 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEthio-ASR: Joint Multilingual Speech Recognition and Language Identification for Ethiopian Languages
Mar 24, 2026We present Ethio-ASR, a suite of multilingual CTC-based automatic speech recognition (ASR) models jointly trained on five Ethiopian languages: Amharic, Tigrinya, Oromo, Sidaama, and Wolaytta. These languages belong to the Semitic, Cushitic, and Omotic branches of the Afroasiatic family, and remain severely underrepresented in speech technology despite being spoken by the vast majority of Ethiopia's population. We train our models on the recently released WAXAL corpus using several pre-trained speech encoders and evaluate against strong multilingual baselines, including OmniASR. Our best model achieves an average WER of 30.48% on the WAXAL test set, outperforming the best OmniASR model with substantially fewer parameters. We further provide a comprehensive analysis of gender bias, the contribution of vowel length and consonant gemination to ASR errors, and the training dynamics of multilingual CTC models. Our models and codebase are publicly available to the research community.
Voice Conversion Improves Cross-Domain Robustness for Spoken Arabic Dialect Identification
May 30, 2025Arabic dialect identification (ADI) systems are essential for large-scale data collection pipelines that enable the development of inclusive speech technologies for Arabic language varieties. However, the reliability of current ADI systems is limited by poor generalization to out-of-domain speech. In this paper, we present an effective approach based on voice conversion for training ADI models that achieves state-of-the-art performance and significantly improves robustness in cross-domain scenarios. Evaluated on a newly collected real-world test set spanning four different domains, our approach yields consistent improvements of up to +34.1% in accuracy across domains. Furthermore, we present an analysis of our approach and demonstrate that voice conversion helps mitigate the speaker bias in the ADI dataset. We release our robust ADI model and cross-domain evaluation dataset to support the development of inclusive speech technologies for Arabic.
Attention on Multiword Expressions: A Multilingual Study of BERT-based Models with Regard to Idiomaticity and Microsyntax
May 09, 2025This study analyzes the attention patterns of fine-tuned encoder-only models based on the BERT architecture (BERT-based models) towards two distinct types of Multiword Expressions (MWEs): idioms and microsyntactic units (MSUs). Idioms present challenges in semantic non-compositionality, whereas MSUs demonstrate unconventional syntactic behavior that does not conform to standard grammatical categorizations. We aim to understand whether fine-tuning BERT-based models on specific tasks influences their attention to MWEs, and how this attention differs between semantic and syntactic tasks. We examine attention scores to MWEs in both pre-trained and fine-tuned BERT-based models. We utilize monolingual models and datasets in six Indo-European languages - English, German, Dutch, Polish, Russian, and Ukrainian. Our results show that fine-tuning significantly influences how models allocate attention to MWEs. Specifically, models fine-tuned on semantic tasks tend to distribute attention to idiomatic expressions more evenly across layers. Models fine-tuned on syntactic tasks show an increase in attention to MSUs in the lower layers, corresponding with syntactic processing requirements.
* 10 pages, 3 figures. Findings 2025
On the Encoding of Gender in Transformer-based ASR Representations
Jun 14, 2024
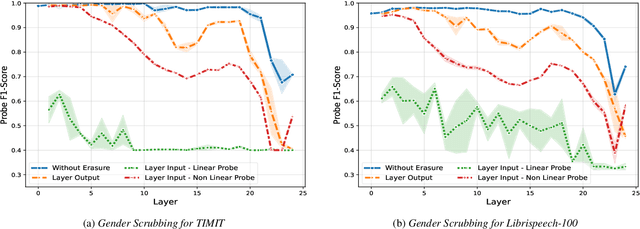

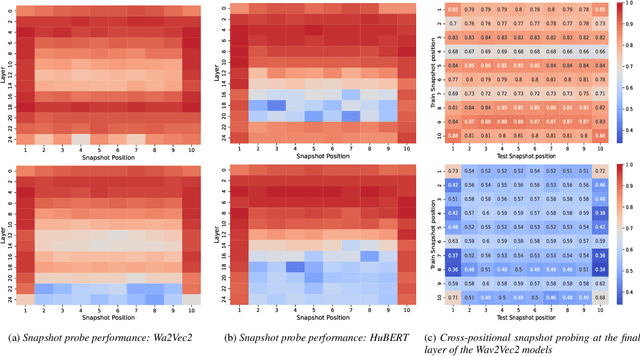
While existing literature relies on performance differences to uncover gender biases in ASR models, a deeper analysis is essential to understand how gender is encoded and utilized during transcript generation. This work investigates the encoding and utilization of gender in the latent representations of two transformer-based ASR models, Wav2Vec2 and HuBERT. Using linear erasure, we demonstrate the feasibility of removing gender information from each layer of an ASR model and show that such an intervention has minimal impacts on the ASR performance. Additionally, our analysis reveals a concentration of gender information within the first and last frames in the final layers, explaining the ease of erasing gender in these layers. Our findings suggest the prospect of creating gender-neutral embeddings that can be integrated into ASR frameworks without compromising their efficacy.
