 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBootsTAP: Bootstrapped Training for Tracking-Any-Point
Paper and Code
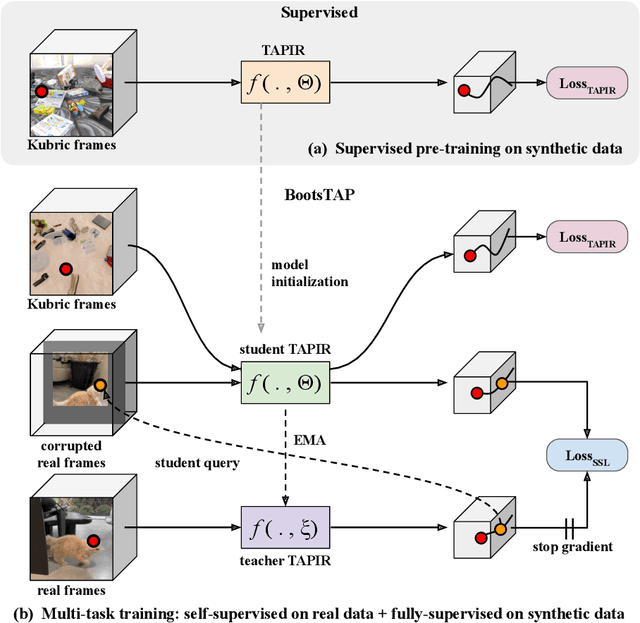
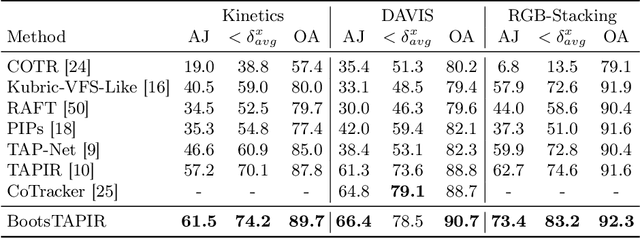
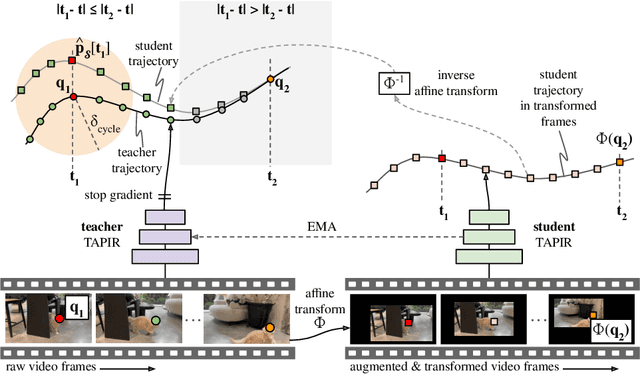
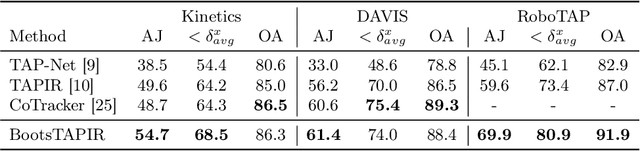
To endow models with greater understanding of physics and motion, it is useful to enable them to perceive how solid surfaces move and deform in real scenes. This can be formalized as Tracking-Any-Point (TAP), which requires the algorithm to be able to track any point corresponding to a solid surface in a video, potentially densely in space and time. Large-scale ground-truth training data for TAP is only available in simulation, which currently has limited variety of objects and motion. In this work, we demonstrate how large-scale, unlabeled, uncurated real-world data can improve a TAP model with minimal architectural changes, using a self-supervised student-teacher setup. We demonstrate state-of-the-art performance on the TAP-Vid benchmark surpassing previous results by a wide margin: for example, TAP-Vid-DAVIS performance improves from 61.3% to 66.4%, and TAP-Vid-Kinetics from 57.2% to 61.5%.