 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryTR: Narrative-Centric Video Temporal Retrieval with Theory of Mind Reasoning
Apr 25, 2026Current video moment retrieval excels at action-centric tasks but struggles with narrative content. Models can see \textit{what is happening} but fail to reason \textit{why it matters}. This semantic gap stems from the lack of \textbf{Theory of Mind (ToM)}: the cognitive ability to infer implicit intentions, mental states, and narrative causality from surface-level observations. We introduce \textbf{StoryTR}, the first video moment retrieval benchmark requiring ToM reasoning, comprising 8.1k samples from narrative short-form videos (shorts/reels). These videos present an ideal testbed. Their high information density encodes meaning through subtle multimodal cues. For instance, a glance paired with a sigh carries entirely different semantics than the glance alone. Yet multimodal perception alone is insufficient; ToM is required to decode that a character ``smiling'' may actually be ``concealing hostility.'' To teach models this reasoning capability, we propose an \textbf{Agentic Data Pipeline} that generates training data with explicit three-tier ToM chains (intent decoding, narrative reasoning, boundary localization). Experiments reveal the severity of the reasoning gap: Gemini-3.0-Pro achieves only 0.53 Avg IoU on StoryTR. However, our 7B \textbf{Shorts-Moment} model, trained on ToM-guided data, improves +15.1\% relative IoU over baselines, demonstrating that \textit{narrative reasoning capability matters more than parameter scale}.
SkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
SkyReels-V3 Technique Report
Jan 24, 2026Video generation serves as a cornerstone for building world models, where multimodal contextual inference stands as the defining test of capability. In this end, we present SkyReels-V3, a conditional video generation model, built upon a unified multimodal in-context learning framework with diffusion Transformers. SkyReels-V3 model supports three core generative paradigms within a single architecture: reference images-to-video synthesis, video-to-video extension and audio-guided video generation. (i) reference images-to-video model is designed to produce high-fidelity videos with strong subject identity preservation, temporal coherence, and narrative consistency. To enhance reference adherence and compositional stability, we design a comprehensive data processing pipeline that leverages cross frame pairing, image editing, and semantic rewriting, effectively mitigating copy paste artifacts. During training, an image video hybrid strategy combined with multi-resolution joint optimization is employed to improve generalization and robustness across diverse scenarios. (ii) video extension model integrates spatio-temporal consistency modeling with large-scale video understanding, enabling both seamless single-shot continuation and intelligent multi-shot switching with professional cinematographic patterns. (iii) Talking avatar model supports minute-level audio-conditioned video generation by training first-and-last frame insertion patterns and reconstructing key-frame inference paradigms. On the basis of ensuring visual quality, synchronization of audio and videos has been optimized. Extensive evaluations demonstrate that SkyReels-V3 achieves state-of-the-art or near state-of-the-art performance on key metrics including visual quality, instruction following, and specific aspect metrics, approaching leading closed-source systems. Github: https://github.com/SkyworkAI/SkyReels-V3.
Disentangling Task Conflicts in Multi-Task LoRA via Orthogonal Gradient Projection
Jan 14, 2026Multi-Task Learning (MTL) combined with Low-Rank Adaptation (LoRA) has emerged as a promising direction for parameter-efficient deployment of Large Language Models (LLMs). By sharing a single adapter across multiple tasks, one can significantly reduce storage overhead. However, this approach suffers from negative transfer, where conflicting gradient updates from distinct tasks degrade the performance of individual tasks compared to single-task fine-tuning. This problem is exacerbated in LoRA due to the low-rank constraint, which limits the optimization landscape's capacity to accommodate diverse task requirements. In this paper, we propose Ortho-LoRA, a gradient projection method specifically tailored for the bipartite structure of LoRA. Ortho-LoRA dynamically projects conflicting task gradients onto the orthogonal complement of each other within the intrinsic LoRA subspace. Extensive experiments on the GLUE benchmark demonstrate that Ortho-LoRA effectively mitigates task interference, outperforming standard joint training and recovering 95\% of the performance gap between multi-task and single-task baselines with negligible computational overhead.
