-of-the-art is mainly attributed to their good performance on visual-oriented queries, while these queries account for only a small part of real-user queries. To quantify the current progress, we propose a simple text2image method, representing a novel test query by a set of images selected from large-scale query log. Consequently, computing cross-media similarity between the test query and a given image boils down to comparing the visual similarity between the given image and the selected images. Image retrieval experiments on the challenging Clickture dataset show that the proposed text2image compares favorably to recent deep learning based alternatives.