 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Self-Supervised End-to-End Driving with Multi-View Attention Learning
Paper and Code
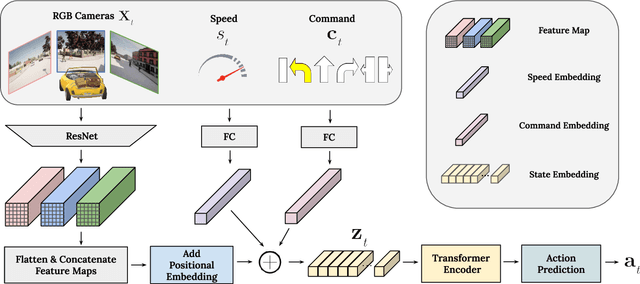
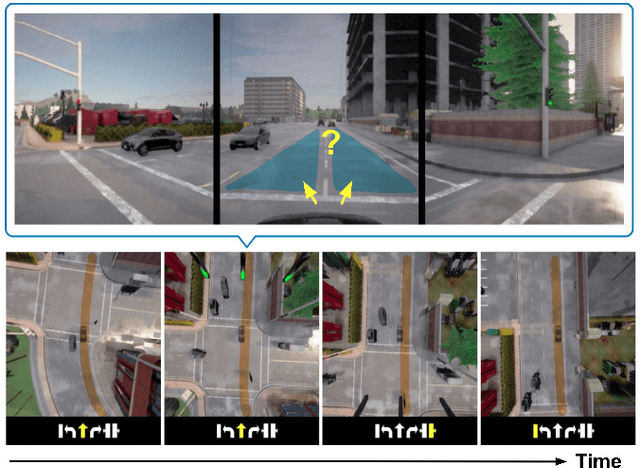


On end-to-end driving, a large amount of expert driving demonstrations is used to train an agent that mimics the expert by predicting its control actions. This process is self-supervised on vehicle signals (e.g., steering angle, acceleration) and does not require extra costly supervision (human labeling). Yet, the improvement of existing self-supervised end-to-end driving models has mostly given room to modular end-to-end models where labeling data intensive format such as semantic segmentation are required during training time. However, we argue that the latest self-supervised end-to-end models were developed in sub-optimal conditions with low-resolution images and no attention mechanisms. Further, those models are confined with limited field of view and far from the human visual cognition which can quickly attend far-apart scene features, a trait that provides an useful inductive bias. In this context, we present a new end-to-end model, trained by self-supervised imitation learning, leveraging a large field of view and a self-attention mechanism. These settings are more contributing to the agent's understanding of the driving scene, which brings a better imitation of human drivers. With only self-supervised training data, our model yields almost expert performance in CARLA's Nocrash metrics and could be rival to the SOTA models requiring large amounts of human labeled data. To facilitate further research, our code will be released.