 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Optimizing Multimodal Jailbreaks for Spoken Language Models
Mar 19, 2026As Spoken Language Models (SLMs) integrate speech and text modalities, they inherit the safety vulnerabilities of their LLM backbone and an expanded attack surface. SLMs have been previously shown to be susceptible to jailbreaking, where adversarial prompts induce harmful responses. Yet existing attacks largely remain unimodal, optimizing either text or audio in isolation. We explore gradient-based multimodal jailbreaks by introducing JAMA (Joint Audio-text Multimodal Attack), a joint multimodal optimization framework combining Greedy Coordinate Gradient (GCG) for text and Projected Gradient Descent (PGD) for audio, to simultaneously perturb both modalities. Evaluations across four state-of-the-art SLMs and four audio types demonstrate that JAMA surpasses unimodal jailbreak rate by 1.5x to 10x. We analyze the operational dynamics of this joint attack and show that a sequential approximation method makes it 4x to 6x faster. Our findings suggest that unimodal safety is insufficient for robust SLMs. The code and data are available at https://repos.lsv.uni-saarland.de/akrishnan/multimodal-jailbreak-slm
Not All Data Are Unlearned Equally
Apr 08, 2025



Machine unlearning is concerned with the task of removing knowledge learned from particular data points from a trained model. In the context of large language models (LLMs), unlearning has recently received increased attention, particularly for removing knowledge about named entities from models for privacy purposes. While various approaches have been proposed to address the unlearning problem, most existing approaches treat all data points to be unlearned equally, i.e., unlearning that Montreal is a city in Canada is treated exactly the same as unlearning the phone number of the first author of this paper. In this work, we show that this all data is equal assumption does not hold for LLM unlearning. We study how the success of unlearning depends on the frequency of the knowledge we want to unlearn in the pre-training data of a model and find that frequency strongly affects unlearning, i.e., more frequent knowledge is harder to unlearn. Additionally, we uncover a misalignment between probability and generation-based evaluations of unlearning and show that this problem worsens as models become larger. Overall, our experiments highlight the need for better evaluation practices and novel methods for LLM unlearning that take the training data of models into account.
Joint vs Sequential Speaker-Role Detection and Automatic Speech Recognition for Air-traffic Control
Jun 19, 2024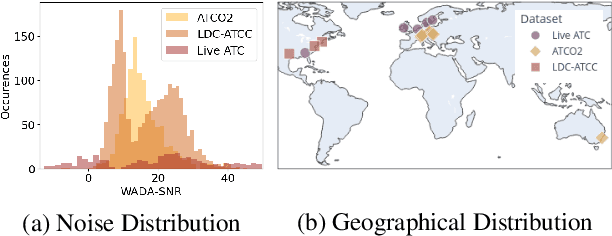
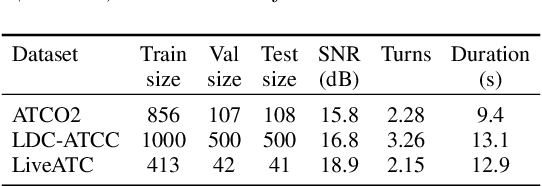
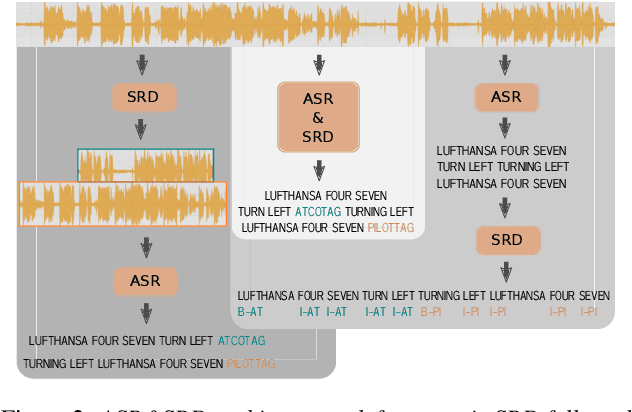