Self-supervised Adaptive Pre-training of Multilingual Speech Models for Language and Dialect Identification
Dec 12, 2023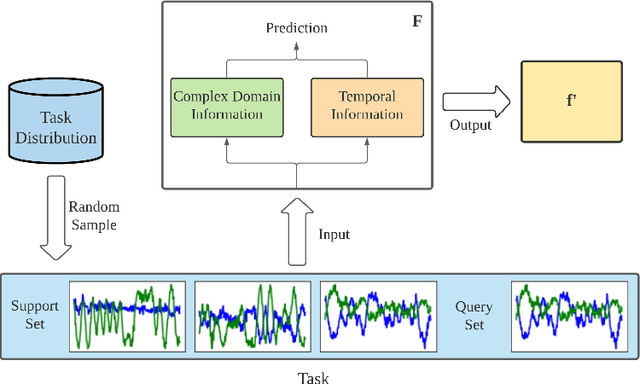

Pre-trained Transformer-based speech models have shown striking performance when fine-tuned on various downstream tasks such as automatic speech recognition and spoken language identification (SLID). However, the problem of domain mismatch remains a challenge in this area, where the domain of the pre-training data might differ from that of the downstream labeled data used for fine-tuning. In multilingual tasks such as SLID, the pre-trained speech model may not support all the languages in the downstream task. To address this challenge, we propose self-supervised adaptive pre-training (SAPT) to adapt the pre-trained model to the target domain and languages of the downstream task. We apply SAPT to the XLSR-128 model and investigate the effectiveness of this approach for the SLID task. First, we demonstrate that SAPT improves XLSR performance on the FLEURS benchmark with substantial gains up to 40.1% for under-represented languages. Second, we apply SAPT on four different datasets in a few-shot learning setting, showing that our approach improves the sample efficiency of XLSR during fine-tuning. Our experiments provide strong empirical evidence that continual adaptation via self-supervision improves downstream performance for multilingual speech models.
