 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
Sep 05, 2025

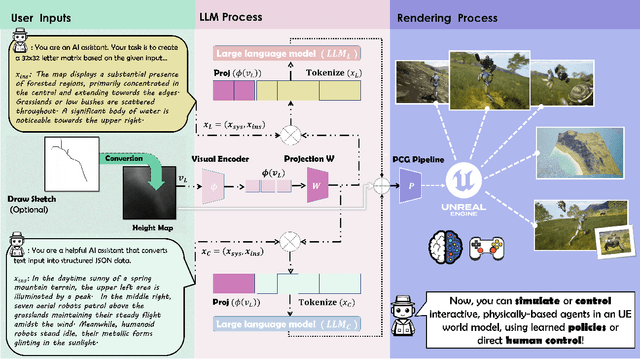
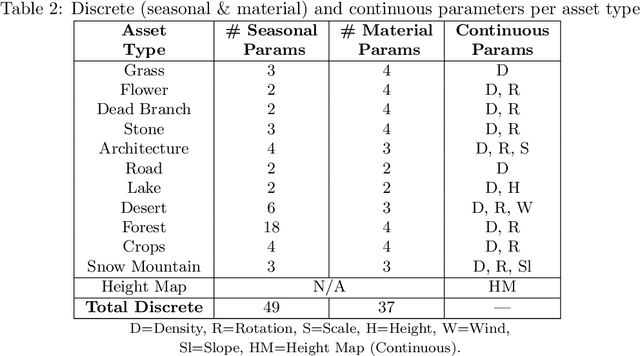
Recent research has been increasingly focusing on developing 3D world models that simulate complex real-world scenarios. World models have found broad applications across various domains, including embodied AI, autonomous driving, entertainment, etc. A more realistic simulation with accurate physics will effectively narrow the sim-to-real gap and allow us to gather rich information about the real world conveniently. While traditional manual modeling has enabled the creation of virtual 3D scenes, modern approaches have leveraged advanced machine learning algorithms for 3D world generation, with most recent advances focusing on generative methods that can create virtual worlds based on user instructions. This work explores such a research direction by proposing LatticeWorld, a simple yet effective 3D world generation framework that streamlines the industrial production pipeline of 3D environments. LatticeWorld leverages lightweight LLMs (LLaMA-2-7B) alongside the industry-grade rendering engine (e.g., Unreal Engine 5) to generate a dynamic environment. Our proposed framework accepts textual descriptions and visual instructions as multimodal inputs and creates large-scale 3D interactive worlds with dynamic agents, featuring competitive multi-agent interaction, high-fidelity physics simulation, and real-time rendering. We conduct comprehensive experiments to evaluate LatticeWorld, showing that it achieves superior accuracy in scene layout generation and visual fidelity. Moreover, LatticeWorld achieves over a $90\times$ increase in industrial production efficiency while maintaining high creative quality compared with traditional manual production methods. Our demo video is available at https://youtu.be/8VWZXpERR18
Single-Shot Motion Completion with Transformer
Mar 01, 2021
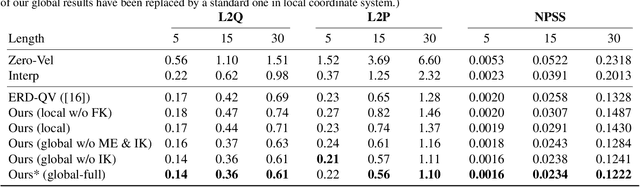
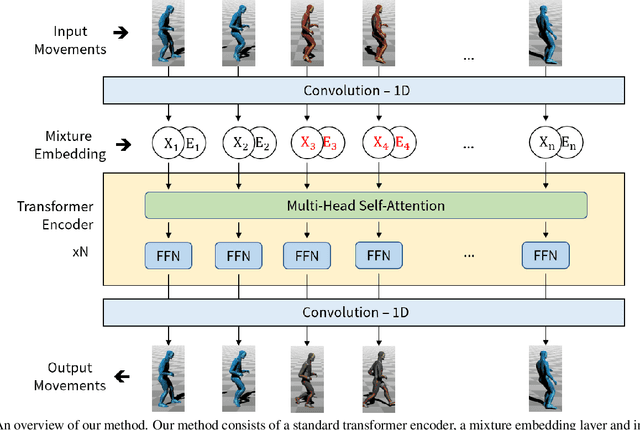
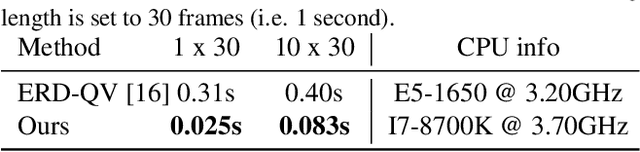
Motion completion is a challenging and long-discussed problem, which is of great significance in film and game applications. For different motion completion scenarios (in-betweening, in-filling, and blending), most previous methods deal with the completion problems with case-by-case designs. In this work, we propose a simple but effective method to solve multiple motion completion problems under a unified framework and achieves a new state of the art accuracy under multiple evaluation settings. Inspired by the recent great success of attention-based models, we consider the completion as a sequence to sequence prediction problem. Our method consists of two modules - a standard transformer encoder with self-attention that learns long-range dependencies of input motions, and a trainable mixture embedding module that models temporal information and discriminates key-frames. Our method can run in a non-autoregressive manner and predict multiple missing frames within a single forward propagation in real time. We finally show the effectiveness of our method in music-dance applications.
Semi-Supervised Learning for In-Game Expert-Level Music-to-Dance Translation
Sep 27, 2020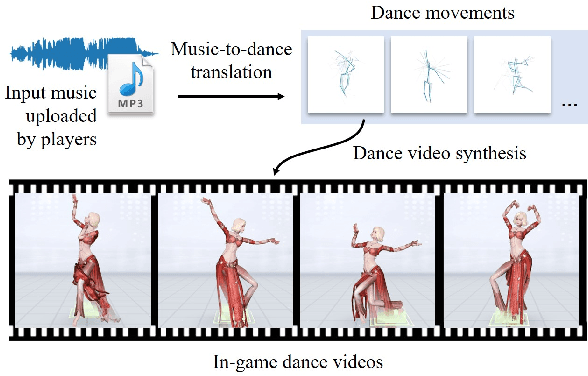

