 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Image Compression for Machine Perception
Nov 03, 2021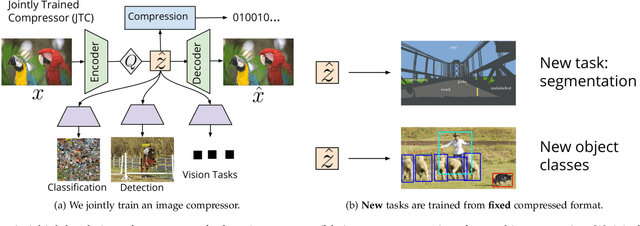
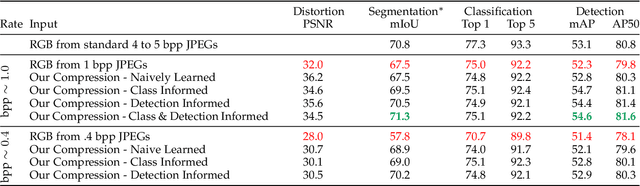
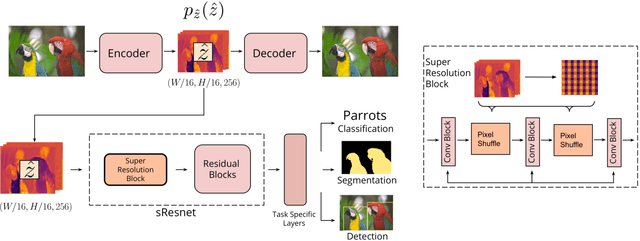

Recent work has shown that learned image compression strategies can outperform standard hand-crafted compression algorithms that have been developed over decades of intensive research on the rate-distortion trade-off. With growing applications of computer vision, high quality image reconstruction from a compressible representation is often a secondary objective. Compression that ensures high accuracy on computer vision tasks such as image segmentation, classification, and detection therefore has the potential for significant impact across a wide variety of settings. In this work, we develop a framework that produces a compression format suitable for both human perception and machine perception. We show that representations can be learned that simultaneously optimize for compression and performance on core vision tasks. Our approach allows models to be trained directly from compressed representations, and this approach yields increased performance on new tasks and in low-shot learning settings. We present results that improve upon segmentation and detection performance compared to standard high quality JPGs, but with representations that are four to ten times smaller in terms of bits per pixel. Further, unlike naive compression methods, at a level ten times smaller than standard JEPGs, segmentation and detection models trained from our format suffer only minor degradation in performance.