 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSal: Joint Audio and Video Learning for Diffusion Saliency Prediction
Mar 02, 2024



Audio-visual saliency prediction can draw support from diverse modality complements, but further performance enhancement is still challenged by customized architectures as well as task-specific loss functions. In recent studies, denoising diffusion models have shown more promising in unifying task frameworks owing to their inherent ability of generalization. Following this motivation, a novel Diffusion architecture for generalized audio-visual Saliency prediction (DiffSal) is proposed in this work, which formulates the prediction problem as a conditional generative task of the saliency map by utilizing input audio and video as the conditions. Based on the spatio-temporal audio-visual features, an extra network Saliency-UNet is designed to perform multi-modal attention modulation for progressive refinement of the ground-truth saliency map from the noisy map. Extensive experiments demonstrate that the proposed DiffSal can achieve excellent performance across six challenging audio-visual benchmarks, with an average relative improvement of 6.3\% over the previous state-of-the-art results by six metrics.
UniST: Towards Unifying Saliency Transformer for Video Saliency Prediction and Detection
Sep 15, 2023Video saliency prediction and detection are thriving research domains that enable computers to simulate the distribution of visual attention akin to how humans perceiving dynamic scenes. While many approaches have crafted task-specific training paradigms for either video saliency prediction or video salient object detection tasks, few attention has been devoted to devising a generalized saliency modeling framework that seamlessly bridges both these distinct tasks. In this study, we introduce the Unified Saliency Transformer (UniST) framework, which comprehensively utilizes the essential attributes of video saliency prediction and video salient object detection. In addition to extracting representations of frame sequences, a saliency-aware transformer is designed to learn the spatio-temporal representations at progressively increased resolutions, while incorporating effective cross-scale saliency information to produce a robust representation. Furthermore, a task-specific decoder is proposed to perform the final prediction for each task. To the best of our knowledge, this is the first work that explores designing a transformer structure for both saliency modeling tasks. Convincible experiments demonstrate that the proposed UniST achieves superior performance across seven challenging benchmarks for two tasks, and significantly outperforms the other state-of-the-art methods.
Induction Network: Audio-Visual Modality Gap-Bridging for Self-Supervised Sound Source Localization
Aug 09, 2023



Self-supervised sound source localization is usually challenged by the modality inconsistency. In recent studies, contrastive learning based strategies have shown promising to establish such a consistent correspondence between audio and sound sources in visual scenarios. Unfortunately, the insufficient attention to the heterogeneity influence in the different modality features still limits this scheme to be further improved, which also becomes the motivation of our work. In this study, an Induction Network is proposed to bridge the modality gap more effectively. By decoupling the gradients of visual and audio modalities, the discriminative visual representations of sound sources can be learned with the designed Induction Vector in a bootstrap manner, which also enables the audio modality to be aligned with the visual modality consistently. In addition to a visual weighted contrastive loss, an adaptive threshold selection strategy is introduced to enhance the robustness of the Induction Network. Substantial experiments conducted on SoundNet-Flickr and VGG-Sound Source datasets have demonstrated a superior performance compared to other state-of-the-art works in different challenging scenarios. The code is available at https://github.com/Tahy1/AVIN
FTFDNet: Learning to Detect Talking Face Video Manipulation with Tri-Modality Interaction
Jul 08, 2023



DeepFake based digital facial forgery is threatening public media security, especially when lip manipulation has been used in talking face generation, and the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity are hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face videos also becomes inevitable. It's found that the optical flow of the fake talking face video is disordered especially in the lip region while the optical flow of the real video changes regularly, which means the motion feature from optical flow is useful to capture manipulation cues. In this study, a fake talking face detection network (FTFDNet) is proposed by incorporating visual, audio and motion features using an efficient cross-modal fusion (CMF) module. Furthermore, a novel audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architecture by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance than other state-of-the-art DeepFake video detection methods not only on the established fake talking face detection dataset (FTFDD) but also on the DeepFake video detection datasets (DFDC and DF-TIMIT).
CASP-Net: Rethinking Video Saliency Prediction from an Audio-VisualConsistency Perceptual Perspective
Mar 11, 2023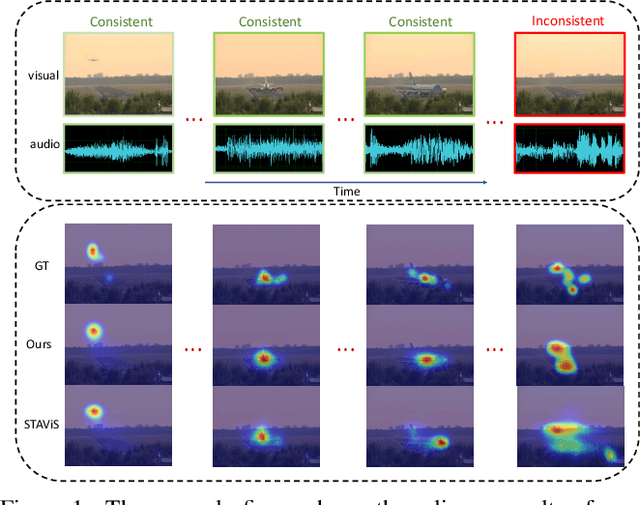



