 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention on Multiword Expressions: A Multilingual Study of BERT-based Models with Regard to Idiomaticity and Microsyntax
May 09, 2025This study analyzes the attention patterns of fine-tuned encoder-only models based on the BERT architecture (BERT-based models) towards two distinct types of Multiword Expressions (MWEs): idioms and microsyntactic units (MSUs). Idioms present challenges in semantic non-compositionality, whereas MSUs demonstrate unconventional syntactic behavior that does not conform to standard grammatical categorizations. We aim to understand whether fine-tuning BERT-based models on specific tasks influences their attention to MWEs, and how this attention differs between semantic and syntactic tasks. We examine attention scores to MWEs in both pre-trained and fine-tuned BERT-based models. We utilize monolingual models and datasets in six Indo-European languages - English, German, Dutch, Polish, Russian, and Ukrainian. Our results show that fine-tuning significantly influences how models allocate attention to MWEs. Specifically, models fine-tuned on semantic tasks tend to distribute attention to idiomatic expressions more evenly across layers. Models fine-tuned on syntactic tasks show an increase in attention to MSUs in the lower layers, corresponding with syntactic processing requirements.
* 10 pages, 3 figures. Findings 2025
How Familiar Does That Sound? Cross-Lingual Representational Similarity Analysis of Acoustic Word Embeddings
Sep 21, 2021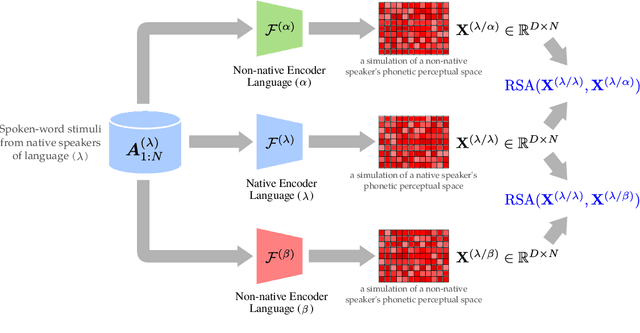
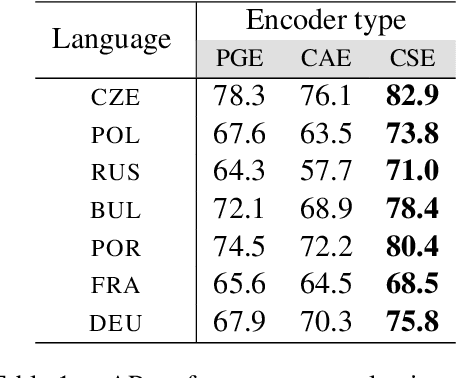
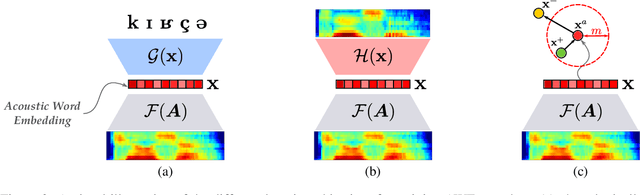
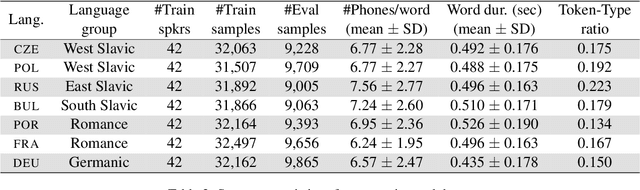
How do neural networks "perceive" speech sounds from unknown languages? Does the typological similarity between the model's training language (L1) and an unknown language (L2) have an impact on the model representations of L2 speech signals? To answer these questions, we present a novel experimental design based on representational similarity analysis (RSA) to analyze acoustic word embeddings (AWEs) -- vector representations of variable-duration spoken-word segments. First, we train monolingual AWE models on seven Indo-European languages with various degrees of typological similarity. We then employ RSA to quantify the cross-lingual similarity by simulating native and non-native spoken-word processing using AWEs. Our experiments show that typological similarity indeed affects the representational similarity of the models in our study. We further discuss the implications of our work on modeling speech processing and language similarity with neural networks.
