 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkyReels-Text: Fine-grained Font-Controllable Text Editing for Poster Design
Nov 17, 2025Artistic design such as poster design often demands rapid yet precise modification of textual content while preserving visual harmony and typographic intent, especially across diverse font styles. Although modern image editing models have grown increasingly powerful, they still fall short in fine-grained, font-aware text manipulation, limiting their utility in professional design workflows such as poster editing. To address this issue, we present SkyReels-Text, a novel font-controllable framework for precise poster text editing. Our method enables simultaneous editing of multiple text regions, each rendered in distinct typographic styles, while preserving the visual appearance of non-edited regions. Notably, our model requires neither font labels nor fine-tuning during inference: users can simply provide cropped glyph patches corresponding to their desired typography, even if the font is not included in any standard library. Extensive experiments on multiple datasets, including handwrittent text benchmarks, SkyReels-Text achieves state-of-the-art performance in both text fidelity and visual realism, offering unprecedented control over font families, and stylistic nuances. This work bridges the gap between general-purpose image editing and professional-grade typographic design.
SkyReels-V2: Infinite-length Film Generative Model
Apr 21, 2025Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs' inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation. To address these limitations, we propose SkyReels-V2, an Infinite-length Film Generative Model, that synergizes Multi-modal Large Language Model (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing Framework. Firstly, we design a comprehensive structural representation of video that combines the general descriptions by the Multi-modal LLM and the detailed shot language by sub-expert models. Aided with human annotation, we then train a unified Video Captioner, named SkyCaptioner-V1, to efficiently label the video data. Secondly, we establish progressive-resolution pretraining for the fundamental video generation, followed by a four-stage post-training enhancement: Initial concept-balanced Supervised Fine-Tuning (SFT) improves baseline quality; Motion-specific Reinforcement Learning (RL) training with human-annotated and synthetic distortion data addresses dynamic artifacts; Our diffusion forcing framework with non-decreasing noise schedules enables long-video synthesis in an efficient search space; Final high-quality SFT refines visual fidelity. All the code and models are available at https://github.com/SkyworkAI/SkyReels-V2.
Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion
Mar 25, 2022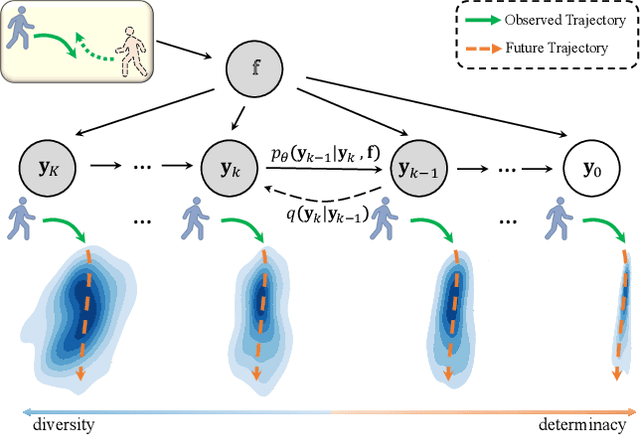
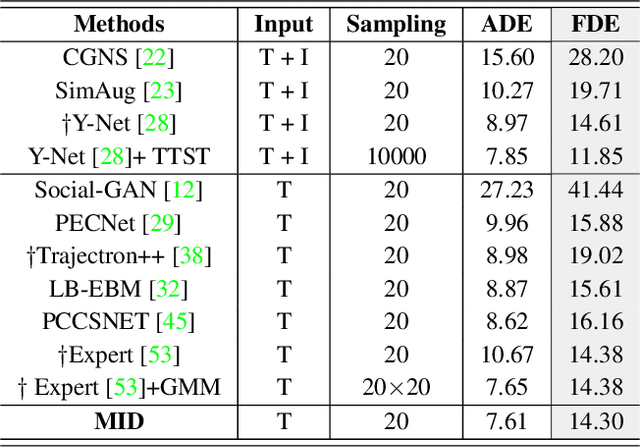
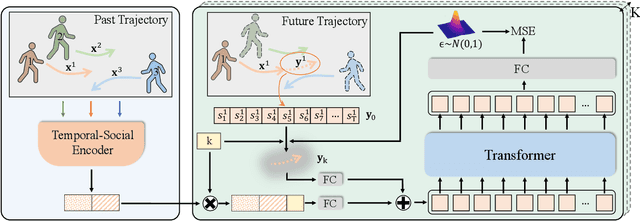