An Information-Theoretic Analysis of Self-supervised Discrete Representations of Speech
Jun 04, 2023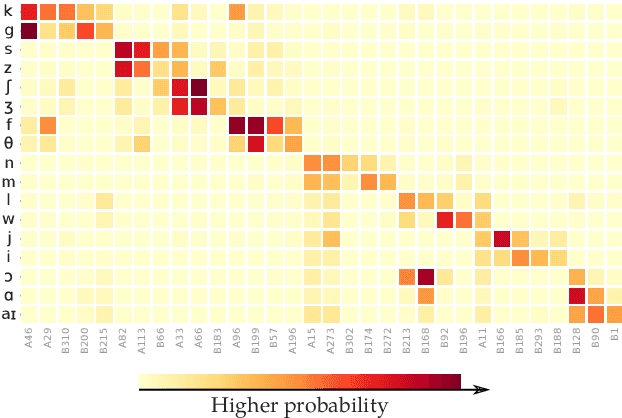
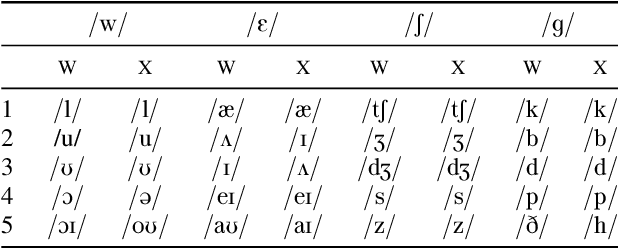
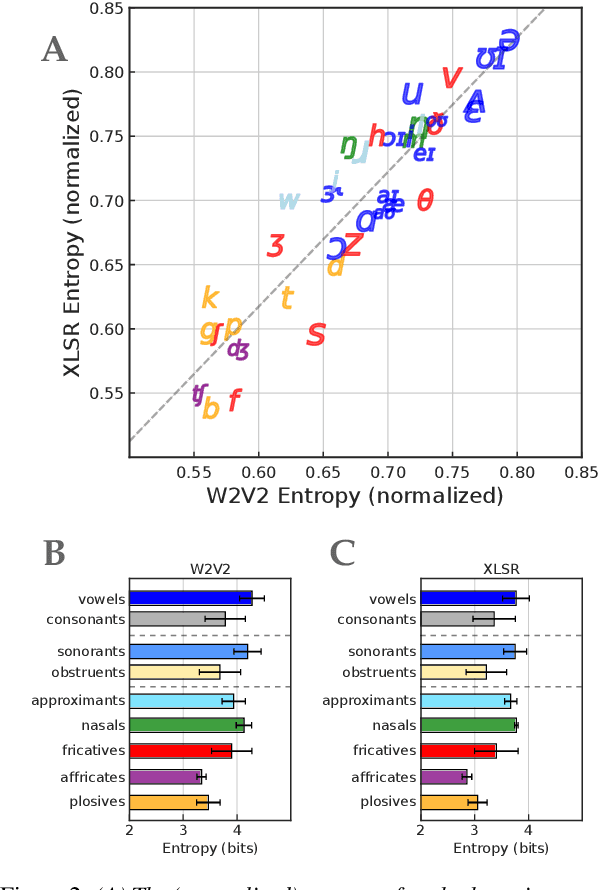
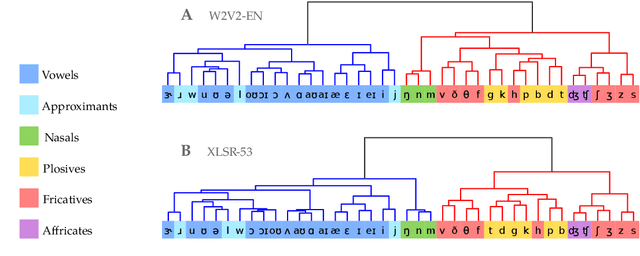
Self-supervised representation learning for speech often involves a quantization step that transforms the acoustic input into discrete units. However, it remains unclear how to characterize the relationship between these discrete units and abstract phonetic categories such as phonemes. In this paper, we develop an information-theoretic framework whereby we represent each phonetic category as a distribution over discrete units. We then apply our framework to two different self-supervised models (namely wav2vec 2.0 and XLSR) and use American English speech as a case study. Our study demonstrates that the entropy of phonetic distributions reflects the variability of the underlying speech sounds, with phonetically similar sounds exhibiting similar distributions. While our study confirms the lack of direct, one-to-one correspondence, we find an intriguing, indirect relationship between phonetic categories and discrete units.
