 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Image to Video: An Empirical Study of Diffusion Representations
Feb 10, 2025Diffusion models have revolutionized generative modeling, enabling unprecedented realism in image and video synthesis. This success has sparked interest in leveraging their representations for visual understanding tasks. While recent works have explored this potential for image generation, the visual understanding capabilities of video diffusion models remain largely uncharted. To address this gap, we systematically compare the same model architecture trained for video versus image generation, analyzing the performance of their latent representations on various downstream tasks including image classification, action recognition, depth estimation, and tracking. Results show that video diffusion models consistently outperform their image counterparts, though we find a striking range in the extent of this superiority. We further analyze features extracted from different layers and with varying noise levels, as well as the effect of model size and training budget on representation and generation quality. This work marks the first direct comparison of video and image diffusion objectives for visual understanding, offering insights into the role of temporal information in representation learning.
Multi-Object Representation Learning with Iterative Variational Inference
Mar 01, 2019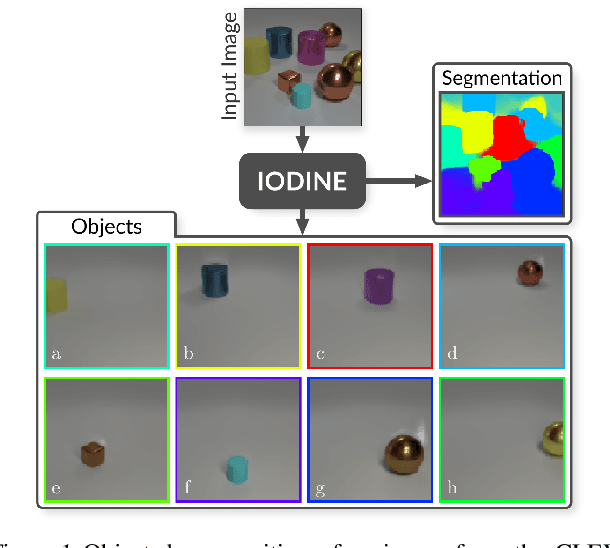

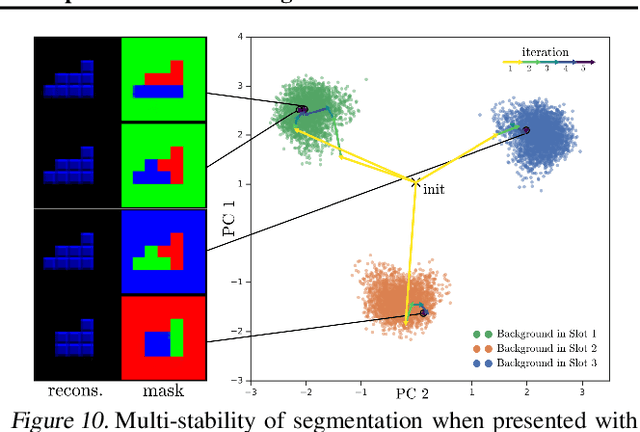

Human perception is structured around objects which form the basis for our higher-level cognition and impressive systematic generalization abilities. Yet most work on representation learning focuses on feature learning without even considering multiple objects, or treats segmentation as an (often supervised) preprocessing step. Instead, we argue for the importance of learning to segment and represent objects jointly. We demonstrate that, starting from the simple assumption that a scene is composed of multiple entities, it is possible to learn to segment images into interpretable objects with disentangled representations. Our method learns -- without supervision -- to inpaint occluded parts, and extrapolates to scenes with more objects and to unseen objects with novel feature combinations. We also show that, due to the use of iterative variational inference, our system is able to learn multi-modal posteriors for ambiguous inputs and extends naturally to sequences.