SkyReels-Text: Fine-grained Font-Controllable Text Editing for Poster Design
Nov 17, 2025Artistic design such as poster design often demands rapid yet precise modification of textual content while preserving visual harmony and typographic intent, especially across diverse font styles. Although modern image editing models have grown increasingly powerful, they still fall short in fine-grained, font-aware text manipulation, limiting their utility in professional design workflows such as poster editing. To address this issue, we present SkyReels-Text, a novel font-controllable framework for precise poster text editing. Our method enables simultaneous editing of multiple text regions, each rendered in distinct typographic styles, while preserving the visual appearance of non-edited regions. Notably, our model requires neither font labels nor fine-tuning during inference: users can simply provide cropped glyph patches corresponding to their desired typography, even if the font is not included in any standard library. Extensive experiments on multiple datasets, including handwrittent text benchmarks, SkyReels-Text achieves state-of-the-art performance in both text fidelity and visual realism, offering unprecedented control over font families, and stylistic nuances. This work bridges the gap between general-purpose image editing and professional-grade typographic design.
SkyReels-V2: Infinite-length Film Generative Model
Apr 21, 2025Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs' inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
SkyReels-A2: Compose Anything in Video Diffusion Transformers
Apr 03, 2025



This paper presents SkyReels-A2, a controllable video generation framework capable of assembling arbitrary visual elements (e.g., characters, objects, backgrounds) into synthesized videos based on textual prompts while maintaining strict consistency with reference images for each element. We term this task elements-to-video (E2V), whose primary challenges lie in preserving the fidelity of each reference element, ensuring coherent composition of the scene, and achieving natural outputs. To address these, we first design a comprehensive data pipeline to construct prompt-reference-video triplets for model training. Next, we propose a novel image-text joint embedding model to inject multi-element representations into the generative process, balancing element-specific consistency with global coherence and text alignment. We also optimize the inference pipeline for both speed and output stability. Moreover, we introduce a carefully curated benchmark for systematic evaluation, i.e, A2 Bench. Experiments demonstrate that our framework can generate diverse, high-quality videos with precise element control. SkyReels-A2 is the first open-source commercial grade model for the generation of E2V, performing favorably against advanced closed-source commercial models. We anticipate SkyReels-A2 will advance creative applications such as drama and virtual e-commerce, pushing the boundaries of controllable video generation.
Augmented Lagrangian-Based Safe Reinforcement Learning Approach for Distribution System Volt/VAR Control
Oct 19, 2024



This paper proposes a data-driven solution for Volt-VAR control problem in active distribution system. As distribution system models are always inaccurate and incomplete, it is quite difficult to solve the problem. To handle with this dilemma, this paper formulates the Volt-VAR control problem as a constrained Markov decision process (CMDP). By synergistically combining the augmented Lagrangian method and soft actor critic algorithm, a novel safe off-policy reinforcement learning (RL) approach is proposed in this paper to solve the CMDP. The actor network is updated in a policy gradient manner