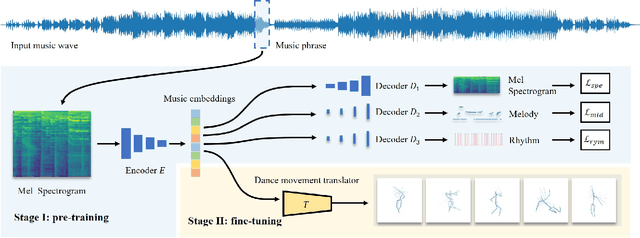

Music-to-dance translation is a brand-new and powerful feature in recent role-playing games. Players can now let their characters dance along with specified music clips and even generate fan-made dance videos. Previous works of this topic consider music-to-dance as a supervised motion generation problem based on time-series data. However, these methods suffer from limited training data pairs and the degradation of movements. This paper provides a new perspective for this task where we re-formulate the translation problem as a piece-wise dance phrase retrieval problem based on the choreography theory. With such a design, players are allowed to further edit the dance movements on top of our generation while other regression based methods ignore such user interactivity. Considering that the dance motion capture is an expensive and time-consuming procedure which requires the assistance of professional dancers, we train our method under a semi-supervised learning framework with a large unlabeled dataset (20x than labeled data) collected. A co-ascent mechanism is introduced to improve the robustness of our network. Using this unlabeled dataset, we also introduce self-supervised pre-training so that the translator can understand the melody, rhythm, and other components of music phrases. We show that the pre-training significantly improves the translation accuracy than that of training from scratch. Experimental results suggest that our method not only generalizes well over various styles of music but also succeeds in expert-level choreography for game players.