Incorporating the audio stream enables Video Saliency Prediction (VSP) to imitate the selective attention mechanism of human brain. By focusing on the benefits of joint auditory and visual information, most VSP methods are capable of exploiting semantic correlation between vision and audio modalities but ignoring the negative effects due to the temporal inconsistency of audio-visual intrinsics. Inspired by the biological inconsistency-correction within multi-sensory information, in this study, a consistency-aware audio-visual saliency prediction network (CASP-Net) is proposed, which takes a comprehensive consideration of the audio-visual semantic interaction and consistent perception. In addition a two-stream encoder for elegant association between video frames and corresponding sound source, a novel consistency-aware predictive coding is also designed to improve the consistency within audio and visual representations iteratively. To further aggregate the multi-scale audio-visual information, a saliency decoder is introduced for the final saliency map generation. Substantial experiments demonstrate that the proposed CASP-Net outperforms the other state-of-the-art methods on six challenging audio-visual eye-tracking datasets. For a demo of our system please see our project webpage.
An Audio-Visual Attention Based Multimodal Network for Fake Talking Face Videos Detection
Mar 10, 2022


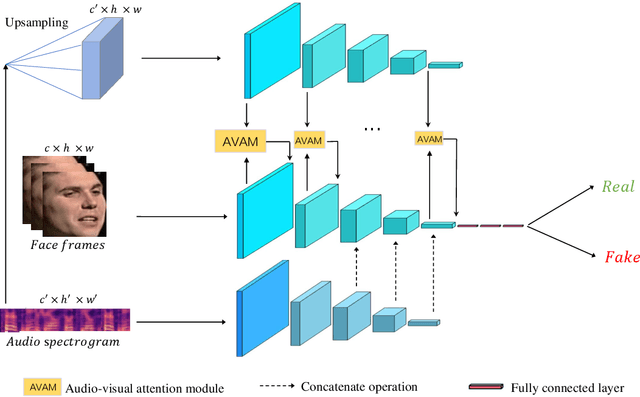
DeepFake based digital facial forgery is threatening the public media security, especially when lip manipulation has been used in talking face generation, the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity is hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face generation also becomes inevitable. Inspired by the decision-making mechanism of human multisensory perception system, which enables the auditory information to enhance post-sensory visual evidence for informed decisions output, in this study, a fake talking face detection framework FTFDNet is proposed by incorporating audio and visual representation to achieve more accurate fake talking face videos detection. Furthermore, an audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architectures by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance on the established dataset (FTFDD). The evaluation of the proposed work has shown an excellent performance on the detection of fake talking face videos, which is able to arrive at a detection rate above 97%.
Attention-Based Lip Audio-Visual Synthesis for Talking Face Generation in the Wild
Mar 08, 2022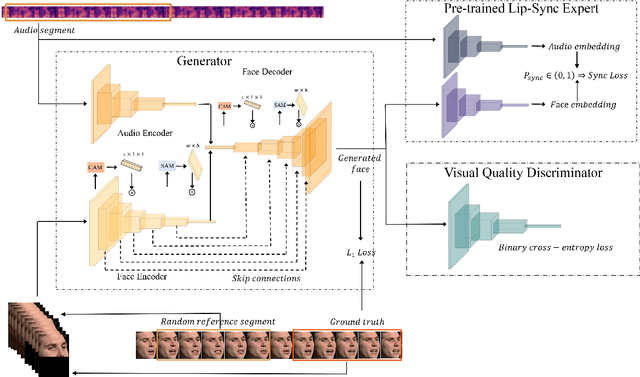
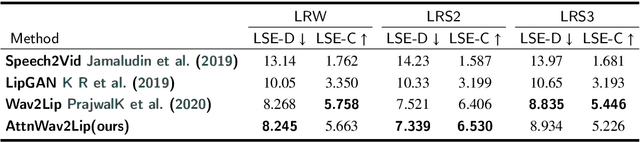
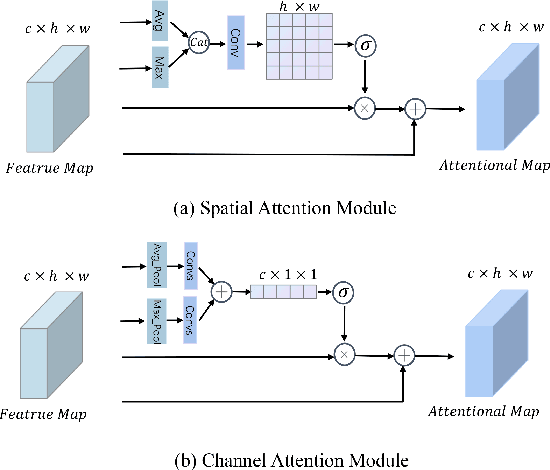
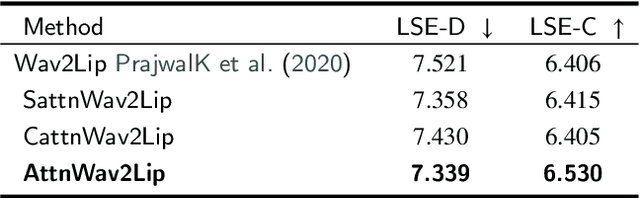
Talking face generation with great practical significance has attracted more attention in recent audio-visual studies. How to achieve accurate lip synchronization is a long-standing challenge to be further investigated. Motivated by xxx, in this paper, an AttnWav2Lip model is proposed by incorporating spatial attention module and channel attention module into lip-syncing strategy. Rather than focusing on the unimportant regions of the face image, the proposed AttnWav2Lip model is able to pay more attention on the lip region reconstruction. To our limited knowledge, this is the first attempt to introduce attention mechanism to the scheme of talking face generation. An extensive experiments have been conducted to evaluate the effectiveness of the proposed model. Compared to the baseline measured by LSE-D and LSE-C metrics, a superior performance has been demonstrated on the benchmark lip synthesis datasets, including LRW, LRS2 and LRS3.
Audio-visual speech separation based on joint feature representation with cross-modal attention
Mar 05, 2022