Utilizing air-traffic control (ATC) data for downstream natural-language processing tasks requires preprocessing steps. Key steps are the transcription of the data via automatic speech recognition (ASR) and speaker diarization, respectively speaker role detection (SRD) to divide the transcripts into pilot and air-traffic controller (ATCO) transcripts. While traditional approaches take on these tasks separately, we propose a transformer-based joint ASR-SRD system that solves both tasks jointly while relying on a standard ASR architecture. We compare this joint system against two cascaded approaches for ASR and SRD on multiple ATC datasets. Our study shows in which cases our joint system can outperform the two traditional approaches and in which cases the other architectures are preferable. We additionally evaluate how acoustic and lexical differences influence all architectures and show how to overcome them for our joint architecture.
On the Encoding of Gender in Transformer-based ASR Representations
Jun 14, 2024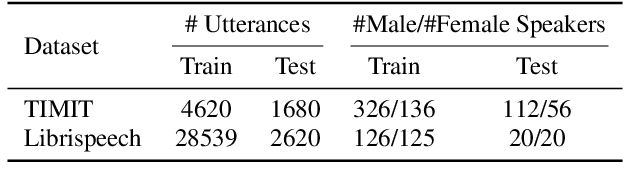
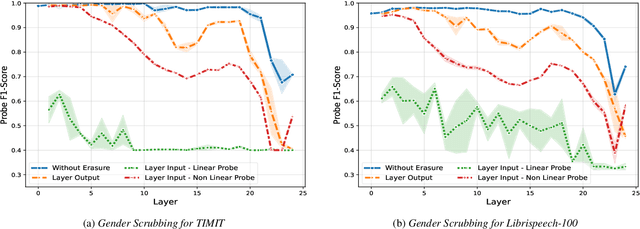

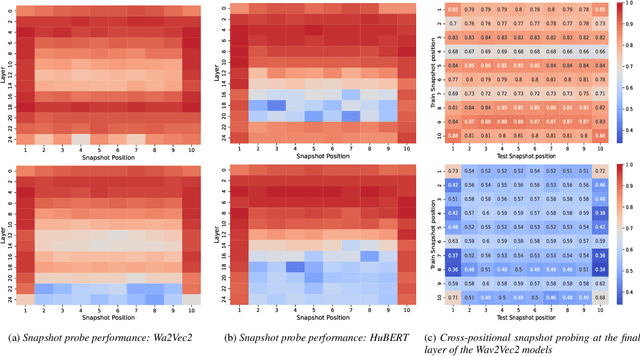
While existing literature relies on performance differences to uncover gender biases in ASR models, a deeper analysis is essential to understand how gender is encoded and utilized during transcript generation. This work investigates the encoding and utilization of gender in the latent representations of two transformer-based ASR models, Wav2Vec2 and HuBERT. Using linear erasure, we demonstrate the feasibility of removing gender information from each layer of an ASR model and show that such an intervention has minimal impacts on the ASR performance. Additionally, our analysis reveals a concentration of gender information within the first and last frames in the final layers, explaining the ease of erasing gender in these layers. Our findings suggest the prospect of creating gender-neutral embeddings that can be integrated into ASR frameworks without compromising their efficacy.
On the N-gram Approximation of Pre-trained Language Models
Jun 12, 2023



Large pre-trained language models (PLMs) have shown remarkable performance across various natural language understanding (NLU) tasks, particularly in low-resource settings. Nevertheless, their potential in Automatic Speech Recognition (ASR) remains largely unexplored. This study investigates the potential usage of PLMs for language modelling in ASR. We compare the application of large-scale text sampling and probability conversion for approximating GPT-2 into an n-gram model. Furthermore, we introduce a vocabulary-restricted decoding method for random sampling, and evaluate the effects of domain difficulty and data size on the usability of generated text. Our findings across eight domain-specific corpora support the use of sampling-based approximation and show that interpolating with a large sampled corpus improves test perplexity over a baseline trigram by 15%. Our vocabulary-restricted decoding method pushes this improvement further by 5% in domain-specific settings.
Exploring shared memory architectures for end-to-end gigapixel deep learning
Apr 24, 2023

Deep learning has made great strides in medical imaging, enabled by hardware advances in GPUs. One major constraint for the development of new models has been the saturation of GPU memory resources during training. This is especially true in computational pathology, where images regularly contain more than 1 billion pixels. These pathological images are traditionally divided into small patches to enable deep learning due to hardware limitations. In this work, we explore whether the shared GPU/CPU memory architecture on the M1 Ultra systems-on-a-chip (SoCs) recently released by Apple, Inc. may provide a solution. These affordable systems (less than \$5000) provide access to 128 GB of unified memory (Mac Studio with M1 Ultra SoC). As a proof of concept for gigapixel deep learning, we identified tissue from background on gigapixel areas from whole slide images (WSIs). The model was a modified U-Net (4492 parameters) leveraging large kernels and high stride. The M1 Ultra SoC was able to train the model directly on gigapixel images (16000$\times$64000 pixels, 1.024 billion pixels) with a batch size of 1 using over 100 GB of unified memory for the process at an average speed of 1 minute and 21 seconds per batch with Tensorflow 2/Keras. As expected, the model converged with a high Dice score of 0.989 $\pm$ 0.005. Training up until this point took 111 hours and 24 minutes over 4940 steps. Other high RAM GPUs like the NVIDIA A100 (largest commercially accessible at 80 GB, $\sim$\$15000) are not yet widely available (in preview for select regions on Amazon Web Services at \$40.96/hour as a group of 8). This study is a promising step towards WSI-wise end-to-end deep learning with prevalent network architectures.