 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Familiar Does That Sound? Cross-Lingual Representational Similarity Analysis of Acoustic Word Embeddings
Paper and Code
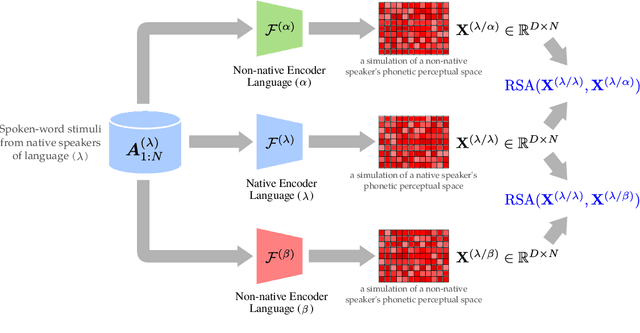
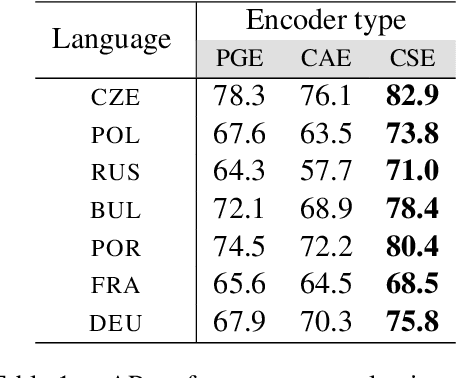
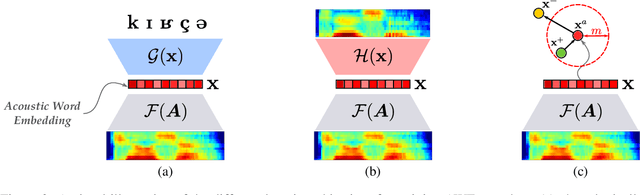
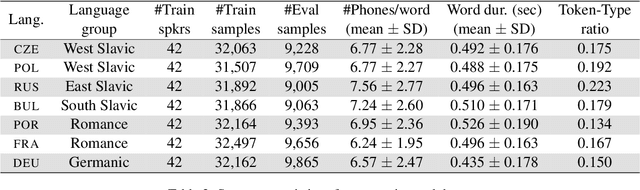
How do neural networks "perceive" speech sounds from unknown languages? Does the typological similarity between the model's training language (L1) and an unknown language (L2) have an impact on the model representations of L2 speech signals? To answer these questions, we present a novel experimental design based on representational similarity analysis (RSA) to analyze acoustic word embeddings (AWEs) -- vector representations of variable-duration spoken-word segments. First, we train monolingual AWE models on seven Indo-European languages with various degrees of typological similarity. We then employ RSA to quantify the cross-lingual similarity by simulating native and non-native spoken-word processing using AWEs. Our experiments show that typological similarity indeed affects the representational similarity of the models in our study. We further discuss the implications of our work on modeling speech processing and language similarity with neural networks.