Rediscovering the Slavic Continuum in Representations Emerging from Neural Models of Spoken Language Identification
Oct 22, 2020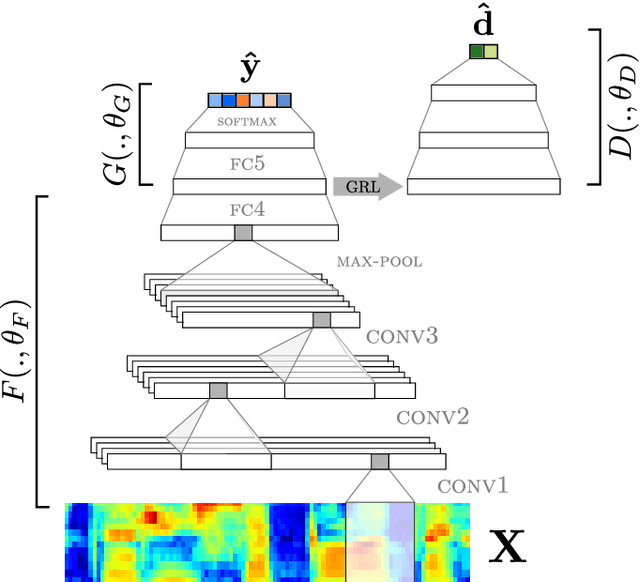

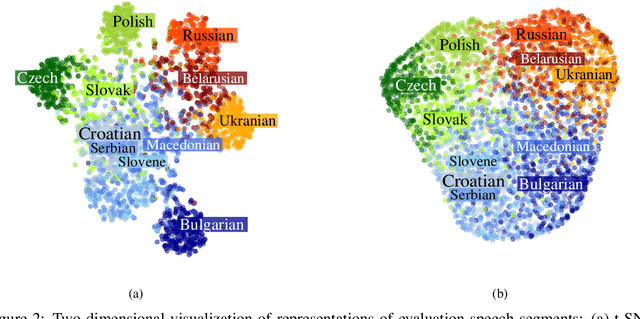
Deep neural networks have been employed for various spoken language recognition tasks, including tasks that are multilingual by definition such as spoken language identification. In this paper, we present a neural model for Slavic language identification in speech signals and analyze its emergent representations to investigate whether they reflect objective measures of language relatedness and/or non-linguists' perception of language similarity. While our analysis shows that the language representation space indeed captures language relatedness to a great extent, we find perceptual confusability between languages in our study to be the best predictor of the language representation similarity.
Cross-Domain Adaptation of Spoken Language Identification for Related Languages: The Curious Case of Slavic Languages
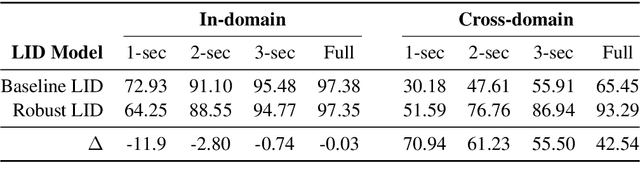
Aug 07, 2020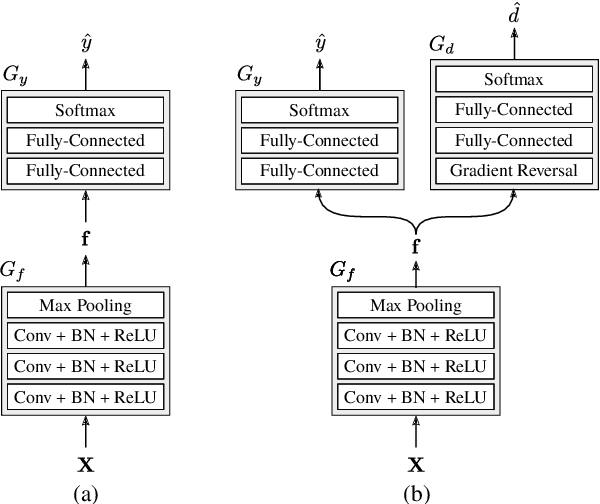
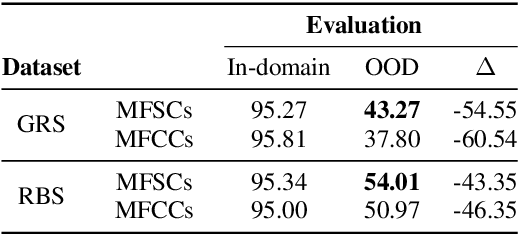
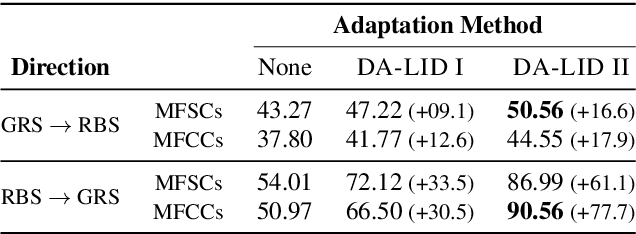
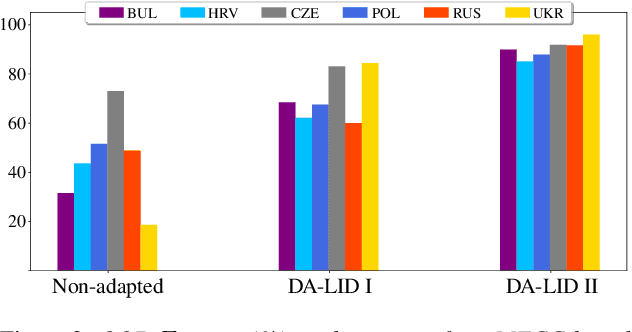
State-of-the-art spoken language identification (LID) systems, which are based on end-to-end deep neural networks, have shown remarkable success not only in discriminating between distant languages but also between closely-related languages or even different spoken varieties of the same language. However, it is still unclear to what extent neural LID models generalize to speech samples with different acoustic conditions due to domain shift. In this paper, we present a set of experiments to investigate the impact of domain mismatch on the performance of neural LID systems for a subset of six Slavic languages across two domains (read speech and radio broadcast) and examine two low-level signal descriptors (spectral and cepstral features) for this task. Our experiments show that (1) out-of-domain speech samples severely hinder the performance of neural LID models, and (2) while both spectral and cepstral features show comparable performance within-domain, spectral features show more robustness under domain mismatch. Moreover, we apply unsupervised domain adaptation to minimize the discrepancy between the two domains in our study. We achieve relative accuracy improvements that range from 9% to 77% depending on the diversity of acoustic conditions in the source domain.