Developing the Reliable Shallow Supervised Learning for Thermal Comfort using ASHRAE RP-884 and ASHRAE Global Thermal Comfort Database II
Mar 03, 2023
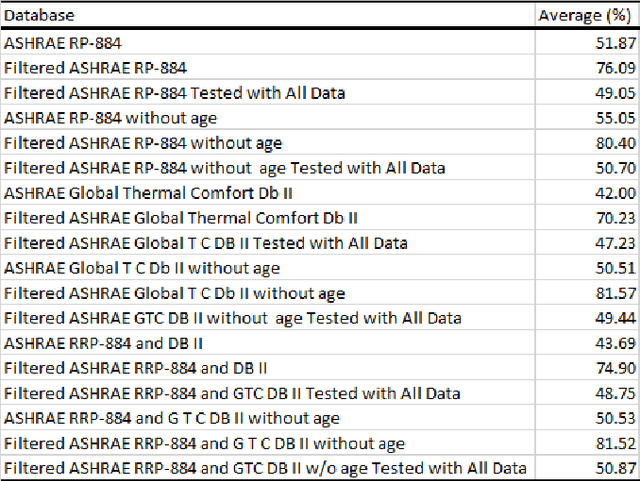
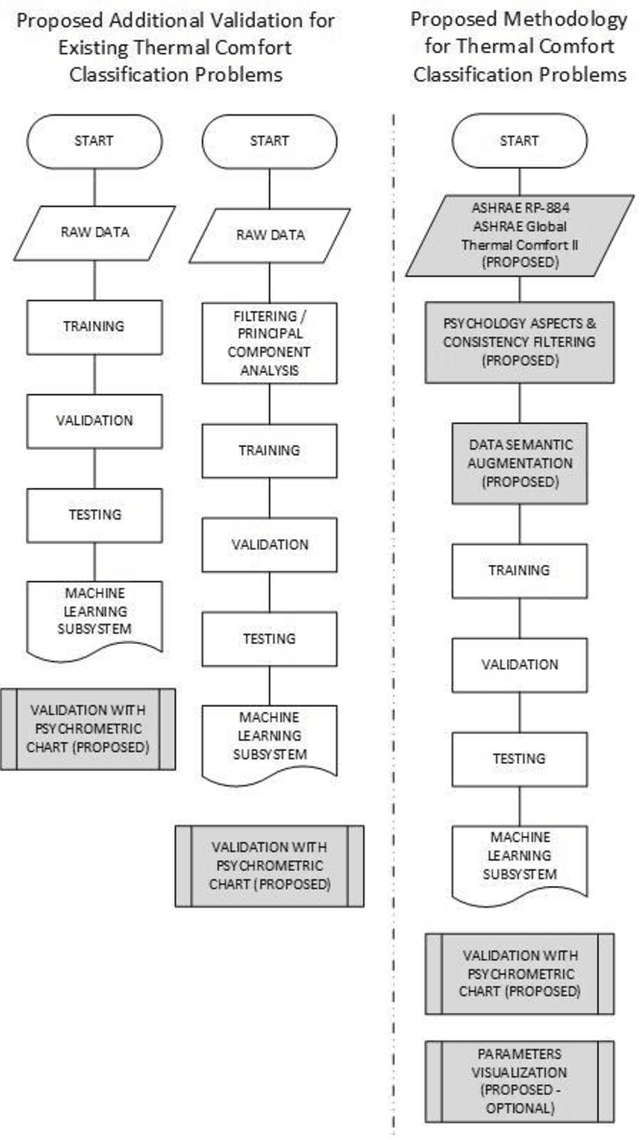
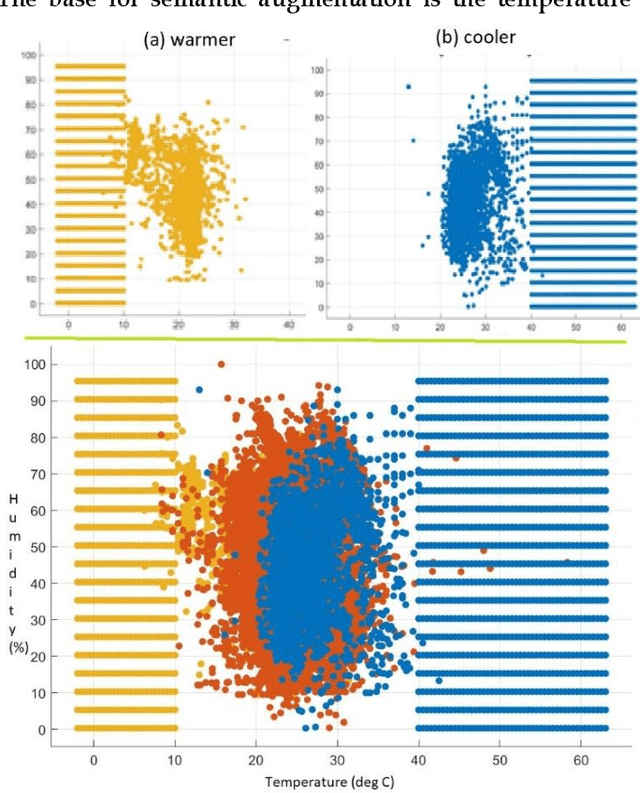
The artificial intelligence (AI) system designer for thermal comfort faces insufficient data recorded from the current user or overfitting due to unreliable training data. This work introduces the reliable data set for training the AI subsystem for thermal comfort. This paper presents the control algorithm based on shallow supervised learning, which is simple enough to be implemented in the Internet of Things (IoT) system for residential usage using ASHRAE RP-884 and ASHRAE Global Thermal Comfort Database II. No training data for thermal comfort is available as reliable as this dataset, but the direct use of this data can lead to overfitting. This work offers the algorithm for data filtering and semantic data augmentation for the ASHRAE database for the supervised learning process. Overfitting always becomes a problem due to the psychological aspect involved in the thermal comfort decision. The method to check the AI system based on the psychrometric chart against overfitting is presented. This paper also assesses the most important parameters needed to achieve human thermal comfort. This method can support the development of reinforced learning for thermal comfort.
