 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models Struggle to Learn Long-Tail Knowledge
Paper and Code
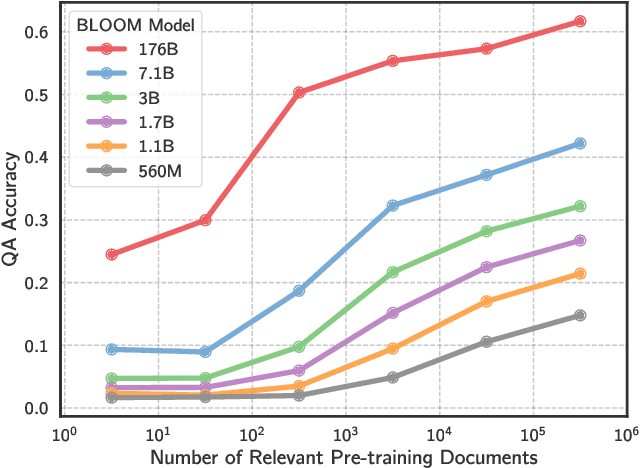
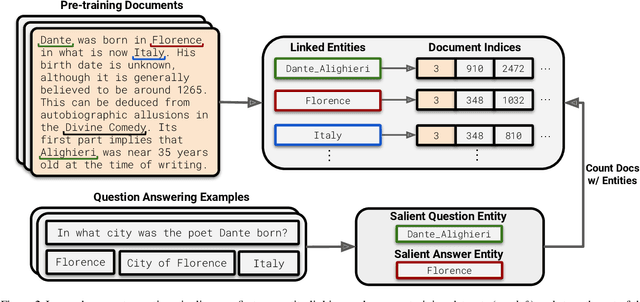
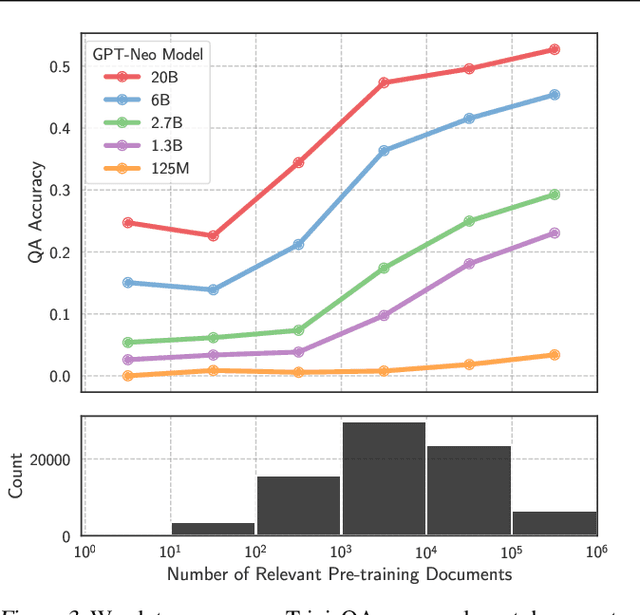
The internet contains a wealth of knowledge -- from the birthdays of historical figures to tutorials on how to code -- all of which may be learned by language models. However, there is a huge variability in the number of times a given piece of information appears on the web. In this paper, we study the relationship between the knowledge memorized by large language models and the information in their pre-training datasets. In particular, we show that a language model's ability to answer a fact-based question relates to how many documents associated with that question were seen during pre-training. We identify these relevant documents by entity linking pre-training datasets and counting documents that contain the same entities as a given question-answer pair. Our results demonstrate strong correlational and causal relationships between accuracy and relevant document count for numerous question answering datasets (e.g., TriviaQA), pre-training corpora (e.g., ROOTS), and model sizes (e.g., 176B parameters). Moreover, we find that while larger models are better at learning long-tail knowledge, we estimate that today's models must be scaled by many orders of magnitude to reach competitive QA performance on questions with little support in the pre-training data. Finally, we show that retrieval-augmentation can reduce the dependence on relevant document count, presenting a promising approach for capturing the long-tail.