 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Audio-Visual Attention Based Multimodal Network for Fake Talking Face Videos Detection
Paper and Code
Mar 10, 2022


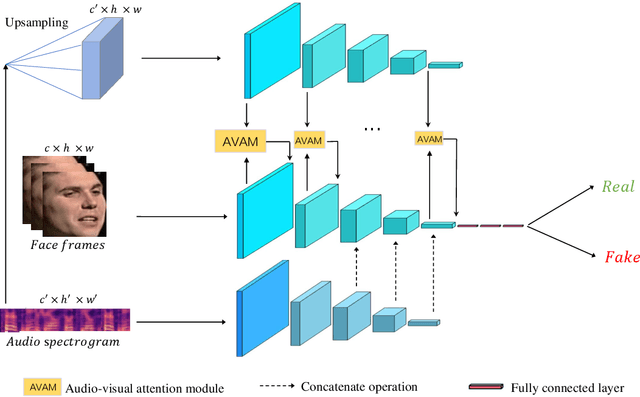
DeepFake based digital facial forgery is threatening the public media security, especially when lip manipulation has been used in talking face generation, the difficulty of fake video detection is further improved. By only changing lip shape to match the given speech, the facial features of identity is hard to be discriminated in such fake talking face videos. Together with the lack of attention on audio stream as the prior knowledge, the detection failure of fake talking face generation also becomes inevitable. Inspired by the decision-making mechanism of human multisensory perception system, which enables the auditory information to enhance post-sensory visual evidence for informed decisions output, in this study, a fake talking face detection framework FTFDNet is proposed by incorporating audio and visual representation to achieve more accurate fake talking face videos detection. Furthermore, an audio-visual attention mechanism (AVAM) is proposed to discover more informative features, which can be seamlessly integrated into any audio-visual CNN architectures by modularization. With the additional AVAM, the proposed FTFDNet is able to achieve a better detection performance on the established dataset (FTFDD). The evaluation of the proposed work has shown an excellent performance on the detection of fake talking face videos, which is able to arrive at a detection rate above 97%.