 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Multimodal Active Robotic Sensing for Articulated Characterization
Jul 01, 2024



Precise perception of articulated objects is vital for empowering service robots. Recent studies mainly focus on point cloud, a single-modal approach, often neglecting vital texture and lighting details and assuming ideal conditions like optimal viewpoints, unrepresentative of real-world scenarios. To address these limitations, we introduce MARS, a novel framework for articulated object characterization. It features a multi-modal fusion module utilizing multi-scale RGB features to enhance point cloud features, coupled with reinforcement learning-based active sensing for autonomous optimization of observation viewpoints. In experiments conducted with various articulated object instances from the PartNet-Mobility dataset, our method outperformed current state-of-the-art methods in joint parameter estimation accuracy. Additionally, through active sensing, MARS further reduces errors, demonstrating enhanced efficiency in handling suboptimal viewpoints. Furthermore, our method effectively generalizes to real-world articulated objects, enhancing robot interactions. Code is available at https://github.com/robhlzeng/MARS.
Masked Generative Extractor for Synergistic Representation and 3D Generation of Point Clouds
Jun 25, 2024
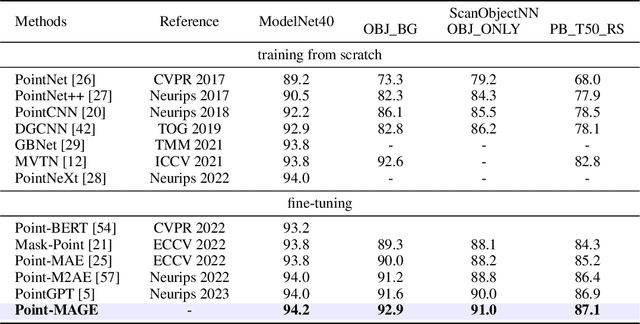
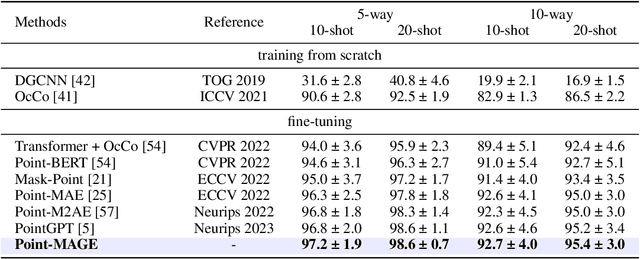
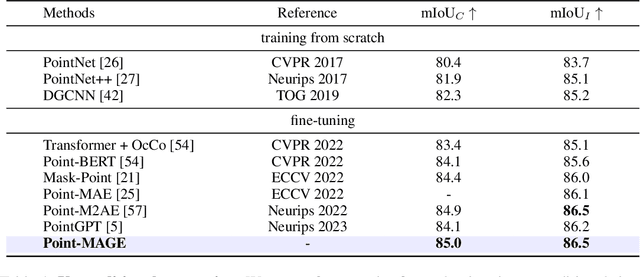
In the field of 2D image generation modeling and representation learning, Masked Generative Encoder (MAGE) has demonstrated the synergistic potential between generative modeling and representation learning. Inspired by this, we propose Point-MAGE to extend this concept to point cloud data. Specifically, this framework first utilizes a Vector Quantized Variational Autoencoder (VQVAE) to reconstruct a neural field representation of 3D shapes, thereby learning discrete semantic features of point patches. Subsequently, by combining the masking model with variable masking ratios, we achieve synchronous training for both generation and representation learning. Furthermore, our framework seamlessly integrates with existing point cloud self-supervised learning (SSL) models, thereby enhancing their performance. We extensively evaluate the representation learning and generation capabilities of Point-MAGE. In shape classification tasks, Point-MAGE achieved an accuracy of 94.2% on the ModelNet40 dataset and 92.9% (+1.3%) on the ScanObjectNN dataset. Additionally, it achieved new state-of-the-art performance in few-shot learning and part segmentation tasks. Experimental results also confirmed that Point-MAGE can generate detailed and high-quality 3D shapes in both unconditional and conditional settings.