with the Lagrangian value function. A double-critics network is adopted to synchronously estimate the action-value function to avoid overestimation bias. The proposed algorithm does not require strong convexity guarantee of examined problems and is sample efficient. A two-stage strategy is adopted for offline training and online execution, so the accurate distribution system model is no longer needed. To achieve scalability, a centralized training distributed execution strategy is adopted for a multi-agent framework, which enables a decentralized Volt-VAR control for large-scale distribution system. Comprehensive numerical experiments with real-world electricity data demonstrate that our proposed algorithm can achieve high solution optimality and constraints compliance.
SkyScript-100M: 1,000,000,000 Pairs of Scripts and Shooting Scripts for Short Drama
Aug 18, 2024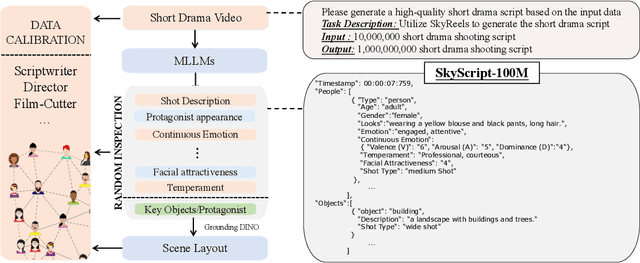
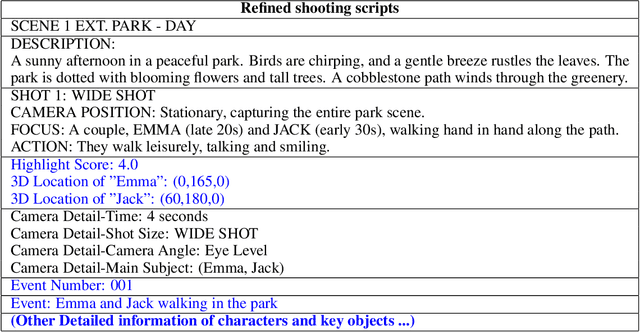
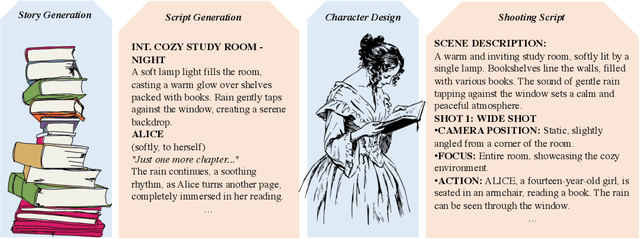
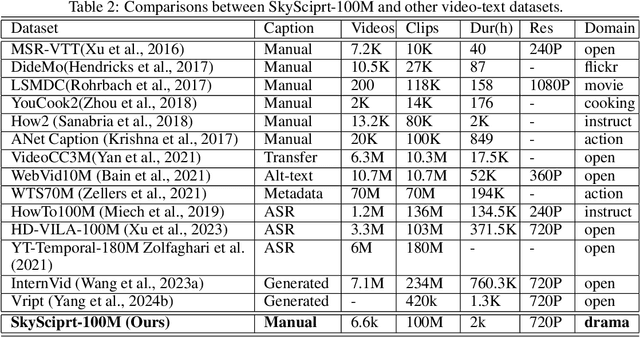
Generating high-quality shooting scripts containing information such as scene and shot language is essential for short drama script generation. We collect 6,660 popular short drama episodes from the Internet, each with an average of 100 short episodes, and the total number of short episodes is about 80,000, with a total duration of about 2,000 hours and totaling 10 terabytes (TB). We perform keyframe extraction and annotation on each episode to obtain about 10,000,000 shooting scripts. We perform 100 script restorations on the extracted shooting scripts based on our self-developed large short drama generation model SkyReels. This leads to a dataset containing 1,000,000,000 pairs of scripts and shooting scripts for short dramas, called SkyScript-100M. We compare SkyScript-100M with the existing dataset in detail and demonstrate some deeper insights that can be achieved based on SkyScript-100M. Based on SkyScript-100M, researchers can achieve several deeper and more far-reaching script optimization goals, which may drive a paradigm shift in the entire field of text-to-video and significantly advance the field of short drama video generation. The data and code are available at https://github.com/vaew/SkyScript-100M.
Towards Playing Full MOBA Games with Deep Reinforcement Learning
Dec 31, 2020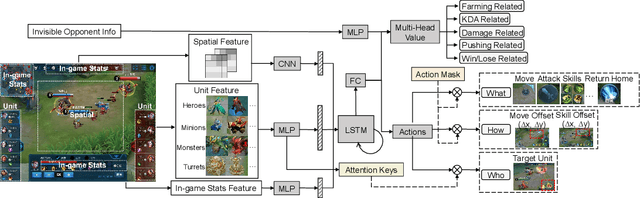
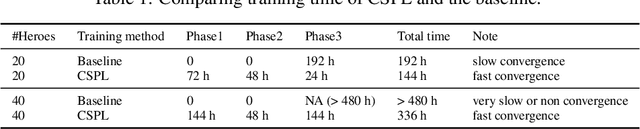
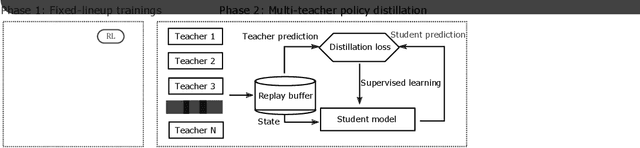

MOBA games, e.g., Honor of Kings, League of Legends, and Dota 2, pose grand challenges to AI systems such as multi-agent, enormous state-action space, complex action control, etc. Developing AI for playing MOBA games has raised much attention accordingly. However, existing work falls short in handling the raw game complexity caused by the explosion of agent combinations, i.e., lineups, when expanding the hero pool in case that OpenAI's Dota AI limits the play to a pool of only 17 heroes. As a result, full MOBA games without restrictions are far from being mastered by any existing AI system. In this paper, we propose a MOBA AI learning paradigm that methodologically enables playing full MOBA games with deep reinforcement learning. Specifically, we develop a combination of novel and existing learning techniques, including curriculum self-play learning, policy distillation, off-policy adaption, multi-head value estimation, and Monte-Carlo tree-search, in training and playing a large pool of heroes, meanwhile addressing the scalability issue skillfully. Tested on Honor of Kings, a popular MOBA game, we show how to build superhuman AI agents that can defeat top esports players. The superiority of our AI is demonstrated by the first large-scale performance test of MOBA AI agent in the literature.