 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFTFDNet: Learning to Detect Talking Face Video Manipulation with Tri-Modality Interaction
Jul 08, 2023



DeepFake based digital facial forgery is threatening public media security, especially when lip manipulation has been used in talking face generation, and the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity are hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face videos also becomes inevitable. It's found that the optical flow of the fake talking face video is disordered especially in the lip region while the optical flow of the real video changes regularly, which means the motion feature from optical flow is useful to capture manipulation cues. In this study, a fake talking face detection network (FTFDNet) is proposed by incorporating visual, audio and motion features using an efficient cross-modal fusion (CMF) module. Furthermore, a novel audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architecture by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance than other state-of-the-art DeepFake video detection methods not only on the established fake talking face detection dataset (FTFDD) but also on the DeepFake video detection datasets (DFDC and DF-TIMIT).
CASP-Net: Rethinking Video Saliency Prediction from an Audio-VisualConsistency Perceptual Perspective
Mar 11, 2023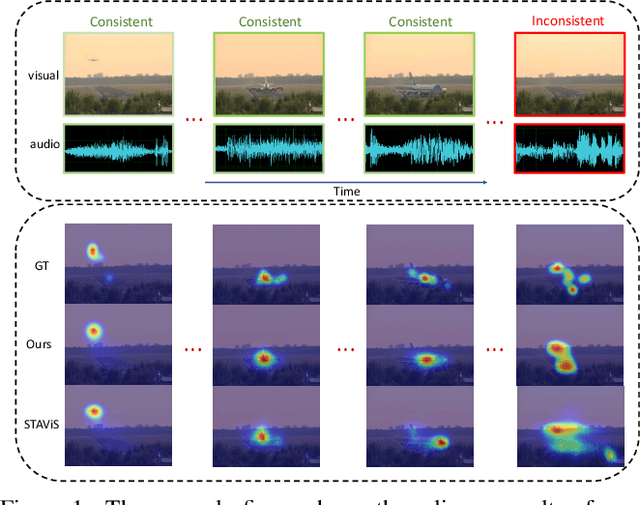



Incorporating the audio stream enables Video Saliency Prediction (VSP) to imitate the selective attention mechanism of human brain. By focusing on the benefits of joint auditory and visual information, most VSP methods are capable of exploiting semantic correlation between vision and audio modalities but ignoring the negative effects due to the temporal inconsistency of audio-visual intrinsics. Inspired by the biological inconsistency-correction within multi-sensory information, in this study, a consistency-aware audio-visual saliency prediction network (CASP-Net) is proposed, which takes a comprehensive consideration of the audio-visual semantic interaction and consistent perception. In addition a two-stream encoder for elegant association between video frames and corresponding sound source, a novel consistency-aware predictive coding is also designed to improve the consistency within audio and visual representations iteratively. To further aggregate the multi-scale audio-visual information, a saliency decoder is introduced for the final saliency map generation. Substantial experiments demonstrate that the proposed CASP-Net outperforms the other state-of-the-art methods on six challenging audio-visual eye-tracking datasets. For a demo of our system please see our project webpage.
An Audio-Visual Attention Based Multimodal Network for Fake Talking Face Videos Detection
Mar 10, 2022


