 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNucleus subtype classification using inter-modality learning
Jan 29, 2024Understanding the way cells communicate, co-locate, and interrelate is essential to understanding human physiology. Hematoxylin and eosin (H&E) staining is ubiquitously available both for clinical studies and research. The Colon Nucleus Identification and Classification (CoNIC) Challenge has recently innovated on robust artificial intelligence labeling of six cell types on H&E stains of the colon. However, this is a very small fraction of the number of potential cell classification types. Specifically, the CoNIC Challenge is unable to classify epithelial subtypes (progenitor, endocrine, goblet), lymphocyte subtypes (B, helper T, cytotoxic T), or connective subtypes (fibroblasts, stromal). In this paper, we propose to use inter-modality learning to label previously un-labelable cell types on virtual H&E. We leveraged multiplexed immunofluorescence (MxIF) histology imaging to identify 14 subclasses of cell types. We performed style transfer to synthesize virtual H&E from MxIF and transferred the higher density labels from MxIF to these virtual H&E images. We then evaluated the efficacy of learning in this approach. We identified helper T and progenitor nuclei with positive predictive values of $0.34 \pm 0.15$ (prevalence $0.03 \pm 0.01$) and $0.47 \pm 0.1$ (prevalence $0.07 \pm 0.02$) respectively on virtual H&E. This approach represents a promising step towards automating annotation in digital pathology.
Cell Spatial Analysis in Crohn's Disease: Unveiling Local Cell Arrangement Pattern with Graph-based Signatures
Aug 20, 2023Crohn's disease (CD) is a chronic and relapsing inflammatory condition that affects segments of the gastrointestinal tract. CD activity is determined by histological findings, particularly the density of neutrophils observed on Hematoxylin and Eosin stains (H&E) imaging. However, understanding the broader morphometry and local cell arrangement beyond cell counting and tissue morphology remains challenging. To address this, we characterize six distinct cell types from H&E images and develop a novel approach for the local spatial signature of each cell. Specifically, we create a 10-cell neighborhood matrix, representing neighboring cell arrangements for each individual cell. Utilizing t-SNE for non-linear spatial projection in scatter-plot and Kernel Density Estimation contour-plot formats, our study examines patterns of differences in the cellular environment associated with the odds ratio of spatial patterns between active CD and control groups. This analysis is based on data collected at the two research institutes. The findings reveal heterogeneous nearest-neighbor patterns, signifying distinct tendencies of cell clustering, with a particular focus on the rectum region. These variations underscore the impact of data heterogeneity on cell spatial arrangements in CD patients. Moreover, the spatial distribution disparities between the two research sites highlight the significance of collaborative efforts among healthcare organizations. All research analysis pipeline tools are available at https://github.com/MASILab/cellNN.
Feasibility of Universal Anomaly Detection without Knowing the Abnormality in Medical Images
Jul 03, 2023



Many anomaly detection approaches, especially deep learning methods, have been recently developed to identify abnormal image morphology by only employing normal images during training. Unfortunately, many prior anomaly detection methods were optimized for a specific "known" abnormality (e.g., brain tumor, bone fraction, cell types). Moreover, even though only the normal images were used in the training process, the abnormal images were oftenly employed during the validation process (e.g., epoch selection, hyper-parameter tuning), which might leak the supposed ``unknown" abnormality unintentionally. In this study, we investigated these two essential aspects regarding universal anomaly detection in medical images by (1) comparing various anomaly detection methods across four medical datasets, (2) investigating the inevitable but often neglected issues on how to unbiasedly select the optimal anomaly detection model during the validation phase using only normal images, and (3) proposing a simple decision-level ensemble method to leverage the advantage of different kinds of anomaly detection without knowing the abnormality. The results of our experiments indicate that none of the evaluated methods consistently achieved the best performance across all datasets. Our proposed method enhanced the robustness of performance in general (average AUC 0.956).
