 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Action Diffusion for Robust End-to-End Autonomous Driving
Jun 01, 2026End-to-End Autonomous Driving (E2E-AD) systems have largely converged on predicting intermediate trajectory waypoints, delegating final control to hand-crafted controllers with GPS access. Direct control-signal prediction (outputting throttle, steer and brake in an end-to-end fashion) remains underexplored, and critically, the role of action multimodality in such systems is not well understood. We argue that moving beyond deterministic, single-action outputs is not merely a modelling choice, but a key driver of driving performance, representational quality, and training stability. To validate this, we introduce the Action Diffusion Transformer (ADT), an anchor-free diffusion transformer trained with a MSE objective that natively models the multimodal distribution of plausible driving actions. Rather than committing to a single deterministic command, ADT generates K action candidates and selects the most suitable one at inference via Nearest Neighbour Matching (NNM). Beyond strong benchmark numbers, we show that action multimodality yields measurable benefits in learned representations and behavioral consistency, effects that deterministic architectures cannot replicate. ADT surpasses previous state-of-the-art on the challenging closed-loop Bench2Drive benchmark while achieving ten times lower latency, demonstrating that expressive, multimodal action modelling is both practically efficient and conceptually essential for robust end-to-end driving.
Addressing the Waypoint-Action Gap in End-to-End Autonomous Driving via Vehicle Motion Models
Feb 09, 2026End-to-End Autonomous Driving (E2E-AD) systems are typically grouped by the nature of their outputs: (i) waypoint-based models that predict a future trajectory, and (ii) action-based models that directly output throttle, steer and brake. Most recent benchmark protocols and training pipelines are waypoint-based, which makes action-based policies harder to train and compare, slowing their progress. To bridge this waypoint-action gap, we propose a novel, differentiable vehicle-model framework that rolls out predicted action sequences to their corresponding ego-frame waypoint trajectories while supervising in waypoint space. Our approach enables action-based architectures to be trained and evaluated, for the first time, within waypoint-based benchmarks without modifying the underlying evaluation protocol. We extensively evaluate our framework across multiple challenging benchmarks and observe consistent improvements over the baselines. In particular, on NAVSIM \texttt{navhard} our approach achieves state-of-the-art performance. Our code will be made publicly available upon acceptance.
Towards Kinetic Manipulation of the Latent Space
Sep 15, 2024The latent space of many generative models are rich in unexplored valleys and mountains. The majority of tools used for exploring them are so far limited to Graphical User Interfaces (GUIs). While specialized hardware can be used for this task, we show that a simple feature extraction of pre-trained Convolutional Neural Networks (CNNs) from a live RGB camera feed does a very good job at manipulating the latent space with simple changes in the scene, with vast room for improvement. We name this new paradigm Visual-reactive Interpolation, and the full code can be found at https://github.com/PDillis/stylegan3-fun.
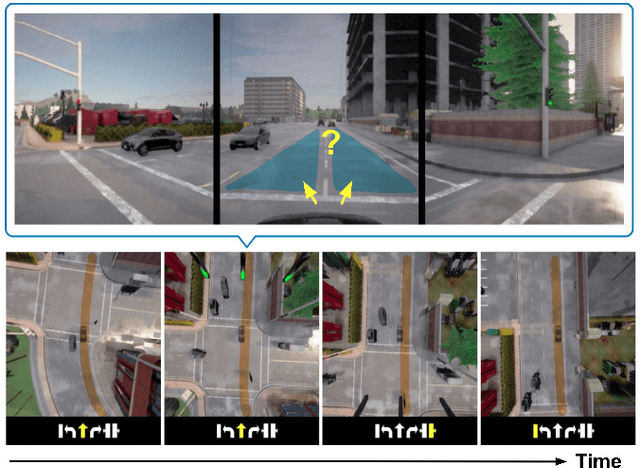
Guiding Attention in End-to-End Driving Models
Apr 30, 2024



Vision-based end-to-end driving models trained by imitation learning can lead to affordable solutions for autonomous driving. However, training these well-performing models usually requires a huge amount of data, while still lacking explicit and intuitive activation maps to reveal the inner workings of these models while driving. In this paper, we study how to guide the attention of these models to improve their driving quality and obtain more intuitive activation maps by adding a loss term during training using salient semantic maps. In contrast to previous work, our method does not require these salient semantic maps to be available during testing time, as well as removing the need to modify the model's architecture to which it is applied. We perform tests using perfect and noisy salient semantic maps with encouraging results in both, the latter of which is inspired by possible errors encountered with real data. Using CIL++ as a representative state-of-the-art model and the CARLA simulator with its standard benchmarks, we conduct experiments that show the effectiveness of our method in training better autonomous driving models, especially when data and computational resources are scarce.
Scaling Self-Supervised End-to-End Driving with Multi-View Attention Learning
Feb 09, 2023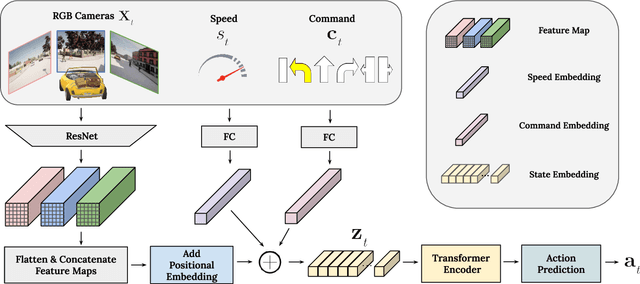


On end-to-end driving, a large amount of expert driving demonstrations is used to train an agent that mimics the expert by predicting its control actions. This process is self-supervised on vehicle signals (e.g., steering angle, acceleration) and does not require extra costly supervision (human labeling). Yet, the improvement of existing self-supervised end-to-end driving models has mostly given room to modular end-to-end models where labeling data intensive format such as semantic segmentation are required during training time. However, we argue that the latest self-supervised end-to-end models were developed in sub-optimal conditions with low-resolution images and no attention mechanisms. Further, those models are confined with limited field of view and far from the human visual cognition which can quickly attend far-apart scene features, a trait that provides an useful inductive bias. In this context, we present a new end-to-end model, trained by self-supervised imitation learning, leveraging a large field of view and a self-attention mechanism. These settings are more contributing to the agent's understanding of the driving scene, which brings a better imitation of human drivers. With only self-supervised training data, our model yields almost expert performance in CARLA's Nocrash metrics and could be rival to the SOTA models requiring large amounts of human labeled data. To facilitate further research, our code will be released.
Discriminator Synthesis: On reusing the other half of Generative Adversarial Networks
Nov 12, 2021



Generative Adversarial Networks have long since revolutionized the world of computer vision and, tied to it, the world of art. Arduous efforts have gone into fully utilizing and stabilizing training so that outputs of the Generator network have the highest possible fidelity, but little has gone into using the Discriminator after training is complete. In this work, we propose to use the latter and show a way to use the features it has learned from the training dataset to both alter an image and generate one from scratch. We name this method Discriminator Dreaming, and the full code can be found at https://github.com/PDillis/stylegan3-fun.