 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Retention Is Not Enough to Master Memory Tasks in Reinforcement Learning
Jan 21, 2026Effective decision-making in the real world depends on memory that is both stable and adaptive: environments change over time, and agents must retain relevant information over long horizons while also updating or overwriting outdated content when circumstances shift. Existing Reinforcement Learning (RL) benchmarks and memory-augmented agents focus primarily on retention, leaving the equally critical ability of memory rewriting largely unexplored. To address this gap, we introduce a benchmark that explicitly tests continual memory updating under partial observability, i.e. the natural setting where an agent must rely on memory rather than current observations, and use it to compare recurrent, transformer-based, and structured memory architectures. Our experiments reveal that classic recurrent models, despite their simplicity, demonstrate greater flexibility and robustness in memory rewriting tasks than modern structured memories, which succeed only under narrow conditions, and transformer-based agents, which often fail beyond trivial retention cases. These findings expose a fundamental limitation of current approaches and emphasize the necessity of memory mechanisms that balance stable retention with adaptive updating. Our work highlights this overlooked challenge, introduces benchmarks to evaluate it, and offers insights for designing future RL agents with explicit and trainable forgetting mechanisms. Code: https://quartz-admirer.github.io/Memory-Rewriting/
KAGE-Bench: Fast Known-Axis Visual Generalization Evaluation for Reinforcement Learning
Jan 20, 2026Pixel-based reinforcement learning agents often fail under purely visual distribution shift even when latent dynamics and rewards are unchanged, but existing benchmarks entangle multiple sources of shift and hinder systematic analysis. We introduce KAGE-Env, a JAX-native 2D platformer that factorizes the observation process into independently controllable visual axes while keeping the underlying control problem fixed. By construction, varying a visual axis affects performance only through the induced state-conditional action distribution of a pixel policy, providing a clean abstraction for visual generalization. Building on this environment, we define KAGE-Bench, a benchmark of six known-axis suites comprising 34 train-evaluation configuration pairs that isolate individual visual shifts. Using a standard PPO-CNN baseline, we observe strong axis-dependent failures, with background and photometric shifts often collapsing success, while agent-appearance shifts are comparatively benign. Several shifts preserve forward motion while breaking task completion, showing that return alone can obscure generalization failures. Finally, the fully vectorized JAX implementation enables up to 33M environment steps per second on a single GPU, enabling fast and reproducible sweeps over visual factors. Code: https://avanturist322.github.io/KAGEBench/.
HELP: Hierarchical Embodied Language Planner for Household Tasks
Dec 25, 2025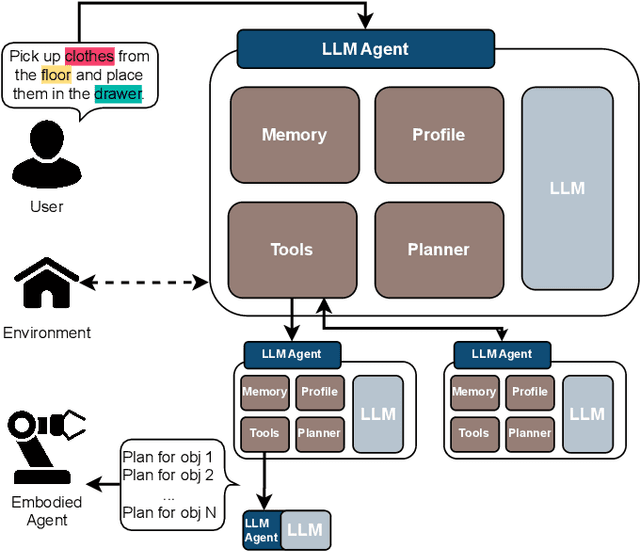

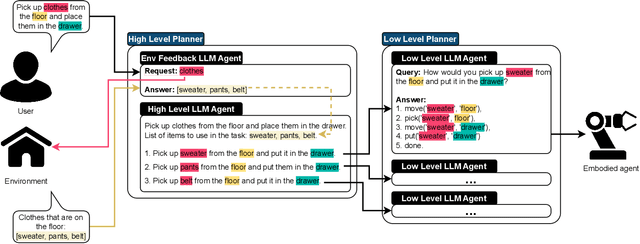
Embodied agents tasked with complex scenarios, whether in real or simulated environments, rely heavily on robust planning capabilities. When instructions are formulated in natural language, large language models (LLMs) equipped with extensive linguistic knowledge can play this role. However, to effectively exploit the ability of such models to handle linguistic ambiguity, to retrieve information from the environment, and to be based on the available skills of an agent, an appropriate architecture must be designed. We propose a Hierarchical Embodied Language Planner, called HELP, consisting of a set of LLM-based agents, each dedicated to solving a different subtask. We evaluate the proposed approach on a household task and perform real-world experiments with an embodied agent. We also focus on the use of open source LLMs with a relatively small number of parameters, to enable autonomous deployment.
