 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Part-Based Global Explanations Via Correspondence
Sep 18, 2025Deep learning models are notoriously opaque. Existing explanation methods often focus on localized visual explanations for individual images. Concept-based explanations, while offering global insights, require extensive annotations, incurring significant labeling cost. We propose an approach that leverages user-defined part labels from a limited set of images and efficiently transfers them to a larger dataset. This enables the generation of global symbolic explanations by aggregating part-based local explanations, ultimately providing human-understandable explanations for model decisions on a large scale.
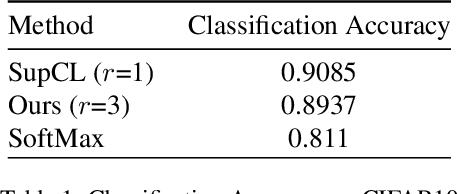
Contrastive Learning for Object Detection
Aug 12, 2022

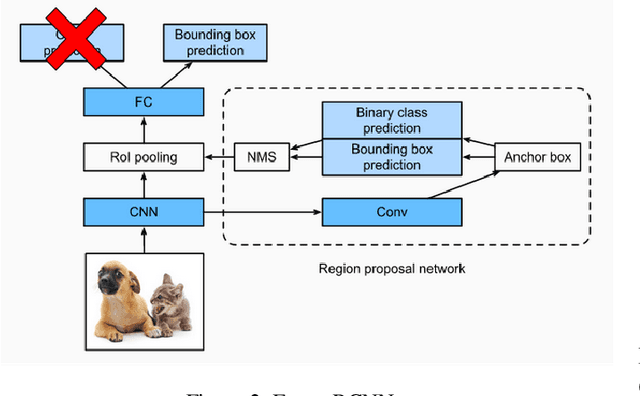
Contrastive learning is commonly used as a method of self-supervised learning with the "anchor" and "positive" being two random augmentations of a given input image, and the "negative" is the set of all other images. However, the requirement of large batch sizes and memory banks has made it difficult and slow to train. This has motivated the rise of Supervised Contrasative approaches that overcome these problems by using annotated data. We look to further improve supervised contrastive learning by ranking classes based on their similarity, and observe the impact of human bias (in the form of ranking) on the learned representations. We feel this is an important question to address, as learning good feature embeddings has been a long sought after problem in computer vision.
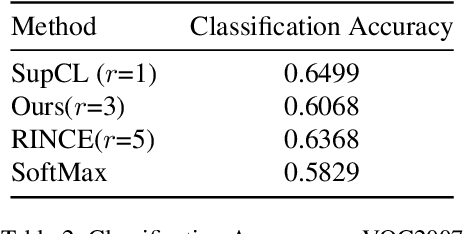
Contrastive Learning for OOD in Object detection
Aug 12, 2022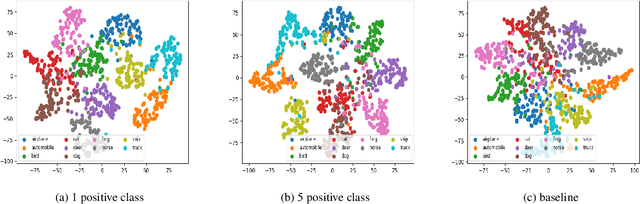
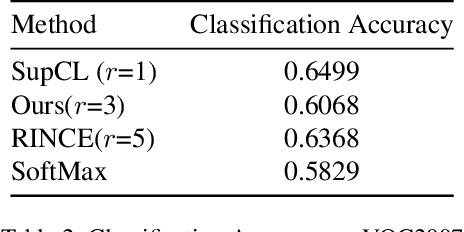
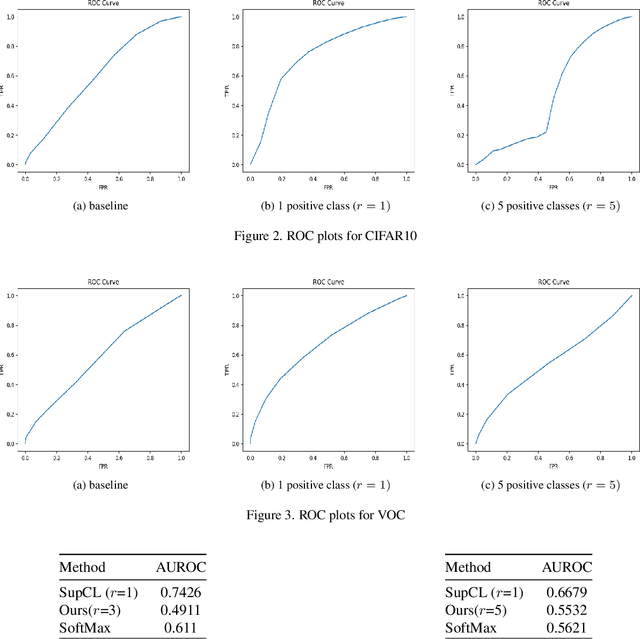
Contrastive learning is commonly applied to self-supervised learning, and has been shown to outperform traditional approaches such as the triplet loss and N-pair loss. However, the requirement of large batch sizes and memory banks has made it difficult and slow to train. Recently, Supervised Contrasative approaches have been developed to overcome these problems. They focus more on learning a good representation for each class individually, or between a cluster of classes. In this work we attempt to rank classes based on similarity using a user-defined ranking, to learn an efficient representation between all classes. We observe how incorporating human bias into the learning process could improve learning representations in the parameter space. We show that our results are comparable to Supervised Contrastive Learning for image classification and object detection, and discuss it's shortcomings in OOD Detection