 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V4: Multi-modal Video-Audio Generation, Inpainting and Editing model
Feb 26, 2026SkyReels V4 is a unified multi modal video foundation model for joint video audio generation, inpainting, and editing. The model adopts a dual stream Multimodal Diffusion Transformer (MMDiT) architecture, where one branch synthesizes video and the other generates temporally aligned audio, while sharing a powerful text encoder based on the Multimodal Large Language Models (MMLM). SkyReels V4 accepts rich multi modal instructions, including text, images, video clips, masks, and audio references. By combining the MMLMs multi modal instruction following capability with in context learning in the video branch MMDiT, the model can inject fine grained visual guidance under complex conditioning, while the audio branch MMDiT simultaneously leverages audio references to guide sound generation. On the video side, we adopt a channel concatenation formulation that unifies a wide range of inpainting style tasks, such as image to video, video extension, and video editing under a single interface, and naturally extends to vision referenced inpainting and editing via multi modal prompts. SkyReels V4 supports up to 1080p resolution, 32 FPS, and 15 second duration, enabling high fidelity, multi shot, cinema level video generation with synchronized audio. To make such high resolution, long-duration generation computationally feasible, we introduce an efficiency strategy: Joint generation of low resolution full sequences and high-resolution keyframes, followed by dedicated super-resolution and frame interpolation models. To our knowledge, SkyReels V4 is the first video foundation model that simultaneously supports multi-modal input, joint video audio generation, and a unified treatment of generation, inpainting, and editing, while maintaining strong efficiency and quality at cinematic resolutions and durations.
SkyReels-V3 Technique Report
Jan 24, 2026Video generation serves as a cornerstone for building world models, where multimodal contextual inference stands as the defining test of capability. In this end, we present SkyReels-V3, a conditional video generation model, built upon a unified multimodal in-context learning framework with diffusion Transformers. SkyReels-V3 model supports three core generative paradigms within a single architecture: reference images-to-video synthesis, video-to-video extension and audio-guided video generation. (i) reference images-to-video model is designed to produce high-fidelity videos with strong subject identity preservation, temporal coherence, and narrative consistency. To enhance reference adherence and compositional stability, we design a comprehensive data processing pipeline that leverages cross frame pairing, image editing, and semantic rewriting, effectively mitigating copy paste artifacts. During training, an image video hybrid strategy combined with multi-resolution joint optimization is employed to improve generalization and robustness across diverse scenarios. (ii) video extension model integrates spatio-temporal consistency modeling with large-scale video understanding, enabling both seamless single-shot continuation and intelligent multi-shot switching with professional cinematographic patterns. (iii) Talking avatar model supports minute-level audio-conditioned video generation by training first-and-last frame insertion patterns and reconstructing key-frame inference paradigms. On the basis of ensuring visual quality, synchronization of audio and videos has been optimized. Extensive evaluations demonstrate that SkyReels-V3 achieves state-of-the-art or near state-of-the-art performance on key metrics including visual quality, instruction following, and specific aspect metrics, approaching leading closed-source systems. Github: https://github.com/SkyworkAI/SkyReels-V3.
SkyReels-A2: Compose Anything in Video Diffusion Transformers
Apr 03, 2025



This paper presents SkyReels-A2, a controllable video generation framework capable of assembling arbitrary visual elements (e.g., characters, objects, backgrounds) into synthesized videos based on textual prompts while maintaining strict consistency with reference images for each element. We term this task elements-to-video (E2V), whose primary challenges lie in preserving the fidelity of each reference element, ensuring coherent composition of the scene, and achieving natural outputs. To address these, we first design a comprehensive data pipeline to construct prompt-reference-video triplets for model training. Next, we propose a novel image-text joint embedding model to inject multi-element representations into the generative process, balancing element-specific consistency with global coherence and text alignment. We also optimize the inference pipeline for both speed and output stability. Moreover, we introduce a carefully curated benchmark for systematic evaluation, i.e, A2 Bench. Experiments demonstrate that our framework can generate diverse, high-quality videos with precise element control. SkyReels-A2 is the first open-source commercial grade model for the generation of E2V, performing favorably against advanced closed-source commercial models. We anticipate SkyReels-A2 will advance creative applications such as drama and virtual e-commerce, pushing the boundaries of controllable video generation.
MARS: Multimodal Active Robotic Sensing for Articulated Characterization
Jul 01, 2024