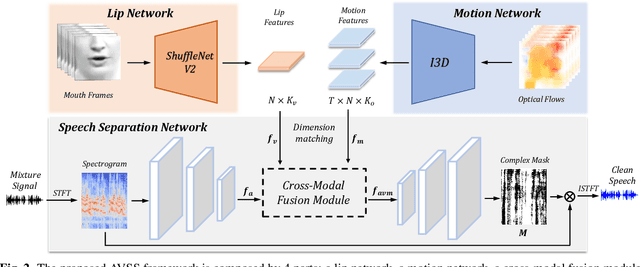
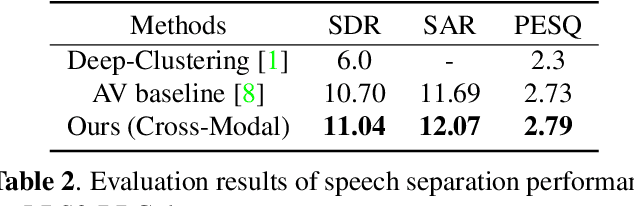
Multi-modal based speech separation has exhibited a specific advantage on isolating the target character in multi-talker noisy environments. Unfortunately, most of current separation strategies prefer a straightforward fusion based on feature learning of each single modality, which is far from sufficient consideration of inter-relationships between modalites. Inspired by learning joint feature representations from audio and visual streams with attention mechanism, in this study, a novel cross-modal fusion strategy is proposed to benefit the whole framework with semantic correlations between different modalities. To further improve audio-visual speech separation, the dense optical flow of lip motion is incorporated to strengthen the robustness of visual representation. The evaluation of the proposed work is performed on two public audio-visual speech separation benchmark datasets. The overall improvement of the performance has demonstrated that the additional motion network effectively enhances the visual representation of the combined lip images and audio signal, as well as outperforming the baseline in terms of all metrics with the proposed cross-modal fusion.
Look\&Listen: Multi-Modal Correlation Learning for Active Speaker Detection and Speech Enhancement
Mar 04, 2022