LookPlanGraph: Embodied Instruction Following Method with VLM Graph Augmentation
Dec 24, 2025Methods that use Large Language Models (LLM) as planners for embodied instruction following tasks have become widespread. To successfully complete tasks, the LLM must be grounded in the environment in which the robot operates. One solution is to use a scene graph that contains all the necessary information. Modern methods rely on prebuilt scene graphs and assume that all task-relevant information is available at the start of planning. However, these approaches do not account for changes in the environment that may occur between the graph construction and the task execution. We propose LookPlanGraph - a method that leverages a scene graph composed of static assets and object priors. During plan execution, LookPlanGraph continuously updates the graph with relevant objects, either by verifying existing priors or discovering new entities. This is achieved by processing the agents egocentric camera view using a Vision Language Model. We conducted experiments with changed object positions VirtualHome and OmniGibson simulated environments, demonstrating that LookPlanGraph outperforms methods based on predefined static scene graphs. To demonstrate the practical applicability of our approach, we also conducted experiments in a real-world setting. Additionally, we introduce the GraSIF (Graph Scenes for Instruction Following) dataset with automated validation framework, comprising 514 tasks drawn from SayPlan Office, BEHAVIOR-1K, and VirtualHome RobotHow. Project page available at https://lookplangraph.github.io .
ELMUR: External Layer Memory with Update/Rewrite for Long-Horizon RL
Oct 08, 2025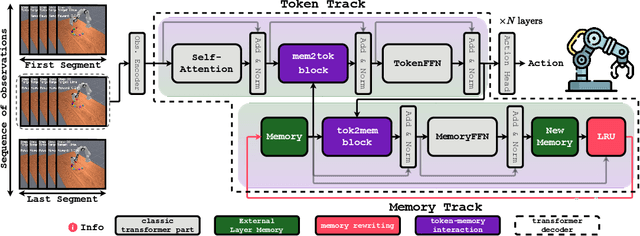

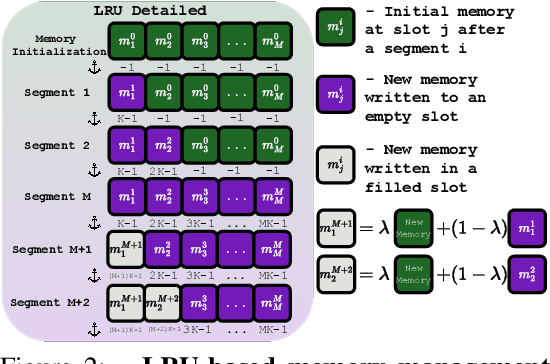
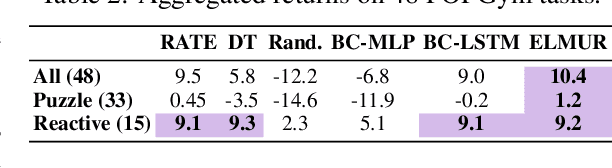
Real-world robotic agents must act under partial observability and long horizons, where key cues may appear long before they affect decision making. However, most modern approaches rely solely on instantaneous information, without incorporating insights from the past. Standard recurrent or transformer models struggle with retaining and leveraging long-term dependencies: context windows truncate history, while naive memory extensions fail under scale and sparsity. We propose ELMUR (External Layer Memory with Update/Rewrite), a transformer architecture with structured external memory. Each layer maintains memory embeddings, interacts with them via bidirectional cross-attention, and updates them through an Least Recently Used (LRU) memory module using replacement or convex blending. ELMUR extends effective horizons up to 100,000 times beyond the attention window and achieves a 100% success rate on a synthetic T-Maze task with corridors up to one million steps. In POPGym, it outperforms baselines on more than half of the tasks. On MIKASA-Robo sparse-reward manipulation tasks with visual observations, it nearly doubles the performance of strong baselines. These results demonstrate that structured, layer-local external memory offers a simple and scalable approach to decision making under partial observability.
