 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting English Winogender Schemas for Consistency, Coverage, and Grammatical Case
Sep 09, 2024

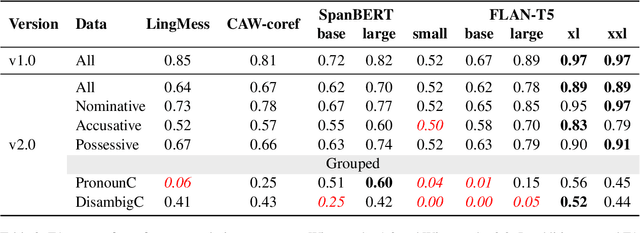
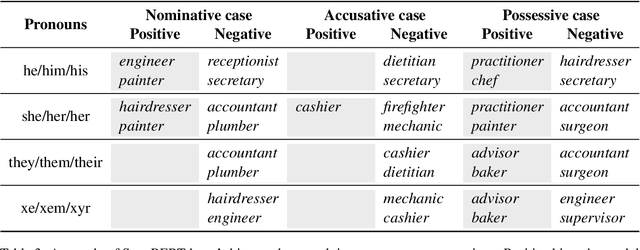
While measuring bias and robustness in coreference resolution are important goals, such measurements are only as good as the tools we use to measure them with. Winogender schemas (Rudinger et al., 2018) are an influential dataset proposed to evaluate gender bias in coreference resolution, but a closer look at the data reveals issues with the instances that compromise their use for reliable evaluation, including treating different grammatical cases of pronouns in the same way, violations of template constraints, and typographical errors. We identify these issues and fix them, contributing a new dataset: Winogender 2.0. Our changes affect performance with state-of-the-art supervised coreference resolution systems as well as all model sizes of the language model FLAN-T5, with F1 dropping on average 0.1 points. We also propose a new method to evaluate pronominal bias in coreference resolution that goes beyond the binary. With this method and our new dataset which is balanced for grammatical case, we empirically demonstrate that bias characteristics vary not just across pronoun sets, but also across surface forms of those sets.
Large GPT-like Models are Bad Babies: A Closer Look at the Relationship between Linguistic Competence and Psycholinguistic Measures
Nov 08, 2023Research on the cognitive plausibility of language models (LMs) has so far mostly concentrated on modelling psycholinguistic response variables such as reading times, gaze durations and N400/P600 EEG signals, while mostly leaving out the dimension of what Mahowald et al. (2023) described as formal and functional linguistic competence, and developmental plausibility. We address this gap by training a series of GPT-like language models of different sizes on the strict version of the BabyLM pretraining corpus, evaluating on the challenge tasks (BLiMP, GLUE, MSGS) and an additional reading time prediction task. We find a positive correlation between LM size and performance on all three challenge tasks, with different preferences for model width and depth in each of the tasks. In contrast, a negative correlation was found between LM size and reading time fit of linear mixed-effects models using LM surprisal as a predictor, with the second-smallest LM achieving the largest log-likelihood reduction over a baseline model without surprisal. This suggests that modelling processing effort and linguistic competence may require an approach different from training GPT-like LMs on a developmentally plausible corpus.
Information-Theoretic Characterization of Vowel Harmony: A Cross-Linguistic Study on Word Lists
Aug 09, 2023



We present a cross-linguistic study that aims to quantify vowel harmony using data-driven computational modeling. Concretely, we define an information-theoretic measure of harmonicity based on the predictability of vowels in a natural language lexicon, which we estimate using phoneme-level language models (PLMs). Prior quantitative studies have relied heavily on inflected word-forms in the analysis of vowel harmony. We instead train our models using cross-linguistically comparable lemma forms with little or no inflection, which enables us to cover more under-studied languages. Training data for our PLMs consists of word lists with a maximum of 1000 entries per language. Despite the fact that the data we employ are substantially smaller than previously used corpora, our experiments demonstrate the neural PLMs capture vowel harmony patterns in a set of languages that exhibit this phenomenon. Our work also demonstrates that word lists are a valuable resource for typological research, and offers new possibilities for future studies on low-resource, under-studied languages.