 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffSal: Joint Audio and Video Learning for Diffusion Saliency Prediction
Mar 02, 2024



Audio-visual saliency prediction can draw support from diverse modality complements, but further performance enhancement is still challenged by customized architectures as well as task-specific loss functions. In recent studies, denoising diffusion models have shown more promising in unifying task frameworks owing to their inherent ability of generalization. Following this motivation, a novel Diffusion architecture for generalized audio-visual Saliency prediction (DiffSal) is proposed in this work, which formulates the prediction problem as a conditional generative task of the saliency map by utilizing input audio and video as the conditions. Based on the spatio-temporal audio-visual features, an extra network Saliency-UNet is designed to perform multi-modal attention modulation for progressive refinement of the ground-truth saliency map from the noisy map. Extensive experiments demonstrate that the proposed DiffSal can achieve excellent performance across six challenging audio-visual benchmarks, with an average relative improvement of 6.3\% over the previous state-of-the-art results by six metrics.
LLM-Assisted Multi-Teacher Continual Learning for Visual Question Answering in Robotic Surgery
Feb 26, 2024



Visual question answering (VQA) can be fundamentally crucial for promoting robotic-assisted surgical education. In practice, the needs of trainees are constantly evolving, such as learning more surgical types, adapting to different robots, and learning new surgical instruments and techniques for one surgery. Therefore, continually updating the VQA system by a sequential data stream from multiple resources is demanded in robotic surgery to address new tasks. In surgical scenarios, the storage cost and patient data privacy often restrict the availability of old data when updating the model, necessitating an exemplar-free continual learning (CL) setup. However, prior studies overlooked two vital problems of the surgical domain: i) large domain shifts from diverse surgical operations collected from multiple departments or clinical centers, and ii) severe data imbalance arising from the uneven presence of surgical instruments or activities during surgical procedures. This paper proposes to address these two problems with a multimodal large language model (LLM) and an adaptive weight assignment methodology. We first develop a new multi-teacher CL framework that leverages a multimodal LLM as the additional teacher. The strong generalization ability of the LLM can bridge the knowledge gap when domain shifts and data imbalances occur. We then put forth a novel data processing method that transforms complex LLM embeddings into logits compatible with our CL framework. We further design an adaptive weight assignment approach that balances the generalization ability of the LLM and the domain expertise of the old CL model. We construct a new dataset for surgical VQA tasks, providing valuable data resources for future research. Extensive experimental results on three datasets demonstrate the superiority of our method to other advanced CL models.
UniST: Towards Unifying Saliency Transformer for Video Saliency Prediction and Detection
Sep 15, 2023Video saliency prediction and detection are thriving research domains that enable computers to simulate the distribution of visual attention akin to how humans perceiving dynamic scenes. While many approaches have crafted task-specific training paradigms for either video saliency prediction or video salient object detection tasks, few attention has been devoted to devising a generalized saliency modeling framework that seamlessly bridges both these distinct tasks. In this study, we introduce the Unified Saliency Transformer (UniST) framework, which comprehensively utilizes the essential attributes of video saliency prediction and video salient object detection. In addition to extracting representations of frame sequences, a saliency-aware transformer is designed to learn the spatio-temporal representations at progressively increased resolutions, while incorporating effective cross-scale saliency information to produce a robust representation. Furthermore, a task-specific decoder is proposed to perform the final prediction for each task. To the best of our knowledge, this is the first work that explores designing a transformer structure for both saliency modeling tasks. Convincible experiments demonstrate that the proposed UniST achieves superior performance across seven challenging benchmarks for two tasks, and significantly outperforms the other state-of-the-art methods.
Induction Network: Audio-Visual Modality Gap-Bridging for Self-Supervised Sound Source Localization
Aug 09, 2023



Self-supervised sound source localization is usually challenged by the modality inconsistency. In recent studies, contrastive learning based strategies have shown promising to establish such a consistent correspondence between audio and sound sources in visual scenarios. Unfortunately, the insufficient attention to the heterogeneity influence in the different modality features still limits this scheme to be further improved, which also becomes the motivation of our work. In this study, an Induction Network is proposed to bridge the modality gap more effectively. By decoupling the gradients of visual and audio modalities, the discriminative visual representations of sound sources can be learned with the designed Induction Vector in a bootstrap manner, which also enables the audio modality to be aligned with the visual modality consistently. In addition to a visual weighted contrastive loss, an adaptive threshold selection strategy is introduced to enhance the robustness of the Induction Network. Substantial experiments conducted on SoundNet-Flickr and VGG-Sound Source datasets have demonstrated a superior performance compared to other state-of-the-art works in different challenging scenarios. The code is available at https://github.com/Tahy1/AVIN
Selective clustering ensemble based on kappa and F-score
Apr 23, 2022
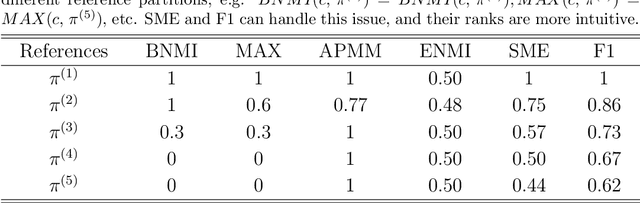
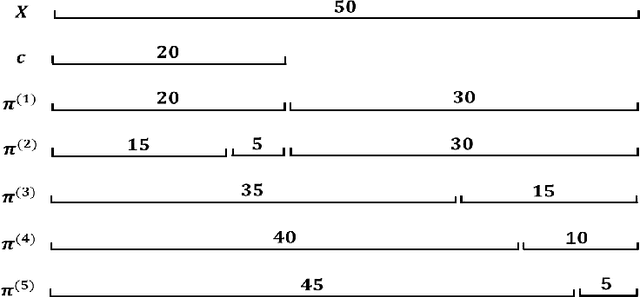
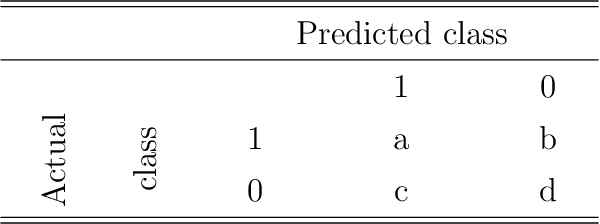
Clustering ensemble has an impressive performance in improving the accuracy and robustness of partition results and has received much attention in recent years. Selective clustering ensemble (SCE) can further improve the ensemble performance by selecting base partitions or clusters in according to diversity and stability. However, there is a conflict between diversity and stability, and how to make the trade-off between the two is challenging. The key here is how to evaluate the quality of the base partitions and clusters. In this paper, we propose a new evaluation method for partitions and clusters using kappa and F-score, leading to a new SCE method, which uses kappa to select informative base partitions and uses F-score to weight clusters based on stability. The effectiveness and efficiency of the proposed method is empirically validated over real datasets.