 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-modal Fusion of Image and Non-image Data in Disease Diagnosis and Prognosis: A Review
Paper and Code
Mar 30, 2022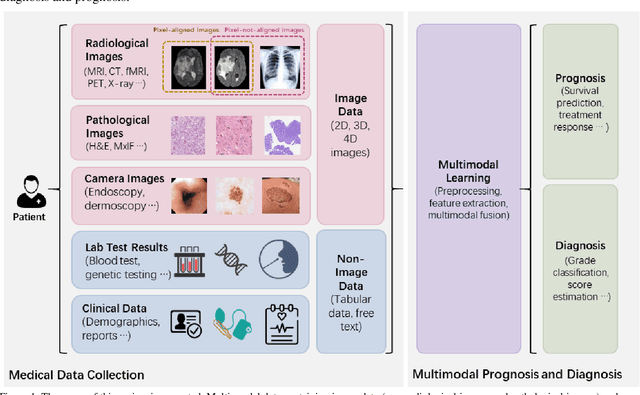
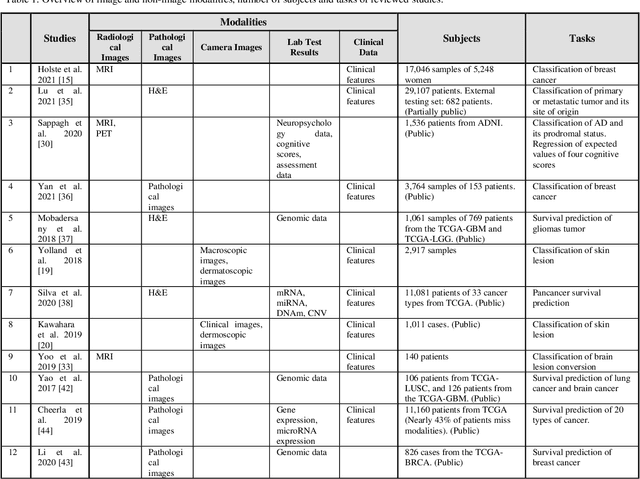


The rapid development of diagnostic technologies in healthcare is leading to higher requirements for physicians to handle and integrate the heterogeneous, yet complementary data that are produced during routine practice. For instance, the personalized diagnosis and treatment planning for a single cancer patient relies on the various images (e.g., radiological, pathological, and camera images) and non-image data (e.g., clinical data and genomic data). However, such decision-making procedures can be subjective, qualitative, and have large inter-subject variabilities. With the recent advances in multi-modal deep learning technologies, an increasingly large number of efforts have been devoted to a key question: how do we extract and aggregate multi-modal information to ultimately provide more objective, quantitative computer-aided clinical decision making? This paper reviews the recent studies on dealing with such a question. Briefly, this review will include the (1) overview of current multi-modal learning workflows, (2) summarization of multi-modal fusion methods, (3) discussion of the performance, (4) applications in disease diagnosis and prognosis, and (5) challenges and future directions.