Precise perception of articulated objects is vital for empowering service robots. Recent studies mainly focus on point cloud, a single-modal approach, often neglecting vital texture and lighting details and assuming ideal conditions like optimal viewpoints, unrepresentative of real-world scenarios. To address these limitations, we introduce MARS, a novel framework for articulated object characterization. It features a multi-modal fusion module utilizing multi-scale RGB features to enhance point cloud features, coupled with reinforcement learning-based active sensing for autonomous optimization of observation viewpoints. In experiments conducted with various articulated object instances from the PartNet-Mobility dataset, our method outperformed current state-of-the-art methods in joint parameter estimation accuracy. Additionally, through active sensing, MARS further reduces errors, demonstrating enhanced efficiency in handling suboptimal viewpoints. Furthermore, our method effectively generalizes to real-world articulated objects, enhancing robot interactions. Code is available at https://github.com/robhlzeng/MARS.
Masked Generative Extractor for Synergistic Representation and 3D Generation of Point Clouds
Jun 25, 2024
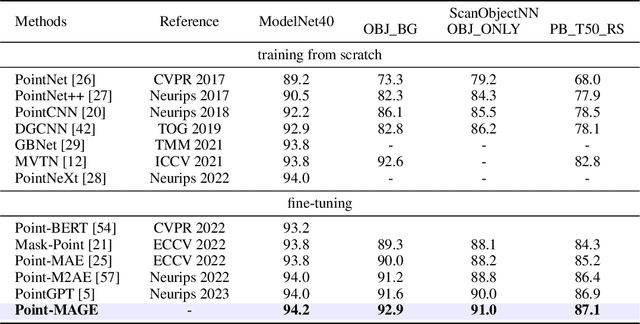
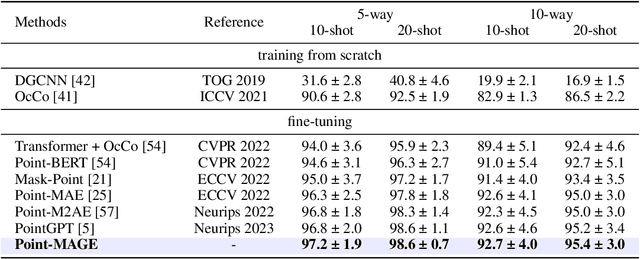
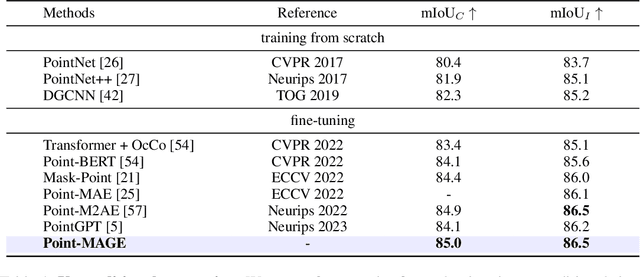
In the field of 2D image generation modeling and representation learning, Masked Generative Encoder (MAGE) has demonstrated the synergistic potential between generative modeling and representation learning. Inspired by this, we propose Point-MAGE to extend this concept to point cloud data. Specifically, this framework first utilizes a Vector Quantized Variational Autoencoder (VQVAE) to reconstruct a neural field representation of 3D shapes, thereby learning discrete semantic features of point patches. Subsequently, by combining the masking model with variable masking ratios, we achieve synchronous training for both generation and representation learning. Furthermore, our framework seamlessly integrates with existing point cloud self-supervised learning (SSL) models, thereby enhancing their performance. We extensively evaluate the representation learning and generation capabilities of Point-MAGE. In shape classification tasks, Point-MAGE achieved an accuracy of 94.2% on the ModelNet40 dataset and 92.9% (+1.3%) on the ScanObjectNN dataset. Additionally, it achieved new state-of-the-art performance in few-shot learning and part segmentation tasks. Experimental results also confirmed that Point-MAGE can generate detailed and high-quality 3D shapes in both unconditional and conditional settings.
FSMR: A Feature Swapping Multi-modal Reasoning Approach with Joint Textual and Visual Clues
Mar 29, 2024Multi-modal reasoning plays a vital role in bridging the gap between textual and visual information, enabling a deeper understanding of the context. This paper presents the Feature Swapping Multi-modal Reasoning (FSMR) model, designed to enhance multi-modal reasoning through feature swapping. FSMR leverages a pre-trained visual-language model as an encoder, accommodating both text and image inputs for effective feature representation from both modalities. It introduces a unique feature swapping module, enabling the exchange of features between identified objects in images and corresponding vocabulary words in text, thereby enhancing the model's comprehension of the interplay between images and text. To further bolster its multi-modal alignment capabilities, FSMR incorporates a multi-modal cross-attention mechanism, facilitating the joint modeling of textual and visual information. During training, we employ image-text matching and cross-entropy losses to ensure semantic consistency between visual and language elements. Extensive experiments on the PMR dataset demonstrate FSMR's superiority over state-of-the-art baseline models across various performance metrics.
Graph Neural Networks are Inherently Good Generalizers: Insights by Bridging GNNs and MLPs
Dec 18, 2022



Graph neural networks (GNNs), as the de-facto model class for representation learning on graphs, are built upon the multi-layer perceptrons (MLP) architecture with additional message passing layers to allow features to flow across nodes. While conventional wisdom largely attributes the success of GNNs to their advanced expressivity for learning desired functions on nodes' ego-graphs, we conjecture that this is \emph{not} the main cause of GNNs' superiority in node prediction tasks. This paper pinpoints the major source of GNNs' performance gain to their intrinsic generalization capabilities, by introducing an intermediate model class dubbed as P(ropagational)MLP, which is identical to standard MLP in training, and then adopt GNN's architecture in testing. Intriguingly, we observe that PMLPs consistently perform on par with (or even exceed) their GNN counterparts across ten benchmarks and different experimental settings, despite the fact that PMLPs share the same (trained) weights with poorly-performed MLP. This critical finding opens a door to a brand new perspective for understanding the power of GNNs, and allow bridging GNNs and MLPs for dissecting their generalization behaviors. As an initial step to analyze PMLP, we show its essential difference with MLP at infinite-width limit lies in the NTK feature map in the post-training stage. Moreover, though MLP and PMLP cannot extrapolate non-linear functions for extreme OOD data, PMLP has more freedom to generalize near the training support.