Re:Frame -- Retrieving Experience From Associative Memory
Aug 26, 2025Offline reinforcement learning (RL) often deals with suboptimal data when collecting large expert datasets is unavailable or impractical. This limitation makes it difficult for agents to generalize and achieve high performance, as they must learn primarily from imperfect or inconsistent trajectories. A central challenge is therefore how to best leverage scarce expert demonstrations alongside abundant but lower-quality data. We demonstrate that incorporating even a tiny amount of expert experience can substantially improve RL agent performance. We introduce Re:Frame (Retrieving Experience From Associative Memory), a plug-in module that augments a standard offline RL policy (e.g., Decision Transformer) with a small external Associative Memory Buffer (AMB) populated by expert trajectories drawn from a separate dataset. During training on low-quality data, the policy learns to retrieve expert data from the Associative Memory Buffer (AMB) via content-based associations and integrate them into decision-making; the same AMB is queried at evaluation. This requires no environment interaction and no modifications to the backbone architecture. On D4RL MuJoCo tasks, using as few as 60 expert trajectories (0.1% of a 6000-trajectory dataset), Re:Frame consistently improves over a strong Decision Transformer baseline in three of four settings, with gains up to +10.7 normalized points. These results show that Re:Frame offers a simple and data-efficient way to inject scarce expert knowledge and substantially improve offline RL from low-quality datasets.
Spatial Traces: Enhancing VLA Models with Spatial-Temporal Understanding
Aug 12, 2025Vision-Language-Action models have demonstrated remarkable capabilities in predicting agent movements within virtual environments and real-world scenarios based on visual observations and textual instructions. Although recent research has focused on enhancing spatial and temporal understanding independently, this paper presents a novel approach that integrates both aspects through visual prompting. We introduce a method that projects visual traces of key points from observations onto depth maps, enabling models to capture both spatial and temporal information simultaneously. The experiments in SimplerEnv show that the mean number of tasks successfully solved increased for 4% compared to SpatialVLA and 19% compared to TraceVLA. Furthermore, we show that this enhancement can be achieved with minimal training data, making it particularly valuable for real-world applications where data collection is challenging. The project page is available at https://ampiromax.github.io/ST-VLA.
Safe Planning and Policy Optimization via World Model Learning
Jun 05, 2025Reinforcement Learning (RL) applications in real-world scenarios must prioritize safety and reliability, which impose strict constraints on agent behavior. Model-based RL leverages predictive world models for action planning and policy optimization, but inherent model inaccuracies can lead to catastrophic failures in safety-critical settings. We propose a novel model-based RL framework that jointly optimizes task performance and safety. To address world model errors, our method incorporates an adaptive mechanism that dynamically switches between model-based planning and direct policy execution. We resolve the objective mismatch problem of traditional model-based approaches using an implicit world model. Furthermore, our framework employs dynamic safety thresholds that adapt to the agent's evolving capabilities, consistently selecting actions that surpass safe policy suggestions in both performance and safety. Experiments demonstrate significant improvements over non-adaptive methods, showing that our approach optimizes safety and performance simultaneously rather than merely meeting minimum safety requirements. The proposed framework achieves robust performance on diverse safety-critical continuous control tasks, outperforming existing methods.
AmbiK: Dataset of Ambiguous Tasks in Kitchen Environment
Jun 04, 2025



As a part of an embodied agent, Large Language Models (LLMs) are typically used for behavior planning given natural language instructions from the user. However, dealing with ambiguous instructions in real-world environments remains a challenge for LLMs. Various methods for task ambiguity detection have been proposed. However, it is difficult to compare them because they are tested on different datasets and there is no universal benchmark. For this reason, we propose AmbiK (Ambiguous Tasks in Kitchen Environment), the fully textual dataset of ambiguous instructions addressed to a robot in a kitchen environment. AmbiK was collected with the assistance of LLMs and is human-validated. It comprises 1000 pairs of ambiguous tasks and their unambiguous counterparts, categorized by ambiguity type (Human Preferences, Common Sense Knowledge, Safety), with environment descriptions, clarifying questions and answers, user intents, and task plans, for a total of 2000 tasks. We hope that AmbiK will enable researchers to perform a unified comparison of ambiguity detection methods. AmbiK is available at https://github.com/cog-model/AmbiK-dataset.
CrafText Benchmark: Advancing Instruction Following in Complex Multimodal Open-Ended World
May 17, 2025Following instructions in real-world conditions requires the ability to adapt to the world's volatility and entanglement: the environment is dynamic and unpredictable, instructions can be linguistically complex with diverse vocabulary, and the number of possible goals an agent may encounter is vast. Despite extensive research in this area, most studies are conducted in static environments with simple instructions and a limited vocabulary, making it difficult to assess agent performance in more diverse and challenging settings. To address this gap, we introduce CrafText, a benchmark for evaluating instruction following in a multimodal environment with diverse instructions and dynamic interactions. CrafText includes 3,924 instructions with 3,423 unique words, covering Localization, Conditional, Building, and Achievement tasks. Additionally, we propose an evaluation protocol that measures an agent's ability to generalize to novel instruction formulations and dynamically evolving task configurations, providing a rigorous test of both linguistic understanding and adaptive decision-making.