 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Jul 04, 2024



We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
On The Open Prompt Challenge In Conditional Audio Generation
Nov 01, 2023
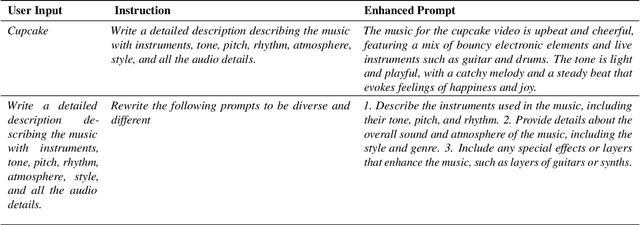
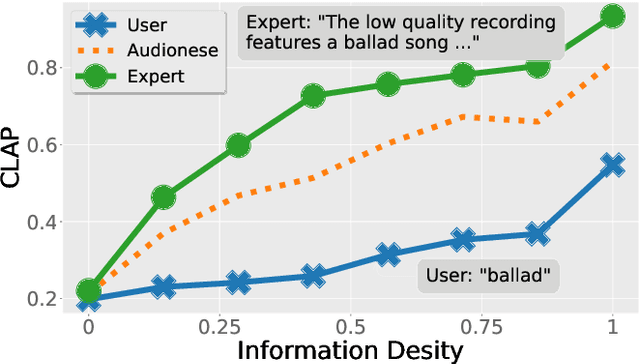
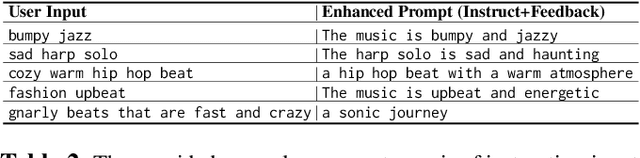
Text-to-audio generation (TTA) produces audio from a text description, learning from pairs of audio samples and hand-annotated text. However, commercializing audio generation is challenging as user-input prompts are often under-specified when compared to text descriptions used to train TTA models. In this work, we treat TTA models as a ``blackbox'' and address the user prompt challenge with two key insights: (1) User prompts are generally under-specified, leading to a large alignment gap between user prompts and training prompts. (2) There is a distribution of audio descriptions for which TTA models are better at generating higher quality audio, which we refer to as ``audionese''. To this end, we rewrite prompts with instruction-tuned models and propose utilizing text-audio alignment as feedback signals via margin ranking learning for audio improvements. On both objective and subjective human evaluations, we observed marked improvements in both text-audio alignment and music audio quality.
In-Context Prompt Editing For Conditional Audio Generation
Nov 01, 2023Distributional shift is a central challenge in the deployment of machine learning models as they can be ill-equipped for real-world data. This is particularly evident in text-to-audio generation where the encoded representations are easily undermined by unseen prompts, which leads to the degradation of generated audio -- the limited set of the text-audio pairs remains inadequate for conditional audio generation in the wild as user prompts are under-specified. In particular, we observe a consistent audio quality degradation in generated audio samples with user prompts, as opposed to training set prompts. To this end, we present a retrieval-based in-context prompt editing framework that leverages the training captions as demonstrative exemplars to revisit the user prompts. We show that the framework enhanced the audio quality across the set of collected user prompts, which were edited with reference to the training captions as exemplars.