 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Multimodal Data for Edge Case Robust Call-sign Recognition and Understanding
Dec 29, 2024



Operational machine-learning based assistant systems must be robust in a wide range of scenarios. This hold especially true for the air-traffic control (ATC) domain. The robustness of an architecture is particularly evident in edge cases, such as high word error rate (WER) transcripts resulting from noisy ATC recordings or partial transcripts due to clipped recordings. To increase the edge-case robustness of call-sign recognition and understanding (CRU), a core tasks in ATC speech processing, we propose the multimodal call-sign-command recovery model (CCR). The CCR architecture leads to an increase in the edge case performance of up to 15%. We demonstrate this on our second proposed architecture, CallSBERT. A CRU model that has less parameters, can be fine-tuned noticeably faster and is more robust during fine-tuning than the state of the art for CRU. Furthermore, we demonstrate that optimizing for edge cases leads to a significantly higher accuracy across a wide operational range.
Joint vs Sequential Speaker-Role Detection and Automatic Speech Recognition for Air-traffic Control
Jun 19, 2024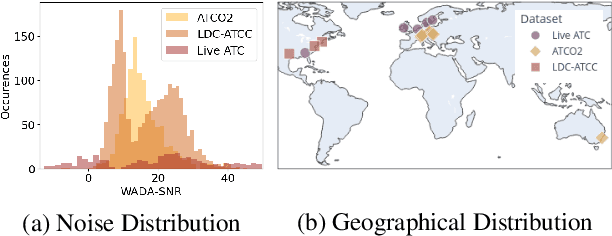
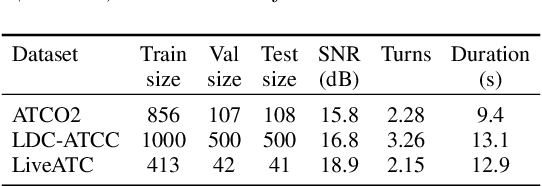
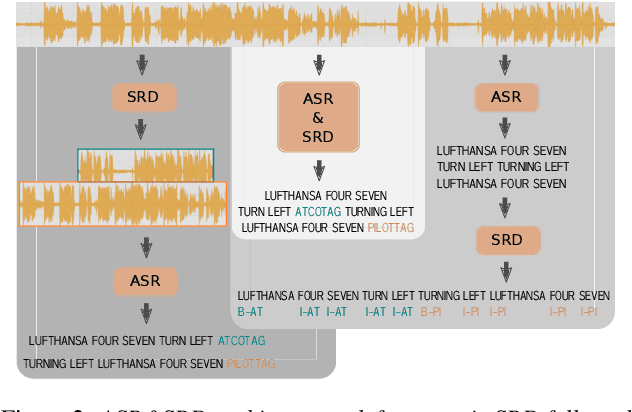

Utilizing air-traffic control (ATC) data for downstream natural-language processing tasks requires preprocessing steps. Key steps are the transcription of the data via automatic speech recognition (ASR) and speaker diarization, respectively speaker role detection (SRD) to divide the transcripts into pilot and air-traffic controller (ATCO) transcripts. While traditional approaches take on these tasks separately, we propose a transformer-based joint ASR-SRD system that solves both tasks jointly while relying on a standard ASR architecture. We compare this joint system against two cascaded approaches for ASR and SRD on multiple ATC datasets. Our study shows in which cases our joint system can outperform the two traditional approaches and in which cases the other architectures are preferable. We additionally evaluate how acoustic and lexical differences influence all architectures and show how to overcome them for our joint architecture.
Call-sign recognition and understanding for noisy air-traffic transcripts using surveillance information
Apr 13, 2022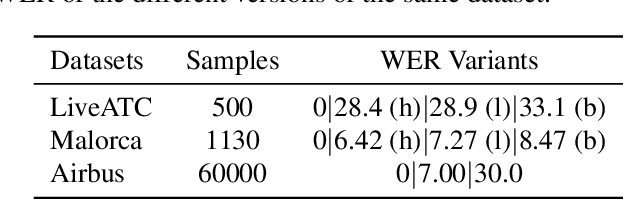

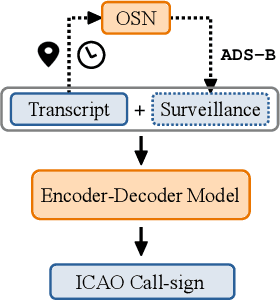
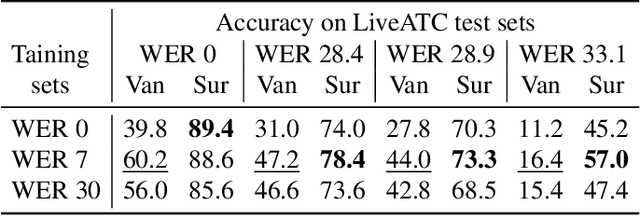
Air traffic control (ATC) relies on communication via speech between pilot and air-traffic controller (ATCO). The call-sign, as unique identifier for each flight, is used to address a specific pilot by the ATCO. Extracting the call-sign from the communication is a challenge because of the noisy ATC voice channel and the additional noise introduced by the receiver. A low signal-to-noise ratio (SNR) in the speech leads to high word error rate (WER) transcripts. We propose a new call-sign recognition and understanding (CRU) system that addresses this issue. The recognizer is trained to identify call-signs in noisy ATC transcripts and convert them into the standard International Civil Aviation Organization (ICAO) format. By incorporating surveillance information, we can multiply the call-sign accuracy (CSA) up to a factor of four. The introduced data augmentation adds additional performance on high WER transcripts and allows the adaptation of the model to unseen airspaces.