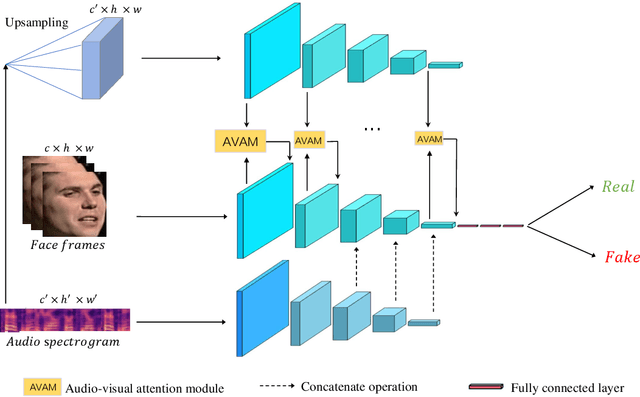
DeepFake based digital facial forgery is threatening the public media security, especially when lip manipulation has been used in talking face generation, the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity is hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face generation also becomes inevitable. Inspired by the decision-making mechanism of human multisensory perception system, which enables the auditory information to enhance post-sensory visual evidence for informed decisions output, in this study, a fake talking face detection framework FTFDNet is proposed by incorporating audio and visual representation to achieve more accurate fake talking face videos detection. Furthermore, an audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architectures by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance on the established dataset (FTFDD). The evaluation of the proposed work has shown an excellent performance on the detection of fake talking face videos, which is able to arrive at a detection rate above 97%.
Attention-Based Lip Audio-Visual Synthesis for Talking Face Generation in the Wild
Mar 08, 2022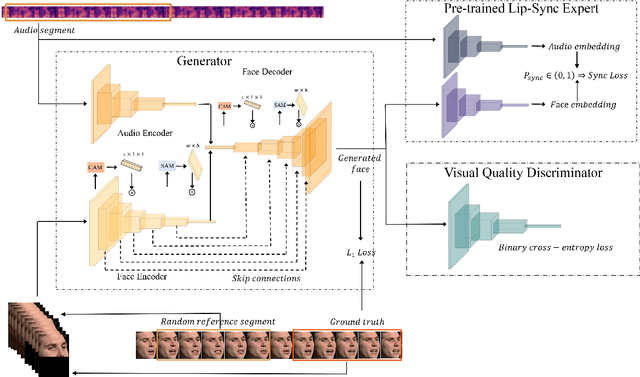
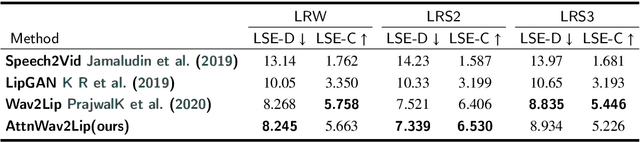
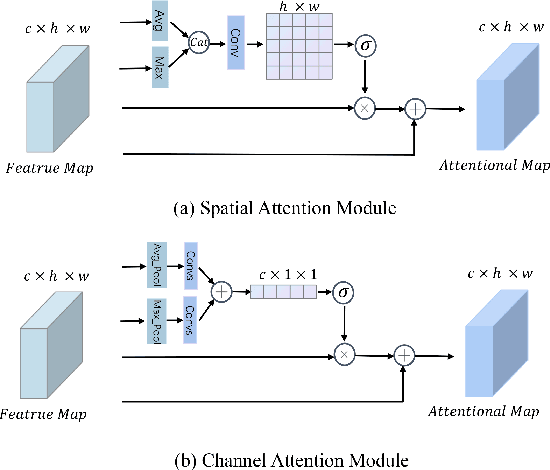
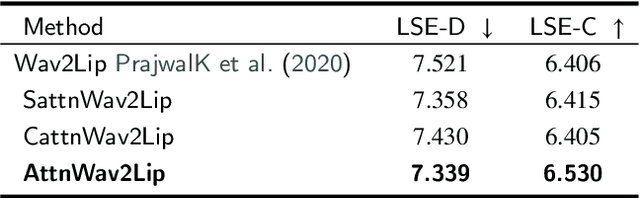
Talking face generation with great practical significance has attracted more attention in recent audio-visual studies. How to achieve accurate lip synchronization is a long-standing challenge to be further investigated. Motivated by xxx, in this paper, an AttnWav2Lip model is proposed by incorporating spatial attention module and channel attention module into lip-syncing strategy. Rather than focusing on the unimportant regions of the face image, the proposed AttnWav2Lip model is able to pay more attention on the lip region reconstruction. To our limited knowledge, this is the first attempt to introduce attention mechanism to the scheme of talking face generation. An extensive experiments have been conducted to evaluate the effectiveness of the proposed model. Compared to the baseline measured by LSE-D and LSE-C metrics, a superior performance has been demonstrated on the benchmark lip synthesis datasets, including LRW, LRS2 and LRS3.