 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting English Winogender Schemas for Consistency, Coverage, and Grammatical Case
Paper and Code


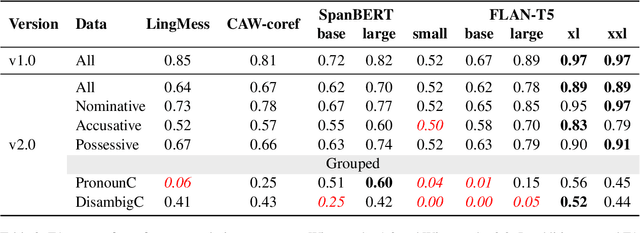
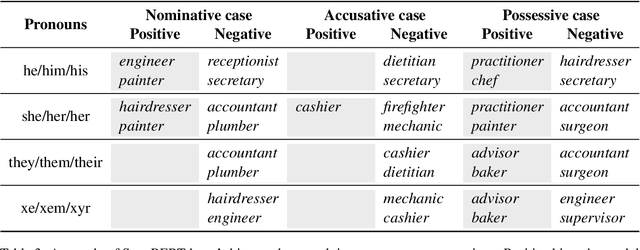
While measuring bias and robustness in coreference resolution are important goals, such measurements are only as good as the tools we use to measure them with. Winogender schemas (Rudinger et al., 2018) are an influential dataset proposed to evaluate gender bias in coreference resolution, but a closer look at the data reveals issues with the instances that compromise their use for reliable evaluation, including treating different grammatical cases of pronouns in the same way, violations of template constraints, and typographical errors. We identify these issues and fix them, contributing a new dataset: Winogender 2.0. Our changes affect performance with state-of-the-art supervised coreference resolution systems as well as all model sizes of the language model FLAN-T5, with F1 dropping on average 0.1 points. We also propose a new method to evaluate pronominal bias in coreference resolution that goes beyond the binary. With this method and our new dataset which is balanced for grammatical case, we empirically demonstrate that bias characteristics vary not just across pronoun sets, but also across surface forms of those sets.