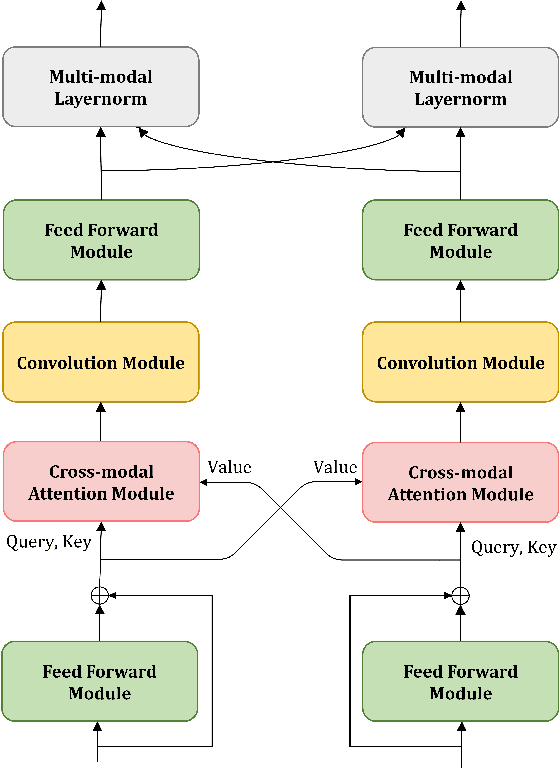
Active speaker detection and speech enhancement have become two increasingly attractive topics in audio-visual scenario understanding. According to their respective characteristics, the scheme of independently designed architecture has been widely used in correspondence to each single task. This may lead to the learned feature representation being task-specific, and inevitably result in the lack of generalization ability of the feature based on multi-modal modeling. More recent studies have shown that establishing cross-modal relationship between auditory and visual stream is a promising solution for the challenge of audio-visual multi-task learning. Therefore, as a motivation to bridge the multi-modal cross-attention, in this work, a unified framework ADENet is proposed to achieve target speaker detection and speech enhancement with joint learning of audio-visual modeling.
Unsupervised Cross-Modal Distillation for Thermal Infrared Tracking
Jul 31, 2021
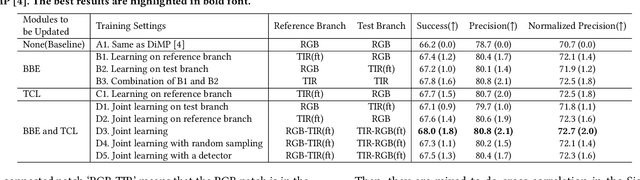
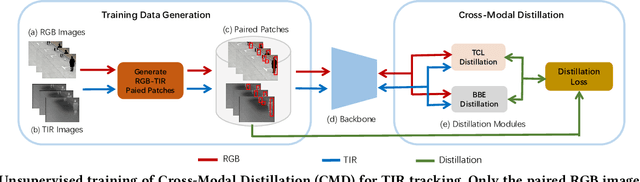
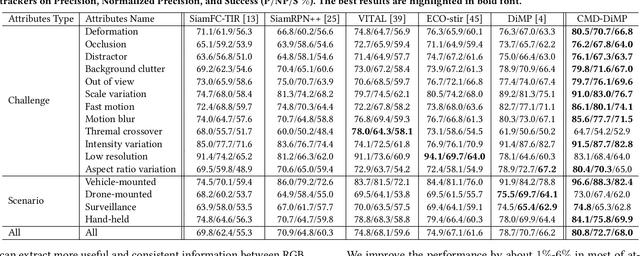
The target representation learned by convolutional neural networks plays an important role in Thermal Infrared (TIR) tracking. Currently, most of the top-performing TIR trackers are still employing representations learned by the model trained on the RGB data. However, this representation does not take into account the information in the TIR modality itself, limiting the performance of TIR tracking. To solve this problem, we propose to distill representations of the TIR modality from the RGB modality with Cross-Modal Distillation (CMD) on a large amount of unlabeled paired RGB-TIR data. We take advantage of the two-branch architecture of the baseline tracker, i.e. DiMP, for cross-modal distillation working on two components of the tracker. Specifically, we use one branch as a teacher module to distill the representation learned by the model into the other branch. Benefiting from the powerful model in the RGB modality, the cross-modal distillation can learn the TIR-specific representation for promoting TIR tracking. The proposed approach can be incorporated into different baseline trackers conveniently as a generic and independent component. Furthermore, the semantic coherence of paired RGB and TIR images is utilized as a supervised signal in the distillation loss for cross-modal knowledge transfer. In practice, three different approaches are explored to generate paired RGB-TIR patches with the same semantics for training in an unsupervised way. It is easy to extend to an even larger scale of unlabeled training data. Extensive experiments on the LSOTB-TIR dataset and PTB-TIR dataset demonstrate that our proposed cross-modal distillation method effectively learns TIR-specific target representations transferred from the RGB modality. Our tracker outperforms the baseline tracker by achieving absolute gains of 2.3% Success, 2.7% Precision, and 2.5% Normalized Precision respectively.