Exploring shared memory architectures for end-to-end gigapixel deep learning
Apr 24, 2023

Deep learning has made great strides in medical imaging, enabled by hardware advances in GPUs. One major constraint for the development of new models has been the saturation of GPU memory resources during training. This is especially true in computational pathology, where images regularly contain more than 1 billion pixels. These pathological images are traditionally divided into small patches to enable deep learning due to hardware limitations. In this work, we explore whether the shared GPU/CPU memory architecture on the M1 Ultra systems-on-a-chip (SoCs) recently released by Apple, Inc. may provide a solution. These affordable systems (less than \$5000) provide access to 128 GB of unified memory (Mac Studio with M1 Ultra SoC). As a proof of concept for gigapixel deep learning, we identified tissue from background on gigapixel areas from whole slide images (WSIs). The model was a modified U-Net (4492 parameters) leveraging large kernels and high stride. The M1 Ultra SoC was able to train the model directly on gigapixel images (16000$\times$64000 pixels, 1.024 billion pixels) with a batch size of 1 using over 100 GB of unified memory for the process at an average speed of 1 minute and 21 seconds per batch with Tensorflow 2/Keras. As expected, the model converged with a high Dice score of 0.989 $\pm$ 0.005. Training up until this point took 111 hours and 24 minutes over 4940 steps. Other high RAM GPUs like the NVIDIA A100 (largest commercially accessible at 80 GB, $\sim$\$15000) are not yet widely available (in preview for select regions on Amazon Web Services at \$40.96/hour as a group of 8). This study is a promising step towards WSI-wise end-to-end deep learning with prevalent network architectures.
Segment Anything Model (SAM) for Digital Pathology: Assess Zero-shot Segmentation on Whole Slide Imaging
Apr 09, 2023The segment anything model (SAM) was released as a foundation model for image segmentation. The promptable segmentation model was trained by over 1 billion masks on 11M licensed and privacy-respecting images. The model supports zero-shot image segmentation with various segmentation prompts (e.g., points, boxes, masks). It makes the SAM attractive for medical image analysis, especially for digital pathology where the training data are rare. In this study, we evaluate the zero-shot segmentation performance of SAM model on representative segmentation tasks on whole slide imaging (WSI), including (1) tumor segmentation, (2) non-tumor tissue segmentation, (3) cell nuclei segmentation. Core Results: The results suggest that the zero-shot SAM model achieves remarkable segmentation performance for large connected objects. However, it does not consistently achieve satisfying performance for dense instance object segmentation, even with 20 prompts (clicks/boxes) on each image. We also summarized the identified limitations for digital pathology: (1) image resolution, (2) multiple scales, (3) prompt selection, and (4) model fine-tuning. In the future, the few-shot fine-tuning with images from downstream pathological segmentation tasks might help the model to achieve better performance in dense object segmentation.
Cross-scale Multi-instance Learning for Pathological Image Diagnosis
Apr 01, 2023