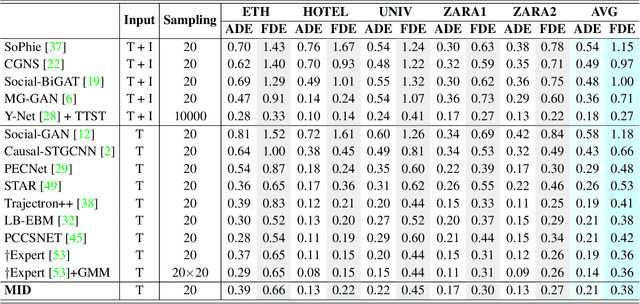
Human behavior has the nature of indeterminacy, which requires the pedestrian trajectory prediction system to model the multi-modality of future motion states. Unlike existing stochastic trajectory prediction methods which usually use a latent variable to represent multi-modality, we explicitly simulate the process of human motion variation from indeterminate to determinate. In this paper, we present a new framework to formulate the trajectory prediction task as a reverse process of motion indeterminacy diffusion (MID), in which we progressively discard indeterminacy from all the walkable areas until reaching the desired trajectory. This process is learned with a parameterized Markov chain conditioned by the observed trajectories. We can adjust the length of the chain to control the degree of indeterminacy and balance the diversity and determinacy of the predictions. Specifically, we encode the history behavior information and the social interactions as a state embedding and devise a Transformer-based diffusion model to capture the temporal dependencies of trajectories. Extensive experiments on the human trajectory prediction benchmarks including the Stanford Drone and ETH/UCY datasets demonstrate the superiority of our method. Code is available at https://github.com/gutianpei/MID.
Bailando: 3D Dance Generation by Actor-Critic GPT with Choreographic Memory
Mar 25, 2022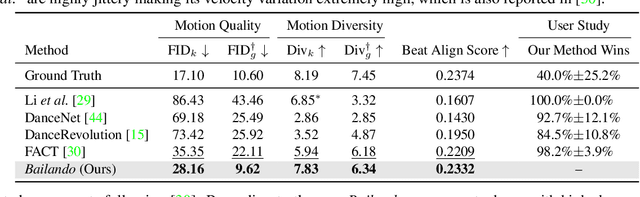
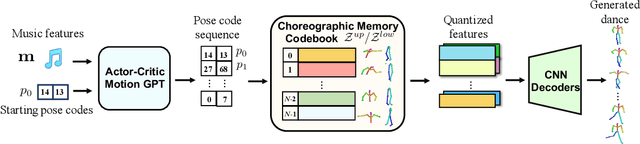
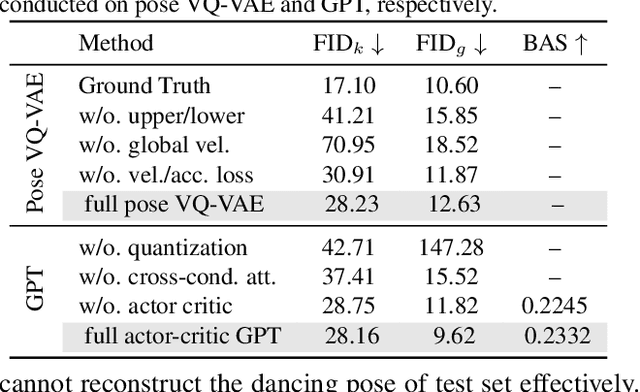
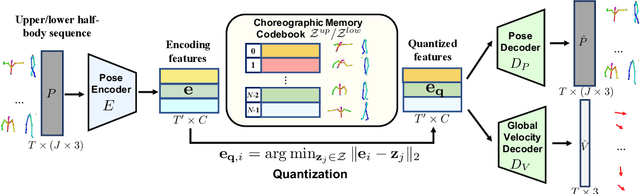
Driving 3D characters to dance following a piece of music is highly challenging due to the spatial constraints applied to poses by choreography norms. In addition, the generated dance sequence also needs to maintain temporal coherency with different music genres. To tackle these challenges, we propose a novel music-to-dance framework, Bailando, with two powerful components: 1) a choreographic memory that learns to summarize meaningful dancing units from 3D pose sequence to a quantized codebook, 2) an actor-critic Generative Pre-trained Transformer (GPT) that composes these units to a fluent dance coherent to the music. With the learned choreographic memory, dance generation is realized on the quantized units that meet high choreography standards, such that the generated dancing sequences are confined within the spatial constraints. To achieve synchronized alignment between diverse motion tempos and music beats, we introduce an actor-critic-based reinforcement learning scheme to the GPT with a newly-designed beat-align reward function. Extensive experiments on the standard benchmark demonstrate that our proposed framework achieves state-of-the-art performance both qualitatively and quantitatively. Notably, the learned choreographic memory is shown to discover human-interpretable dancing-style poses in an unsupervised manner.
