 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-V3 Technique Report
Jan 24, 2026Video generation serves as a cornerstone for building world models, where multimodal contextual inference stands as the defining test of capability. In this end, we present SkyReels-V3, a conditional video generation model, built upon a unified multimodal in-context learning framework with diffusion Transformers. SkyReels-V3 model supports three core generative paradigms within a single architecture: reference images-to-video synthesis, video-to-video extension and audio-guided video generation. (i) reference images-to-video model is designed to produce high-fidelity videos with strong subject identity preservation, temporal coherence, and narrative consistency. To enhance reference adherence and compositional stability, we design a comprehensive data processing pipeline that leverages cross frame pairing, image editing, and semantic rewriting, effectively mitigating copy paste artifacts. During training, an image video hybrid strategy combined with multi-resolution joint optimization is employed to improve generalization and robustness across diverse scenarios. (ii) video extension model integrates spatio-temporal consistency modeling with large-scale video understanding, enabling both seamless single-shot continuation and intelligent multi-shot switching with professional cinematographic patterns. (iii) Talking avatar model supports minute-level audio-conditioned video generation by training first-and-last frame insertion patterns and reconstructing key-frame inference paradigms. On the basis of ensuring visual quality, synchronization of audio and videos has been optimized. Extensive evaluations demonstrate that SkyReels-V3 achieves state-of-the-art or near state-of-the-art performance on key metrics including visual quality, instruction following, and specific aspect metrics, approaching leading closed-source systems. Github: https://github.com/SkyworkAI/SkyReels-V3.
SkyReels-A2: Compose Anything in Video Diffusion Transformers
Apr 03, 2025



This paper presents SkyReels-A2, a controllable video generation framework capable of assembling arbitrary visual elements (e.g., characters, objects, backgrounds) into synthesized videos based on textual prompts while maintaining strict consistency with reference images for each element. We term this task elements-to-video (E2V), whose primary challenges lie in preserving the fidelity of each reference element, ensuring coherent composition of the scene, and achieving natural outputs. To address these, we first design a comprehensive data pipeline to construct prompt-reference-video triplets for model training. Next, we propose a novel image-text joint embedding model to inject multi-element representations into the generative process, balancing element-specific consistency with global coherence and text alignment. We also optimize the inference pipeline for both speed and output stability. Moreover, we introduce a carefully curated benchmark for systematic evaluation, i.e, A2 Bench. Experiments demonstrate that our framework can generate diverse, high-quality videos with precise element control. SkyReels-A2 is the first open-source commercial grade model for the generation of E2V, performing favorably against advanced closed-source commercial models. We anticipate SkyReels-A2 will advance creative applications such as drama and virtual e-commerce, pushing the boundaries of controllable video generation.
AdaZoom: Adaptive Zoom Network for Multi-Scale Object Detection in Large Scenes
Jun 19, 2021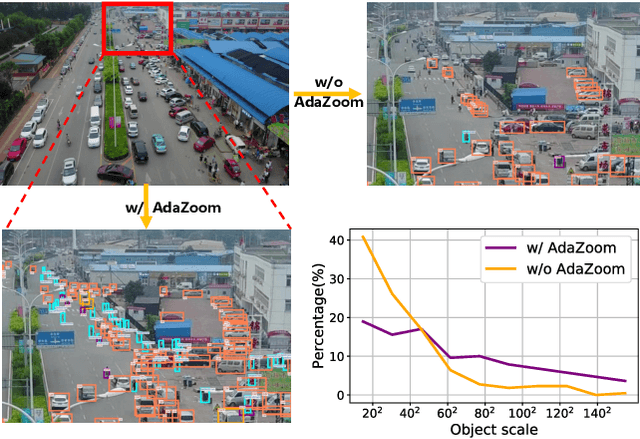


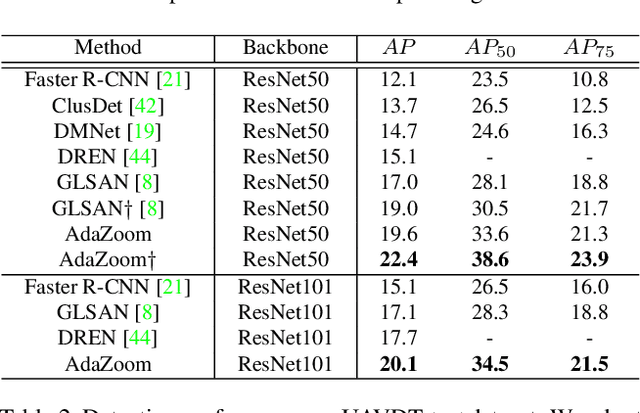
Detection in large-scale scenes is a challenging problem due to small objects and extreme scale variation. It is essential to focus on the image regions of small objects. In this paper, we propose a novel Adaptive Zoom (AdaZoom) network as a selective magnifier with flexible shape and focal length to adaptively zoom the focus regions for object detection. Based on policy gradient, we construct a reinforcement learning framework for focus region generation, with the reward formulated by object distributions. The scales and aspect ratios of the generated regions are adaptive to the scales and distribution of objects inside. We apply variable magnification according to the scale of the region for adaptive multi-scale detection. We further propose collaborative training to complementarily promote the performance of AdaZoom and the detection network. To validate the effectiveness, we conduct extensive experiments on VisDrone2019, UAVDT, and DOTA datasets. The experiments show AdaZoom brings a consistent and significant improvement over different detection networks, achieving state-of-the-art performance on these datasets, especially outperforming the existing methods by AP of 4.64% on Vis-Drone2019.