Analyzing high resolution whole slide images (WSIs) with regard to information across multiple scales poses a significant challenge in digital pathology. Multi-instance learning (MIL) is a common solution for working with high resolution images by classifying bags of objects (i.e. sets of smaller image patches). However, such processing is typically performed at a single scale (e.g., 20x magnification) of WSIs, disregarding the vital inter-scale information that is key to diagnoses by human pathologists. In this study, we propose a novel cross-scale MIL algorithm to explicitly aggregate inter-scale relationships into a single MIL network for pathological image diagnosis. The contribution of this paper is three-fold: (1) A novel cross-scale MIL (CS-MIL) algorithm that integrates the multi-scale information and the inter-scale relationships is proposed; (2) A toy dataset with scale-specific morphological features is created and released to examine and visualize differential cross-scale attention; (3) Superior performance on both in-house and public datasets is demonstrated by our simple cross-scale MIL strategy. The official implementation is publicly available at https://github.com/hrlblab/CS-MIL.
Cross-scale Attention Guided Multi-instance Learning for Crohn's Disease Diagnosis with Pathological Images
Aug 15, 2022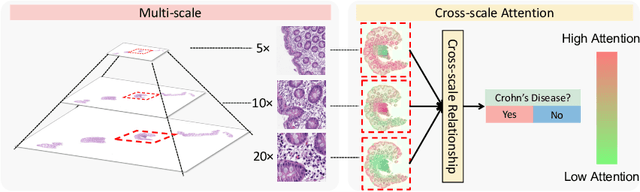
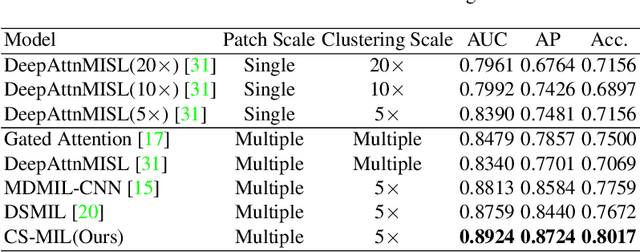
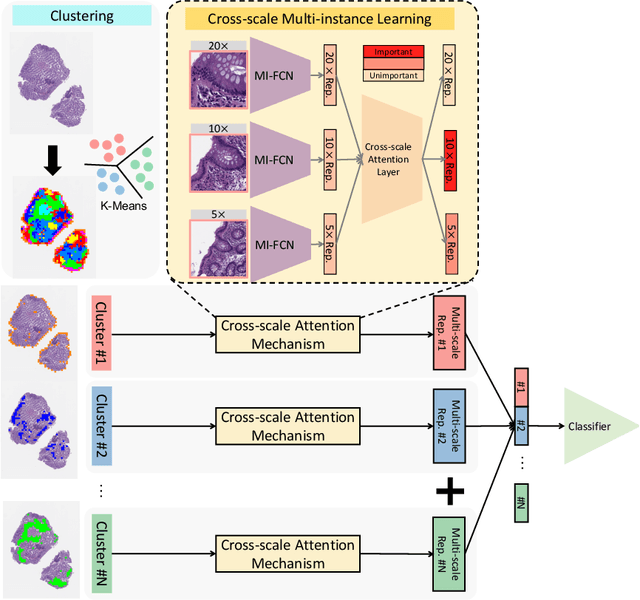
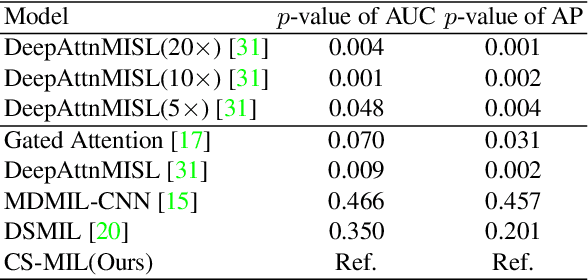
Multi-instance learning (MIL) is widely used in the computer-aided interpretation of pathological Whole Slide Images (WSIs) to solve the lack of pixel-wise or patch-wise annotations. Often, this approach directly applies "natural image driven" MIL algorithms which overlook the multi-scale (i.e. pyramidal) nature of WSIs. Off-the-shelf MIL algorithms are typically deployed on a single-scale of WSIs (e.g., 20x magnification), while human pathologists usually aggregate the global and local patterns in a multi-scale manner (e.g., by zooming in and out between different magnifications). In this study, we propose a novel cross-scale attention mechanism to explicitly aggregate inter-scale interactions into a single MIL network for Crohn's Disease (CD), which is a form of inflammatory bowel disease. The contribution of this paper is two-fold: (1) a cross-scale attention mechanism is proposed to aggregate features from different resolutions with multi-scale interaction; and (2) differential multi-scale attention visualizations are generated to localize explainable lesion patterns. By training ~250,000 H&E-stained Ascending Colon (AC) patches from 20 CD patient and 30 healthy control samples at different scales, our approach achieved a superior Area under the Curve (AUC) score of 0.8924 compared with baseline models. The official implementation is publicly available at https://github.com/hrlblab/CS-MIL.
Deep Multi-modal Fusion of Image and Non-image Data in Disease Diagnosis and Prognosis: A Review
Mar 30, 2022
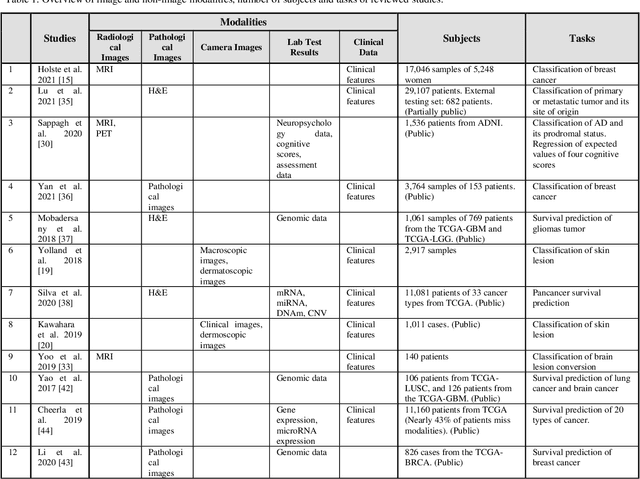


The rapid development of diagnostic technologies in healthcare is leading to higher requirements for physicians to handle and integrate the heterogeneous, yet complementary data that are produced during routine practice. For instance, the personalized diagnosis and treatment planning for a single cancer patient relies on the various images (e.g., radiological, pathological, and camera images) and non-image data (e.g., clinical data and genomic data). However, such decision-making procedures can be subjective, qualitative, and have large inter-subject variabilities. With the recent advances in multi-modal deep learning technologies, an increasingly large number of efforts have been devoted to a key question: how do we extract and aggregate multi-modal information to ultimately provide more objective, quantitative computer-aided clinical decision making? This paper reviews the recent studies on dealing with such a question. Briefly, this review will include the (1) overview of current multi-modal learning workflows, (2) summarization of multi-modal fusion methods, (3) discussion of the performance, (4) applications in disease diagnosis and prognosis, and (5) challenges and future directions.