Fast and Accurate: Structure Coherence Component for Face Alignment
Jun 21, 2020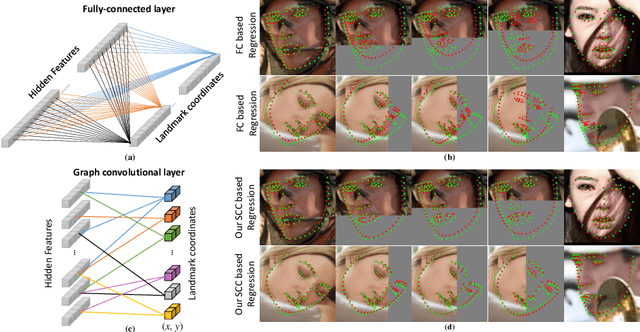
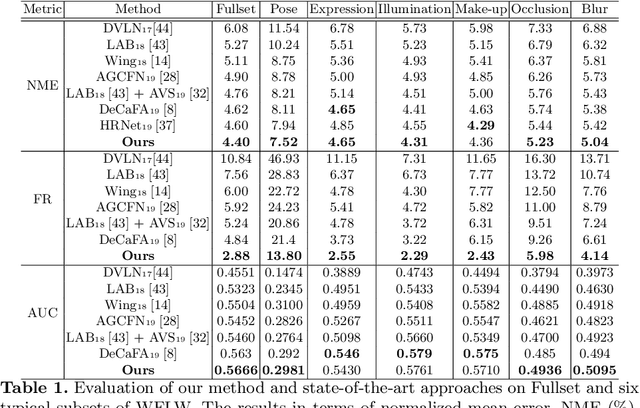
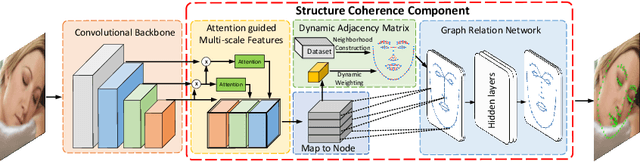
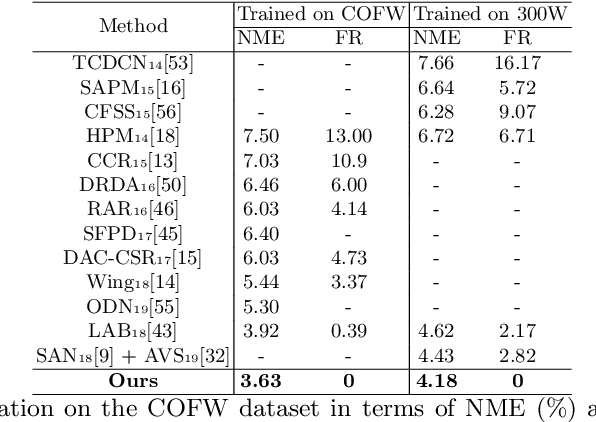
In this paper, we propose a fast and accurate coordinate regression method for face alignment. Unlike most existing facial landmark regression methods which usually employ fully connected layers to convert feature maps into landmark coordinate, we present a structure coherence component to explicitly take the relation among facial landmarks into account. Due to the geometric structure of human face, structure coherence between different facial parts provides important cues for effectively localizing facial landmarks. However, the dense connection in the fully connected layers overuses such coherence, making the important cues unable to be distinguished from all connections. Instead, our structure coherence component leverages a dynamic sparse graph structure to passing features among the most related landmarks. Furthermore, we propose a novel objective function, named Soft Wing loss, to improve the accuracy. Extensive experiments on three popular benchmarks, including WFLW, COFW and 300W, demonstrate the effectiveness of the proposed method, achieving state-of-the-art performance with fast speed. Our approach is especially robust to challenging cases resulting in impressively low failure rate (0% and 2.88%) in COFW and WFLW datasets.