Analyzing the Representational Geometry of Acoustic Word Embeddings
Jan 08, 2023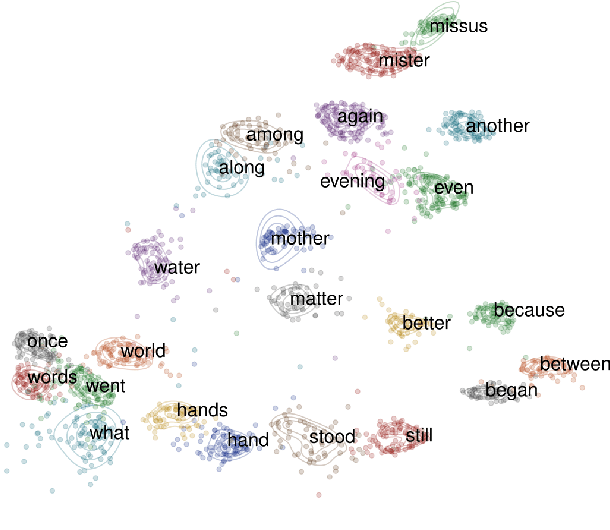



Acoustic word embeddings (AWEs) are vector representations such that different acoustic exemplars of the same word are projected nearby in the embedding space. In addition to their use in speech technology applications such as spoken term discovery and keyword spotting, AWE models have been adopted as models of spoken-word processing in several cognitively motivated studies and have been shown to exhibit human-like performance in some auditory processing tasks. Nevertheless, the representational geometry of AWEs remains an under-explored topic that has not been studied in the literature. In this paper, we take a closer analytical look at AWEs learned from English speech and study how the choice of the learning objective and the architecture shapes their representational profile. To this end, we employ a set of analytic techniques from machine learning and neuroscience in three different analyses: embedding space uniformity, word discriminability, and representational consistency. Our main findings highlight the prominent role of the learning objective on shaping the representation profile compared to the model architecture.
Integrating Form and Meaning: A Multi-Task Learning Model for Acoustic Word Embeddings
Sep 18, 2022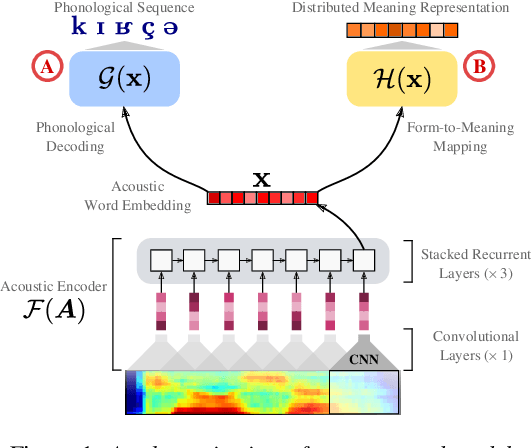

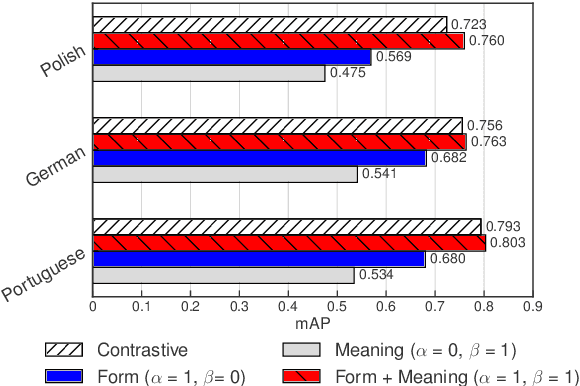
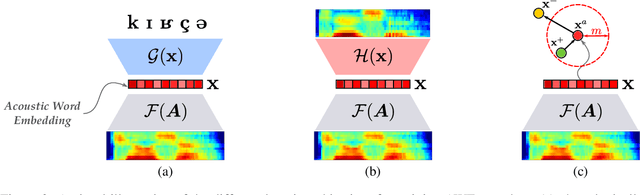
Models of acoustic word embeddings (AWEs) learn to map variable-length spoken word segments onto fixed-dimensionality vector representations such that different acoustic exemplars of the same word are projected nearby in the embedding space. In addition to their speech technology applications, AWE models have been shown to predict human performance on a variety of auditory lexical processing tasks. Current AWE models are based on neural networks and trained in a bottom-up