Random Multi-Channel Image Synthesis for Multiplexed Immunofluorescence Imaging
Sep 18, 2021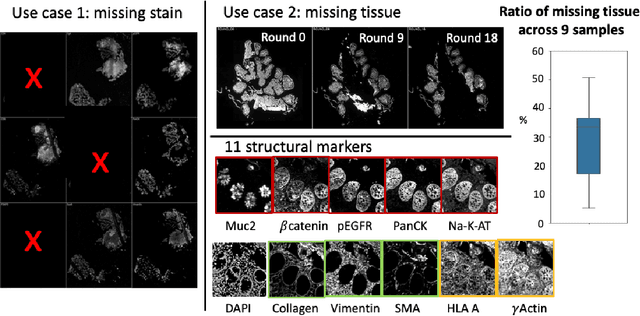
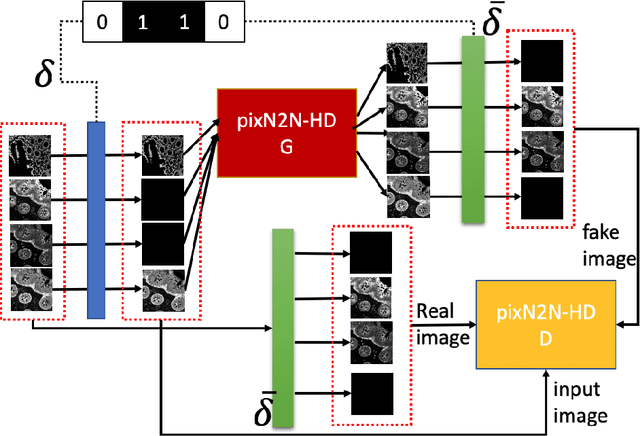
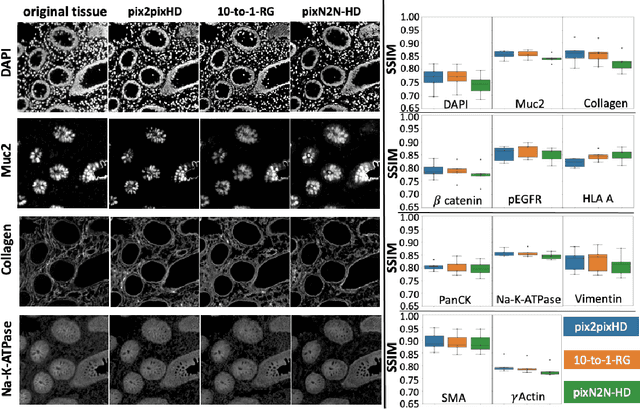
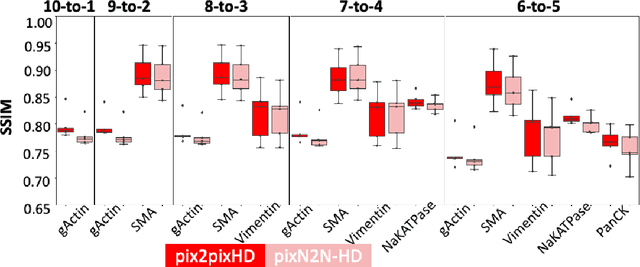
Multiplex immunofluorescence (MxIF) is an emerging imaging technique that produces the high sensitivity and specificity of single-cell mapping. With a tenet of 'seeing is believing', MxIF enables iterative staining and imaging extensive antibodies, which provides comprehensive biomarkers to segment and group different cells on a single tissue section. However, considerable depletion of the scarce tissue is inevitable from extensive rounds of staining and bleaching ('missing tissue'). Moreover, the immunofluorescence (IF) imaging can globally fail for particular rounds ('missing stain''). In this work, we focus on the 'missing stain' issue. It would be appealing to develop digital image synthesis approaches to restore missing stain images without losing more tissue physically. Herein, we aim to develop image synthesis approaches for eleven MxIF structural molecular markers (i.e., epithelial and stromal) on real samples. We propose a novel multi-channel high-resolution image synthesis approach, called pixN2N-HD, to tackle possible missing stain scenarios via a high-resolution generative adversarial network (GAN). Our contribution is three-fold: (1) a single deep network framework is proposed to tackle missing stain in MxIF; (2) the proposed 'N-to-N' strategy reduces theoretical four years of computational time to 20 hours when covering all possible missing stains scenarios, with up to five missing stains (e.g., '(N-1)-to-1', '(N-2)-to-2'); and (3) this work is the first comprehensive experimental study of investigating cross-stain synthesis in MxIF. Our results elucidate a promising direction of advancing MxIF imaging with deep image synthesis.