 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing the Representational Geometry of Acoustic Word Embeddings
Paper and Code
Jan 08, 2023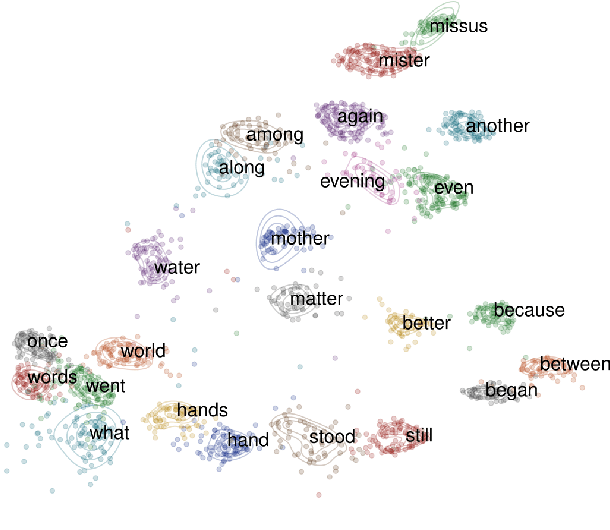



Acoustic word embeddings (AWEs) are vector representations such that different acoustic exemplars of the same word are projected nearby in the embedding space. In addition to their use in speech technology applications such as spoken term discovery and keyword spotting, AWE models have been adopted as models of spoken-word processing in several cognitively motivated studies and have been shown to exhibit human-like performance in some auditory processing tasks. Nevertheless, the representational geometry of AWEs remains an under-explored topic that has not been studied in the literature. In this paper, we take a closer analytical look at AWEs learned from English speech and study how the choice of the learning objective and the architecture shapes their representational profile. To this end, we employ a set of analytic techniques from machine learning and neuroscience in three different analyses: embedding space uniformity, word discriminability, and representational consistency. Our main findings highlight the prominent role of the learning objective on shaping the representation profile compared to the model architecture.