approach that integrates acoustic cues to build up a word representation given an acoustic or symbolic supervision signal. Therefore, these models do not leverage or capture high-level lexical knowledge during the learning process. In this paper, we propose a multi-task learning model that incorporates top-down lexical knowledge into the training procedure of AWEs. Our model learns a mapping between the acoustic input and a lexical representation that encodes high-level information such as word semantics in addition to bottom-up form-based supervision. We experiment with three languages and demonstrate that incorporating lexical knowledge improves the embedding space discriminability and encourages the model to better separate lexical categories.
How Familiar Does That Sound? Cross-Lingual Representational Similarity Analysis of Acoustic Word Embeddings
Sep 21, 2021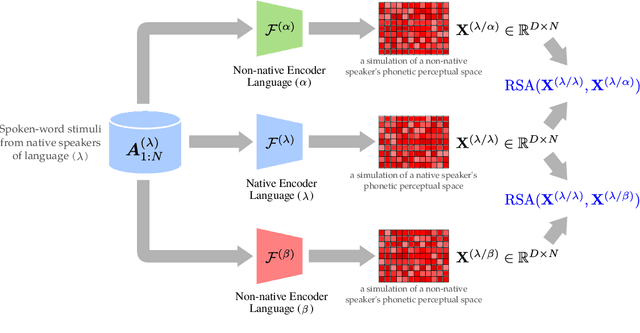
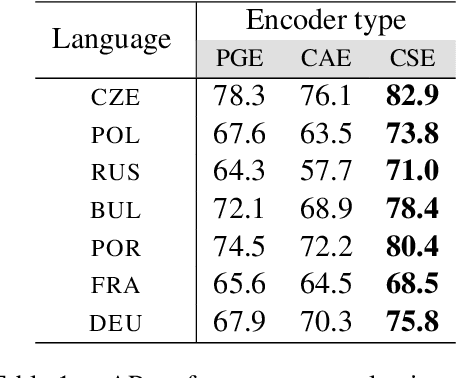
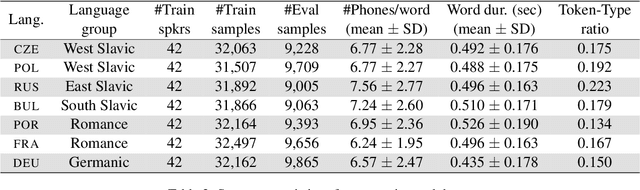
How do neural networks "perceive" speech sounds from unknown languages? Does the typological similarity between the model's training language (L1) and an unknown language (L2) have an impact on the model representations of L2 speech signals? To answer these questions, we present a novel experimental design based on representational similarity analysis (RSA) to analyze acoustic word embeddings (AWEs) -- vector representations of variable-duration spoken-word segments. First, we train monolingual AWE models on seven Indo-European languages with various degrees of typological similarity. We then employ RSA to quantify the cross-lingual similarity by simulating native and non-native spoken-word processing using AWEs. Our experiments show that typological similarity indeed affects the representational similarity of the models in our study. We further discuss the implications of our work on modeling speech processing and language similarity with neural networks.